1.はじめに
自社のデータセンターにあるファイルサーバの容量拡張などがきっかけで、
オンプレからAWSにファイルサーバを移行させたい、というケースは結構あると思います。
で、例外なく考慮しなければならないのが「冗長構成」です。
もうファイルサーバなんか持たなくていい、S3で行くんだ!!!
という対応もあるかと思いますが、
現行運用を鑑みるとやっぱりEC2立てて構築することが多いと思います。
じゃ、クラスタどうやって組むか???
今回、諸々の理由でCLUSTERPROを利用する機会があったのですが、ハマりポイントがあったので記録しておきます。
2.CLUSTERPROによる2つの実現方式(from 公式ガイド(?))
CLUSTERPROの構築ガイドでは、次の2つの方式が記述されています。
2-1:EIP付替え方式
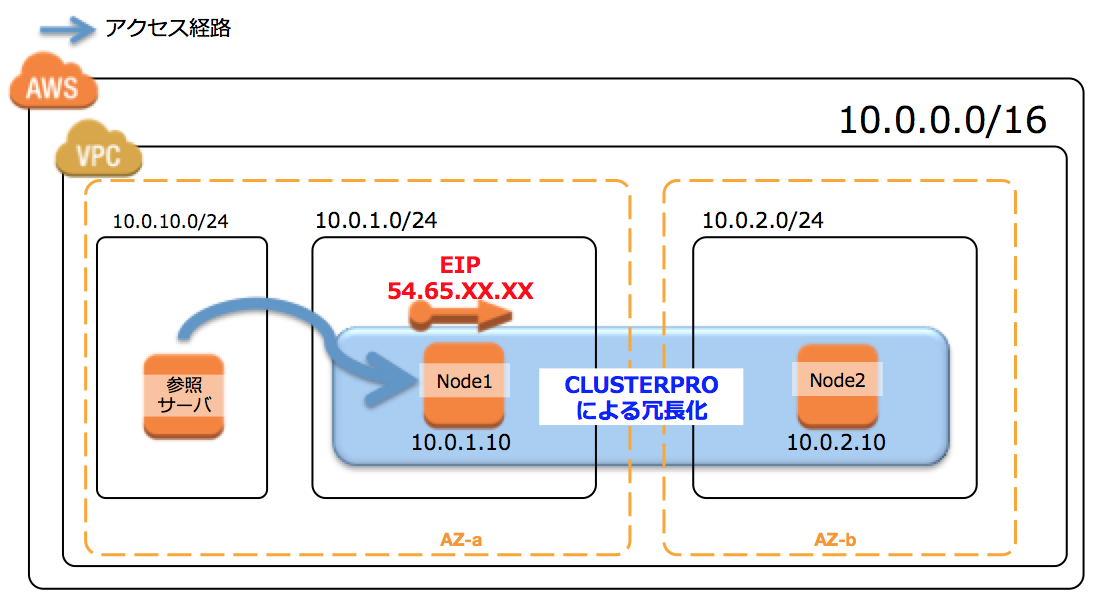
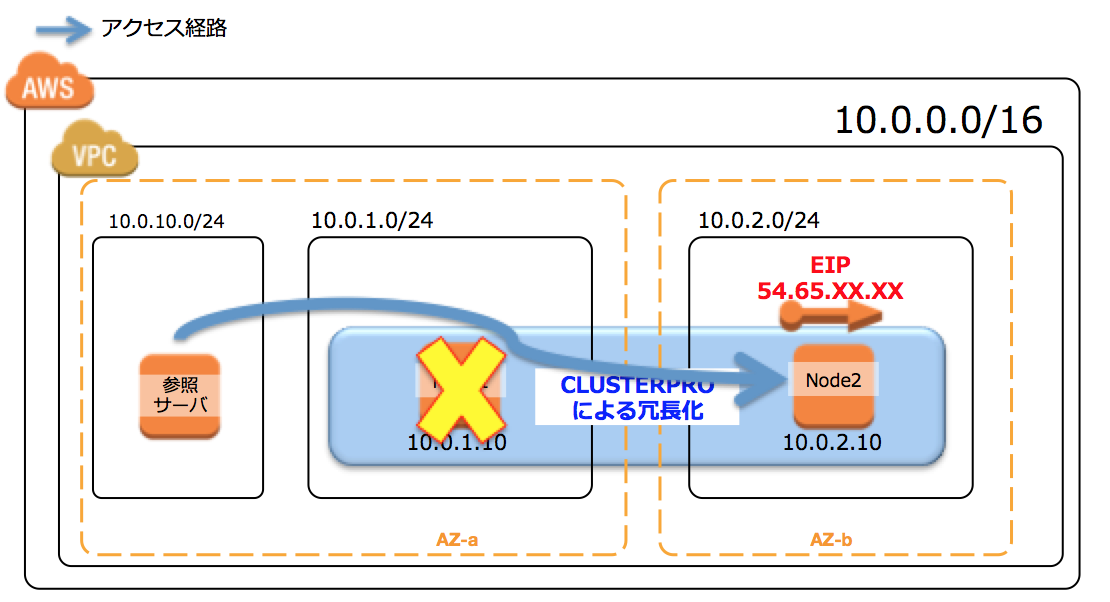
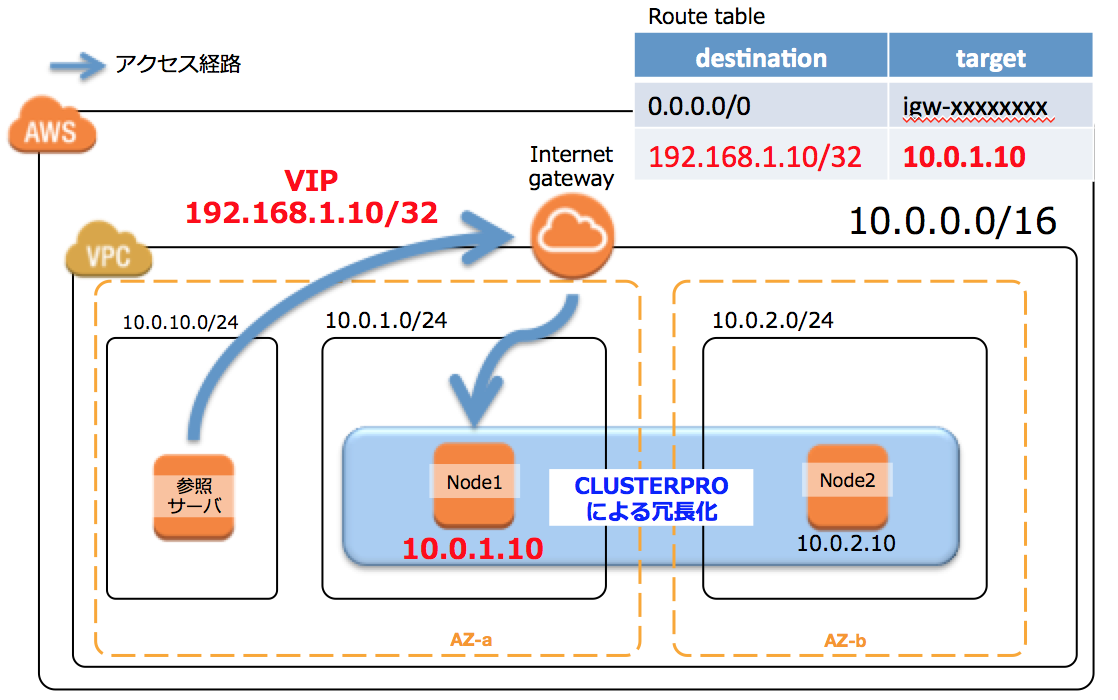
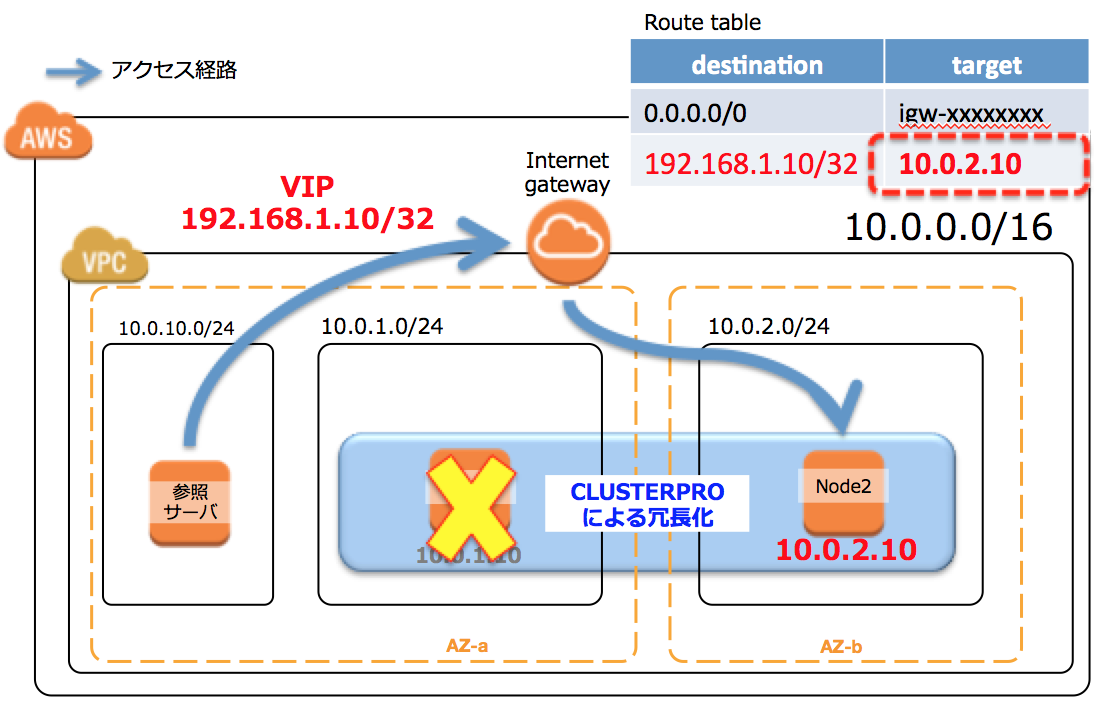
