Antifragileは、タレブが2012年に書いた本で、社会経済学の分野の内容ですが、他の分野においてもその考え方は有効ではないかと多くの記事や論文があります。ソフトウェア開発やアーキテクチャにどういう影響を与えていきそうかを考えてみます。

アンチフラジャイルの投資的側面
もともとはアンチフラジャイルとは、相場が動いたときに悪い方に転んでも損失はそこそこに抑えられるが、良い方に転ぶと指数関数的に大きな利益を得るということを意味します。
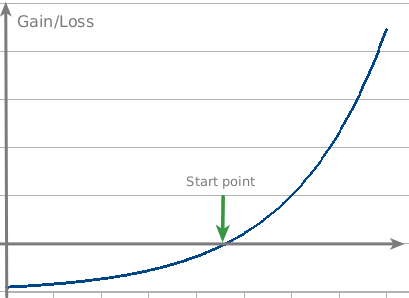
アンチフラジャイルな投資方法としては、プットオプションが鍵と言われています。
私もこの辺りは門外漢なので、記事中の例を引用すると、通常時に50ドルのシティバンクの株式を3ドルで売る権利(プットオプション)を10セントで買います。これはシティバンク株が3ドル以下になることなど、ほとんどありえないと考えられるので安く買えるわけです。ところが、リーマンショックの後、シティバンク株は実際に1ドルを切るくらい安くなってしまったので、当時との価格差で10セントが20倍以上の価値をもつことになり、世間が大損している間にタレブのファンドは大きなリターンを稼いだといわれています。
こういった、ありえないと考えられている大きな変化をタレブは"ブラック・スワン"と呼び、アナリストや世間の人々はこのブラック・スワンの発生確率を、実際よりも低く見積り軽視するとしています。したがって、より大きな利益を得やすいということです。
アンチフラジャイルのソフトウェア開発への適用
アンチフラジャイルをソフトウェアにも適用するアイデアは、Building MicroservicesやInfrastracture as Codeといったベストセラーの書籍にも登場します。双方、ThoughtWorks社の方々の著作なので、アンチフラジャイルがThoughtWorksテクノロジーレーダに登場しブレイクするのも時間の問題な気がします。


先日、Red Hatのディベロッパーズブログで、From Fragile to Antifragile Softwareという記事が投稿されているので、そこでの整理のされ方をもとに、フラジャイルからアンチフラジャイルへ、ソフトウェアの開発プロセス・アーキテクチャの側面からどういう変化があるのか当てはめてみます。
フラジャイル Fragile
大きな変化に対して損失の大きなものは"フラジャイル"です。
後戻りの計画・その分の予算確保していないウォーターフォールプロジェクトはフラジャイルです。変化に対して、対応するための費用がかさみ当初予算を際限なくオーバーしていくさまはフラジャイルの典型そのものです。
プロビジョニングが十分でないシステムもフラジャイルです。岡崎市立中央図書館のシステムは、たかだか30分で2000ページアクセスするクローラーによって、システム全体がダウンする設計だったのでフラジャイルといえます。
プログラミングレベルの話だと、例外の取り扱いが十分でないものはフラジャイルになりえます。
ちょっとフォーマットのおかしいデータが入ってきたら、バッチが異常終了したり、データ不整合が発生したりしてしまうのはフラジャイルなプログラムといえます。
受託開発において、フラジャイルには十分に注意を払う必要があります。顧客とのやり取りの中で、フラジャイルな設計・プロジェクト運営をなかば余儀なくされることがあっても、その意思決定が一般的にいって、"ほとんど故意"と受けとられると、万一訴訟沙汰になったときに負けてしまうことがあるためです。
https://gist.github.com/koyhoge/1ee02b354968e8910604
ロバスト Robust
変化に対して、十分強い仕組みがロバストです。先のフラジャイルの例の裏返しは、ロバストになります。
- よく計画されたウォーターフォールの開発プロジェクト
- 急激なアクセス増や異常なデータファイルに対しても、安全に処理できるアプリケーション
- あらゆる例外を適切にハンドリング出来ているコード
ロバストが難しいのは、起こりうる変化を十分に予測し、対策を打ってあることが前提になることです。
ここでハマりやすい落とし穴は、だからといってろくな計画や設計することなしに「とにかく適応型プロセスにしよう」とか「レジリエントなアーキテクチャにしよう」というのは、フラジャイルになります。完璧なロバストネスなどといったものは存在しない、としても未来の予測は必要です。
レジリエント Resilient
レジリエントは変化に適応していくことを意味します。大きな変化に対し、一時的にシステムのパフォーマンスを落としてもすぐに復旧できることがレジリエントです。
アジャイルな開発プロセスは、変化を受け入れ適応していくことが哲学に組み込まれているのでレジリエントといえます。

