アップロードと比較するとタイトルは釣り気味なのですが、ダウンロードにまつわるパターンをまとめます。
ふつうのダウンロード
アップロードほど考えなきゃいけないことは多くないですが、ハマりポイントはいくつかあります。
ファイル名
何も対策せず日本語をファイル名にすると、当然のように化けます。
Content-Disposition: attachment; filename="(ファイル名)"
でファイル名を指定しますが、FirefoxとIE、Chromeなどのその他ブラウザで対策が異なります。
Content-Type: xxx/xxx; charset=utf-8
Content-Disposition: attachment; filename="(UTF-8でURLエンコードした文字列)"
FirefoxはMIME Bエンコードするのが伝統的仕様のようです。
Content-Type: xxx/xxx; charset=utf-8
Content-Disposition: attachment; filename="(MIME-Bエンコード)"
UserAgentでGeckoが入っているかどうかで、URLエンコードするか、MIME Bエンコードするかの処理の分岐を入れます。
強制ダウンロード
ブラウザの中で開かず、ファイル保存ダイアログを出したいという要件がよくあります。
HTML5のdownload属性が手軽なのですが、こちら( http://mamewaza.com/support/blog/force-download.html )の検証結果によると、IEメインのSIerのお客さま向けには、
Content-Type: application/force-download
のヘッダを送出した方がよさそうです。
ファイル経由
セキュリティ的にファイルに一時的に書くのは許されない、などののっぴきならない理由がなければ、ファイルを一度通した方が無難です。
特に、SQLで取得した結果をCSVなどでクライアントに送る場合、クライアントに送信終わるまで、データベースの接続を掴みっぱなしになります。SO_SNDBUFがあまり大きくないととネットワークが詰まって、DBコネクションが枯渇するトリガを引く恐れがあります。
ファイルに書くのはもう1つメリットがあります。Content-Lengthヘッダを付けれるということです。そうすると何%ダウンロードできたかプログレスがブラウザ側で表示されるようになります。
レジューム
Wi-Fiやモバイル回線で、接続断のおそれがある場合は、ダウンロードを再開できるようにRangeヘッダへの対応を検討します。このレジュームに対応するには前述のファイル経由になっていないといけません。
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Length: xxxx
と、最初のレスポンスにAccept-Rangeヘッダを与えます。ブラウザ側でダウンロードを中断し、ユーザによって再開操作をしたときには、Rangeヘッダが飛んできます。
Range: bytes=21010-47021
これを受けて、ファイルダウンロードアプリ側で、206のレスポンスで、部分送信します。
HTTP/1.1 206 Partial Content
Date: Wed, 15 Nov 1995 06:25:24 GMT
Last-Modified: Wed, 15 Nov 1995 04:58:08 GMT
Content-Range: bytes 21010-47021/47022
Content-Length: 26012
Content-Type: application/force-download
ただし、このRangeヘッダは以前話題になったApache Killerの対策として、前段のApacheで削除されている可能性もあるので、ご利用の際は設定の確認が必要です。
トークンベース認可 & キャッシュ対策
レジュームや次に示すような非同期ダウンロードにする場合、キャッシュ対策を考えた場合、ファイルダウンロードリクエストごとに一意なURLを発行するのが扱いが簡単です。
GET http://hoge/download
HTTP/1.1 302 Found
Location: http://hoge/download/3c5b7e1235
一意なURLの作り方はトークンベース認可のやり方を使えば、セキュアでダウンロードファイルに有効期限も持たせることができるのでおすすめです。
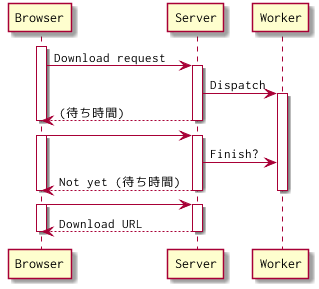
非同期ダウンロード
ダウンロードさせるファイルが、オンデマンドで作る必要があり、かつ時間がかかる(10秒以上)場合は、この非同期ダウンロードを考えます。
リクエストを受け付けて、準備ができたらダウンロードを開始する、ってやつです。
電子書籍ではPDFに購入者の名前を入れて、ダウンロードできる状態になる、というものが多いですが、こういうのは非同期ダウンロードで設計されているものが多いです。
極端に時間がかかる場合は、完了の通知を別途Eメールなどで送る必要がありますが、基本的にはリクエストだけ送っておいて、ブラウザを待たせ、準備ができたらダウンロードが開始されるというパターンが多いでしょう。
ここで考えなきゃいけないのは、ブラウザからみると、いつファイル準備出来送信し始めるのかわからない、ということです。
ブラウザからリクエストを受けると、ダウンロード生成のリクエストをキューイングします。キューに入っているリクエスト数と、生成ワーカースレッド数と、平均処理時間から、M/M/sモデルとして待ち時間を算出します。
待ち時間をブラウザに返します。ブラウザ側ではダウンロードまでの秒数カウントダウンを表示し、その待ち時間分待ったら、ダウンロード可能な状態かどうか確認のリクエストを投げます。まだダウンロードファイルが出来ていなければ、再度待ち時間を計算しなおし、ブラウザに返します。

ダウンロードファイルができていれば、ダウンロードURLにリダイレクトします。
まとめ
オンデマンドで時間のかかるファイルを生成し、ダウンロードさせる、という要件は年々増えてきている気がします。そんなときでも、非同期ダウンロードにしておけば、多い日も安心ですね。
非同期ダウンロードのExampleです。
https://github.com/kawasima/ultimate-downloading (Clojure)