2-2:VIPルーティング変更方式。
VPC範囲外の仮想的なダミーIPアドレスを決め、そこに対する通信をRoute tableでルーティング(ループバック)させます。
2-1は、(Security groupで制御できるとはいえ)外部からの通信がreachできてしまうので、
社内のファイルサーバのような用途で使う場合は少し抵抗があるお客様が多いと思います。
ということで2-2の構成を採用するケースが多いのかな、と思うのですが、、、。
この構成、、、ちょっと難ありでした。。。
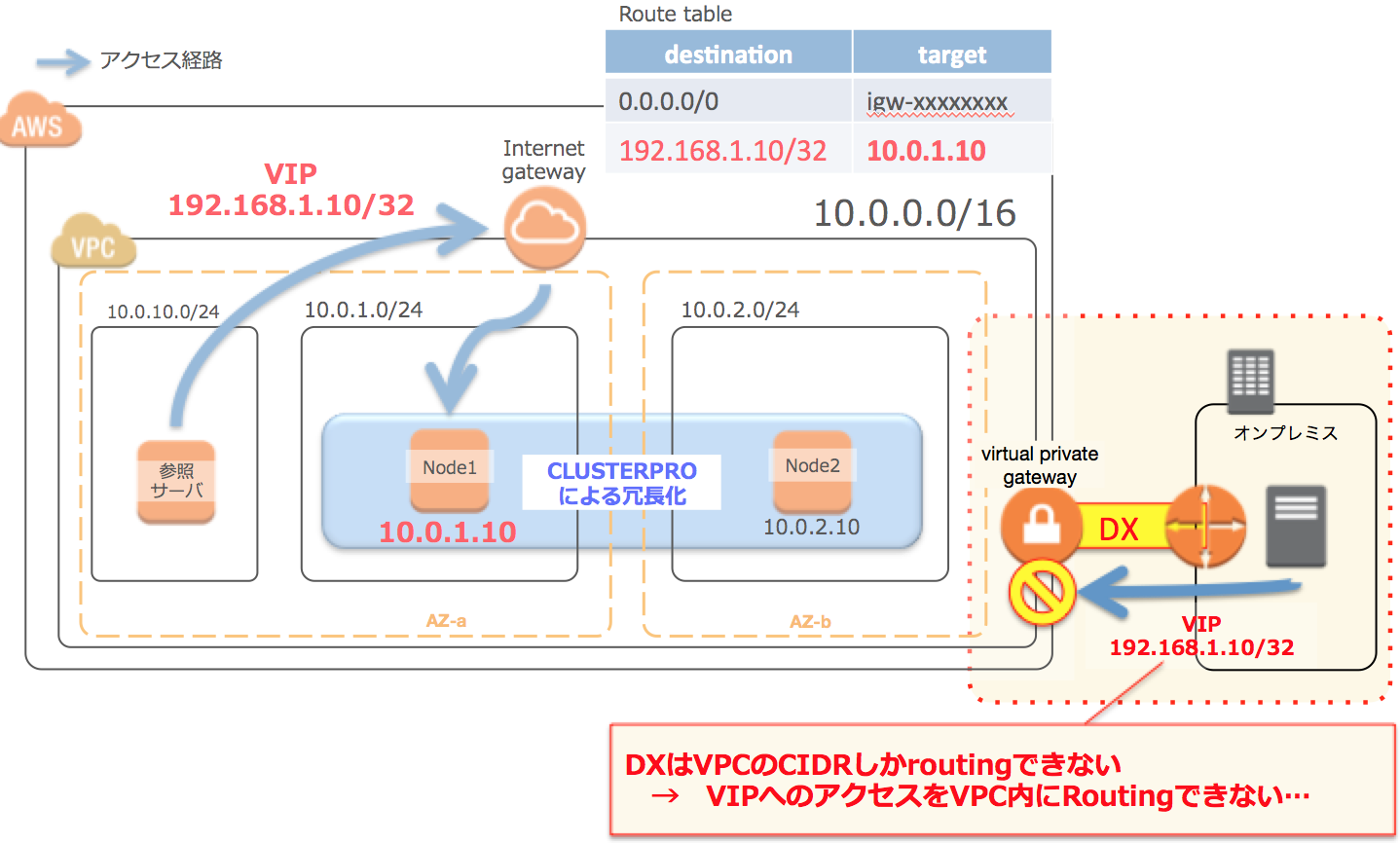
3.DXを利用している場合、オンプレ側からアクセスできない
VIP方式の場合、AWS内だけで使うなら問題ないのですが、
オンプレとAWSをDirect Connectで接続していて、オンプレ側からもファイルサーバに接続したい場合、
通信することができません。
オンプレ側のルータで仮想IPへの通信をAWS側に向けたとしても、
DXの受け口側(Virtual Interface側)がVPCレンジ外への通信をルーティングすることができないからです(AWS仕様)。