https://becomingagile.wordpress.com/2014/09/19/cost-of-change/
クラウドのデザインパターンはレジリエントを体現したものが多いです。
サーキットブレーカーはシステムの変化・異常事態に適応し、被害を拡大させないふるまいをさせるものです。

Erlang/OTPの設計思想である、Let It Crashは、予期しない例外を(Erlangでいうところの)プロセスをクラッシュさせて復旧させることによって、他への影響を最小化するというやり方でレジリエントな仕組みを担保しています。
また、Akkaのマスターがダウンしても、ワーカーがマスターに昇格するようなアーキテクチャもレジリエントの例です。
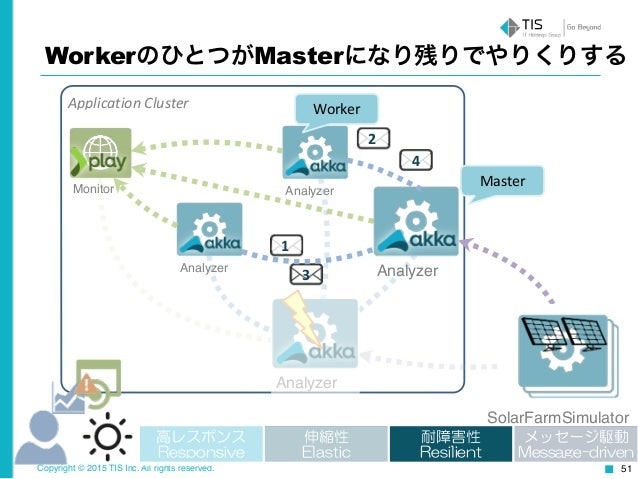
アンチフラジャイル Antifragile
アンチフラジャイルは変化に対してゲインを得ます。外から意図的に負荷をかけることによって、システムを強くすることもよくおこなわれます。
特定世代にとって、アンチフラジャイルなシステムの一番分かりやすいメタファはサイヤ人です。瀕死の状態から回復すると戦闘力が増す、そんなイメージです。意図的に瀕死状態になって急激に戦闘力を増すナメック星でのベジータのエピソードは、NetflixのFail as a Serviceそのものです。
DevOps
DevOpsそのものがアンチフラジャイルという訳ではありませんが、アンチフラジャイルのためのキーファクターとされ、よくセットで出てきます。

DevOpsの継続的デリバリは、継続的にシステムを強化していくアンチフラジャイルに必要不可欠であり、DevOpsのカルチャーとしても、失敗を恐れずにデプロイしていくことが、アンチフラジャイルの失敗を愛する精神とオーバーラップします。
Chaos Engineering
Netflixでは、本番環境で意図的に障害を起こし、その影響を観測する仕組みを作っています。一世代前のSimian ArmyはOSSとして公開されているので、試してみることができます。

意図的にマイクロサービス間にレイテンシーを発生させたり、特定のインスタンスをダウンさせたり様々な本番障害を注入し、その影響をモニタリングできます。
Netflixの中の人の最新のプレゼンBetter than Resilient: AntifragileがQCon NYでなされたようですがスライドはまだ見つかりません。
こういった障害を意図的に起こすことはChaos Engineeringとして広まりつつあり、http://principlesofchaos.org/ のサイトでは以下のような原則が定義されています。
- 安定した状態でシステムの挙動について仮説を立てる
- 現実世界のイベントに変化を加えてみる
- 本番環境で実験をする
- 継続的に実行するために実験を自動化する
アンチフラジャイルの自動化
アンチフラジャイル思考を日本的に言うと「失敗から学ぶ」という重要だけれども陳腐な印象になってしまいがちですが、私は学ぶ主体が人間ではなく機械になっていくと予想しています。
実際にそのような仕組みの研究もされているようです(Toward Antifragile Cloud Computing Infrastructures)。
Antifragile JVMコンテナ
そこで、自動的にJVMのアンチフラジャイル化をおこなってくれるJVMコンテナfalchionを作りました。
もともとは、JDK9で対応予定のSO_REUSEPORTを使って、1台のマシンでも無停止デプロイが可能な仕組みを作ったところから始まるのですが…
http://www.slideshare.net/kawasima/java-62447735