4.VIPルーティング変更方式以外でfailoverする方法
Route tableをいじる以外でfailoverを実現する方法がないか、考えてみました。
4-1:セカンダリIP付替え方式
クラスタのアクティブインスタンス側にセカンダリIPをアサインし、クライアントはセカンダリIPに向かってアクセスする方式です。障害時には、スタンバイ側インスタンスに同じセカンダリIPをアサインしてやることで、failoverすることができます。
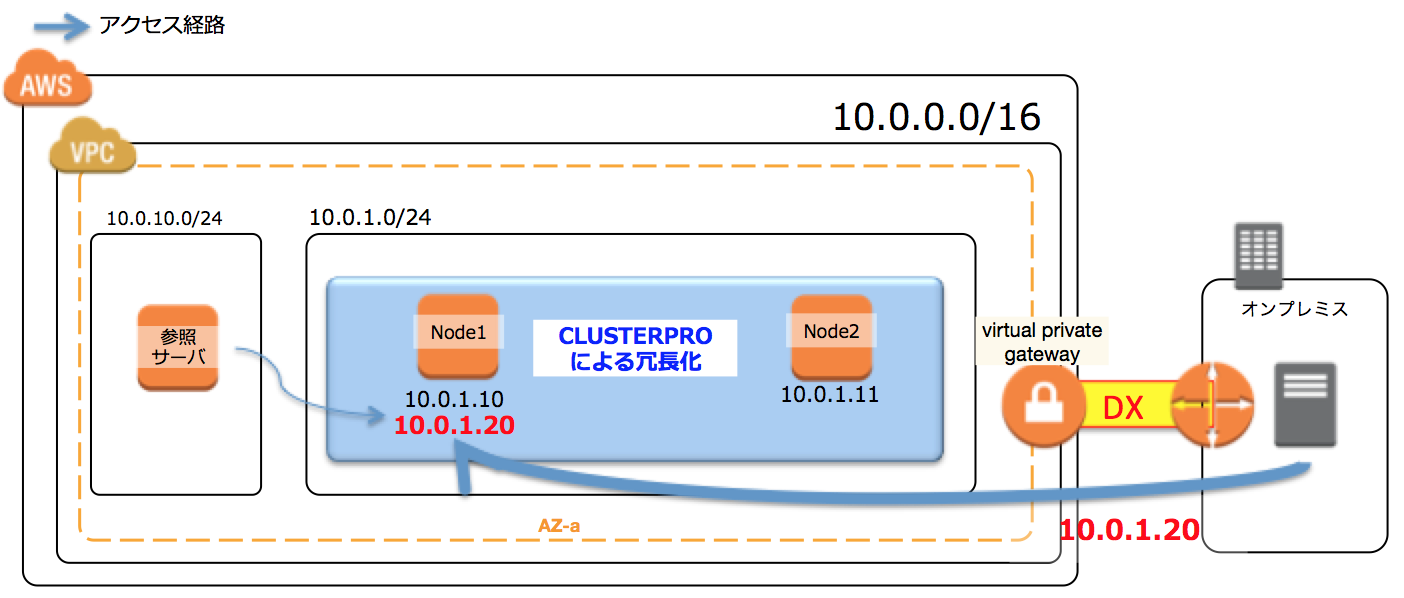
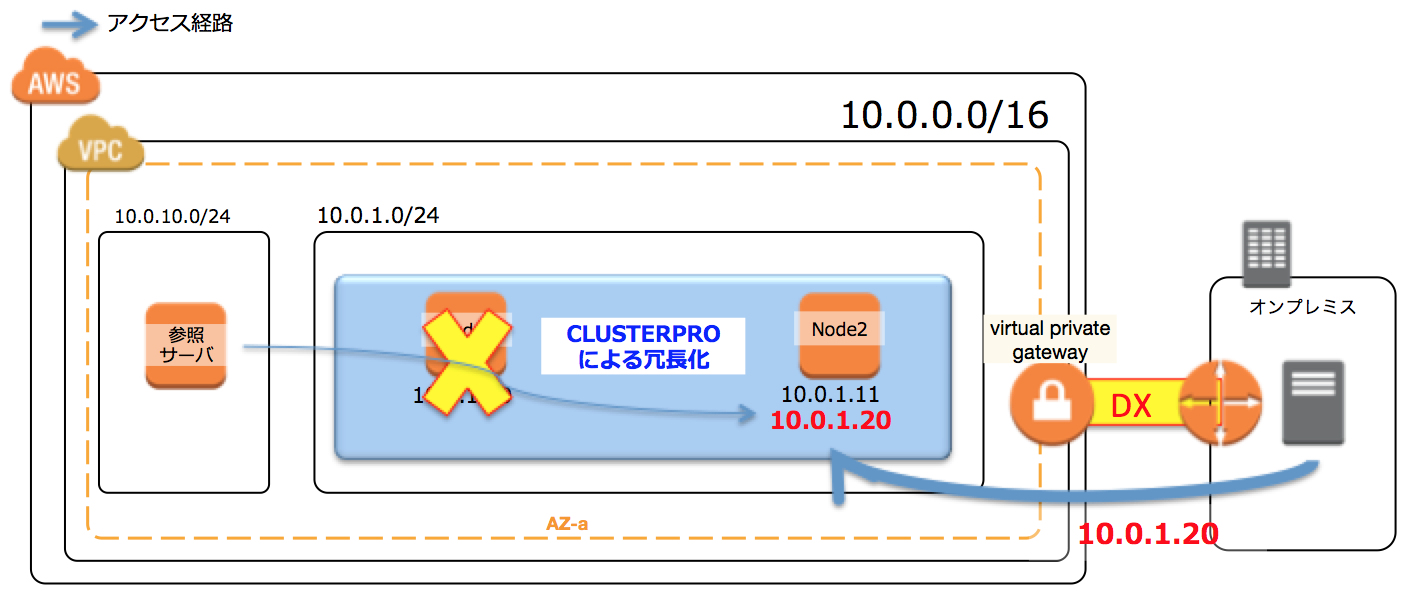
ただし、この構成の課題はMaulti-AZで構成することができなくなってしまうので、注意が必要です。
セカンダリIPアドレスはプライマリIPと同じセグメントの値しか指定することができないので、同じセカンダリIPを付け替えるようにするには、2台のインスタンスを同じサブネット(=同じAZ)に配置しなければならないからです。
ちなみに、切換えスクリプトはこんな感じになりました。
それぞれのインスタンスに配置し、UPさせるインスタンスは引数をstartで、ダウンさせる方はstopで実行します。
# !/bin/bash
# カレントリージョン取得
CURRENT_REGION=`curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone | sed -e s/[^0-9]$//g`
# 設定するPrivate-ip定義
PRIVATE_IP="xxx.xxx.xxx.xxx"
# 設定対象のENI-ID定義
ENI_ID="eni-xxxxxxxx"
start(){
#セカンダリPrivate-ip設定
aws --region ${CURRENT_REGION} ec2 assign-private-ip-addresses --network-interface-id ${ENI_ID} --private-ip-addresses ${PRIVATE_IP}
#セカンダリIPのethを有効化
ifconfig eth0:0 ${PRIVATE_IP} up
exit 0
}
stop(){
#セカンダリPrivate-ip削除
aws --region ${CURRENT_REGION} ec2 unassign-private-ip-addresses --network-interface-id ${ENI_ID} --private-ip-addresses ${PRIVATE_IP}
#セカンダリIPのethを無効化
ifconfig eth0:0 ${PRIVATE_IP} down
exit 0
}
case "$1" in
start)
start
;;
stop)
stop
;;
*) break ;;
esac
4-2:DNSレコード書換え方式
クライアントは、IPではなくDNS名でアクセスさせます。障害発生時はDNSサーバのAレコードを書き換えてやることで、failoverさせます(図の右下の部分です)。
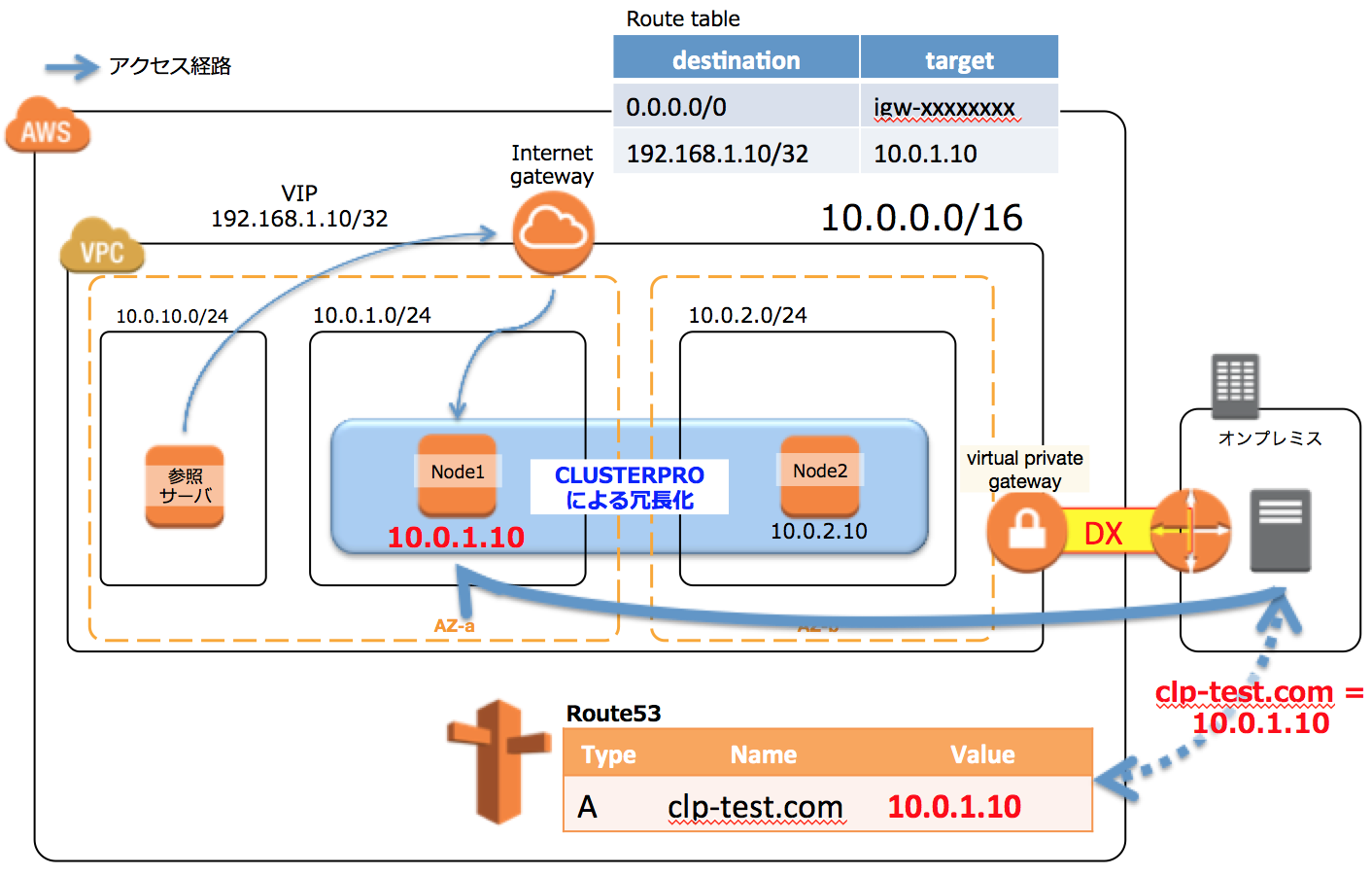
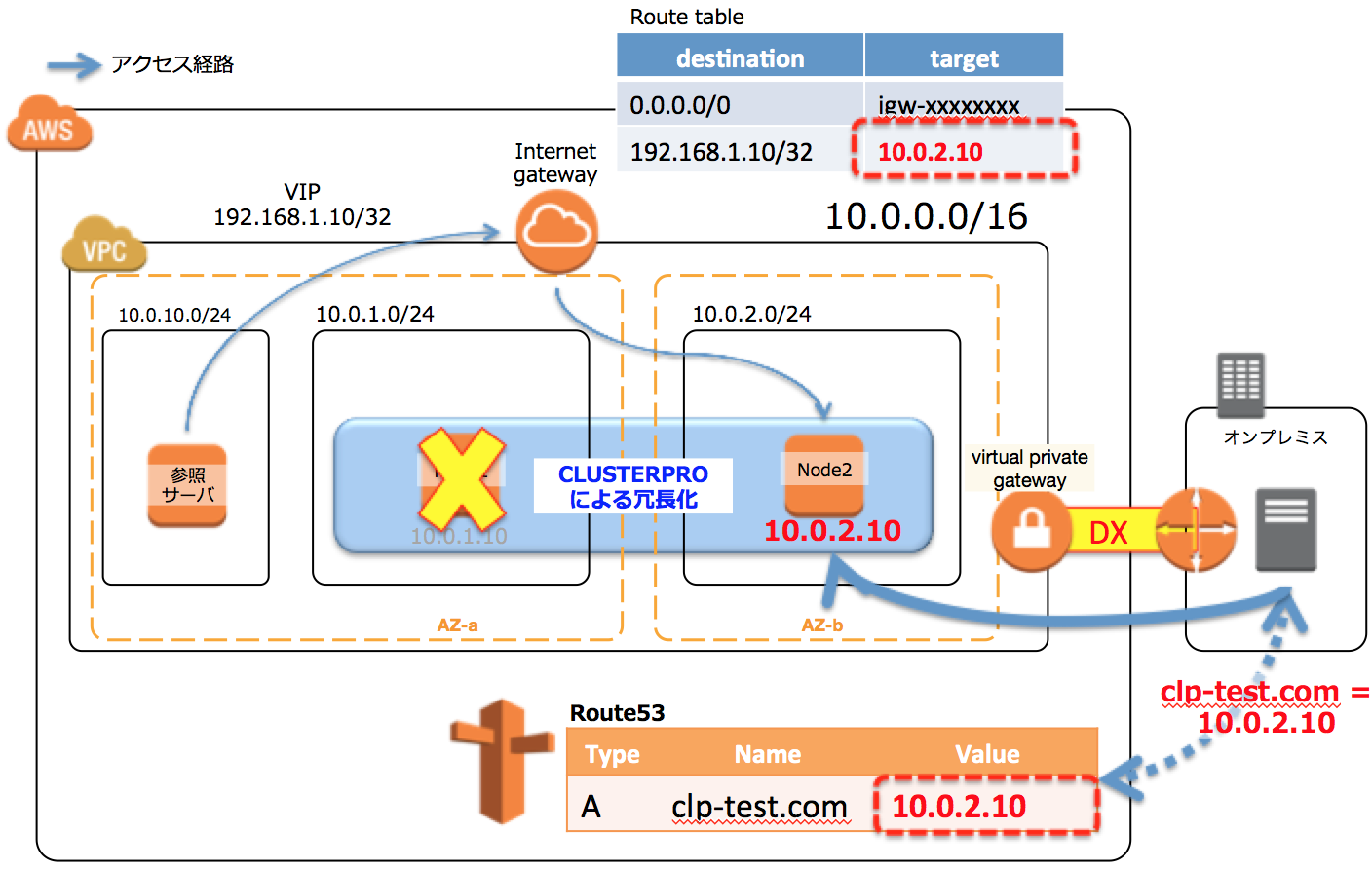