仕組みは単純で、複数のJVMプロセスが同一ポートをListenし、それらの管理プロセスをコンテナと呼んでいるだけです。先のとおりSO_REUSEPORTを使っているので、WindowsなどのREUSEPORTがサポートされないOSでは使えません。

Falhionコンテナでは、Web APIを用意していて、各JVMの状態を取得できたり、JVMを再起動しアプリケーションの変更を無停止で反映できたりするのがウリです。

JVMのモニタリング機能では、jstatやJMXを使ったJVMの状態を取得できます。
これらを使ってオートチューニングの機能を実装しています。
% java -jar falchion-container/target/falchion-container-0.1.0-SNAPSHOT.jar net.unit8.falchion.example.jetty9.Main -cp falchion-example-jetty9/target/classes:falchion-example-jetty9/target/lib/* -m GCUTIL_JSTAT METRICS_JMX -p 3 --auto-tuning
こんな感じで、--auto-tuningオプションを付けて起動すると、初期値がランダムにふられ、3つのJVMが起動します。
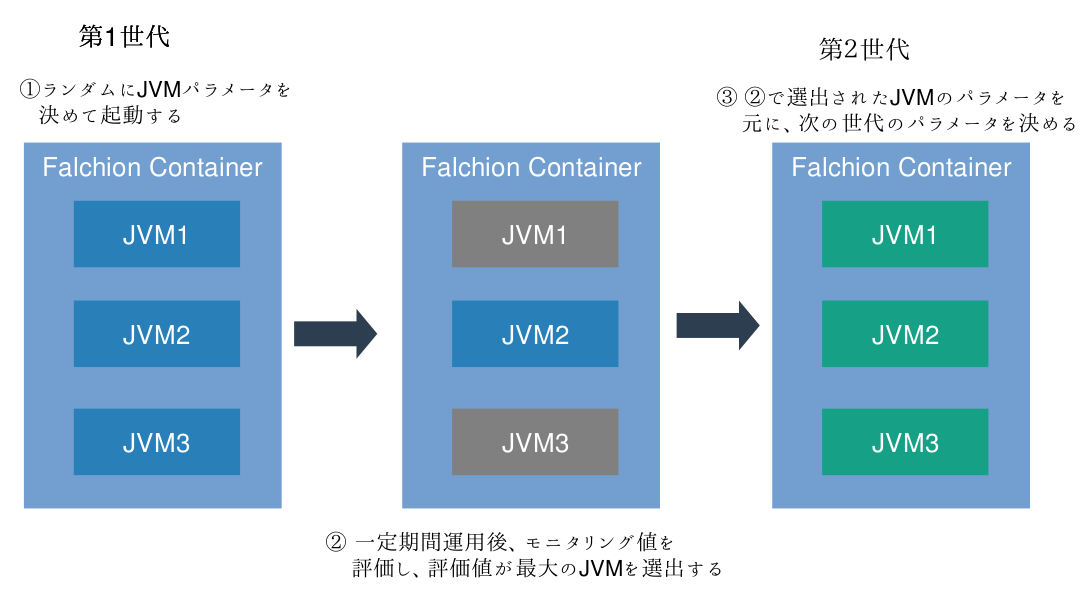
コンテナのリフレッシュコマンドを呼ぶと、JVMが順次再起動され、もっとも評価の高い(例えばFull GC回数が一番少ない)JVMのパラメータが、次の世代のシードになります。これを繰り返すだけで、徐々にアプリケーション特性に応じて最適化されたJVMオプションが手に入ることになります。
現段階では、本番でこのオートチューニングを使う想定はしておらず、性能テスト中に使うイメージで作っていますが、本番運用中に使える仕組みとして成長させていきたいと考えています。
JDK9がリリースされたあかつきには、ぜひアンチフラジャイルなJVM運用を体験していただければと思います。
まとめ
『アンチフラジャイル』は静かなるブームが続いていますが、まだ主要メディアで派手に取り上げられるには至っていません。が、ThoughtWorks社やNetflix社が推していることから、いずれ大ブームがくると思います。
そのときのために、どういう形態のアンチフラジャイルが実現できそうか、継続して考えていきたいと思います。