Route53をつかえばAPIコールで動的にレコードを変更できるで、なかなかよい方法ですね。レコードの値を書き換えるだけなので同じセグメントである必要もない、つまり、この構成であればMulti-AZ構成も実現できます。ただ、オンプレからRoute53参照させるためにはパブリックRoute53にしなければならない(プライベートRoute53はDX経由であってもオンプレ側からは参照できない)ので、誰でも名前解決はできてしまうのはちょっと気持ち悪いと言えば気持ち悪いですね(プライベートIPが返ってくるように設定しているので、外からはリーチできないですが)。
また、TTLにもとづくClientキャッシュが残ってしまうのも、ちょっと気持ち悪いです。。。
※0にしておけばよいと言えば良いですが、、、サイトによってはクエリリクエスト回数が気になる…
Route53切換えスクリプトも一応のせておきます。JSONを定義しておいて、実行時に読み込む形にしています。
※ルートテーブルを切替えるスクリプトは省略。
# !/bin/bash
# カレントリージョン取得
CURRENT_REGION=`curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone | sed -e s/[^0-9]$//g`
# 設定対象のroute53のhosted-zone-id
HOSTED_ZONE_ID="ZXXXXXXXXXXXXXX"
# 更新するレコード情報定義ファイルへのパス
CHANGE_BATCH="file://.argument.json"
# Route53レコード更新
aws route53 change-resource-record-sets --region ${CURRENT_REGION} --hosted-zone-id ${HOSTED_ZONE_ID} --change-batch ${CHANGE_BATCH}
exit 0
{
"Comment": "failover request for File-server by CLUSTERPRO",
"Changes": [
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "clp-test.com.",
"Type": "A",
"TTL": 0,
"ResourceRecords": [{ "Value": "10.0.2.10" }]
}
}
]
}
5.まとめ
それぞれメリット・デメリットあると思いますので、
要件に合わせて選択していきたいと思います。
この他にいいやり方あるよ、という方いらっしゃいましたら教えてください!!!!
※その他私的メモ
CLUSTERPROのdefaultのfailoverスクリプト(Route table切換え)は、awsCLIとは別のapitoolsを使ってfailoverするらしいので、それをインストールする必要があります(configやスクリプトもこれありきで提供されている。。。)
ま、CLIで自分で書けばいいんですけど、一応。
■apitools環境構築参考URL
http://blog.jicoman.info/2014/04/ec2-api-tools-install/
また、CLUSTERPROはディスクの先頭20MBを管理領域として使うので、fdiskでパーティションを切ってあげないと行けない。
切り方は以下のページが参考にしました。
https://www.express.nec.co.jp/linux/distributions/knowledge/system/fdisk.html