はじめに
AVXで導入されたYMMレジスタは256bitで、64bitで表現される倍精度実数を4つ同時に扱うことができる。で、単にそのまま足したり引いたりするだけなら良いのだが、たまに要素を入れ替えたりする必要が出てくる。この時、二つのレジスタを混ぜたり、レジスタ内の要素を入れ替えたりするシャッフル系の命令が分かりづらかったので、自分用に以下のようなチートシートを作ってみた。
SIMDのシャッフルは、わかってしまえば簡単なのだが、最初はインテルのマニュアルの擬似コードみても何がどうなってるかわかりづらいと思う(少なくとも僕はそうだった)。なので、それぞれの命令の動作と使用例を書いてみる。以下では倍精度実数に話を限定する。
AVXの使い方
値の与え方
x86は、AVXから256bitをサポートする。対応するレジスタはYMMで、16本使える。YMMレジスタの下位128bitは、同じ番号のXMMレジスタと共用。AVX命令を使うには、immintrin.hをインクルードする。また、YMMレジスタに対応する組み込み型は__m256d。__m256dの値をプリントする関数を作っておくとデバッグ時に便利。
void
print256d(__m256d x){
printf("%f %f %f %f\n",x[3],x[2],x[1],x[0]);
}
YMMレジスタに値を入れる方法は、4つの値を別々にセットする方法と、メモリ上の連続する4つのデータを一度に取ってくる方法の二つがある。まず、4つの値をセットするには_mm256_set_pdを使う。
__m256d s1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
print256d(s1);
// 3.000000 2.000000 1.000000 0.000000
ここで、_mm256_set_pdの第四引数が、YMMレジスタの一番下位にセットされることに注意。MSBを左に書く慣習から、左が上位、右が下位になるようにこういう仕様なんだと思う。_mm256_set_pdに対応する命令はなく、これをコンパイルするとXMMレジスタの上位と下位にデータをロードし、二つのXMMレジスタをくっつけて一つのYMMレジスタを作るようなコードを吐く(なので遅い)。
メモリ上の連続する4つのデータを取ってくるには_mm256_load_pdを使う。このメモリは256bitでアラインされていなければならない。そうでないと実行時にSegmentation Faultが起きる。
__attribute__((aligned(32))) double x[] = {0.0, 1.0, 2.0, 3.0};
__m256d s2 = _mm256_load_pd(x);
print256d(s2);
// 3.000000 2.000000 1.000000 0.000000
上記の例のように配列からロードすると、配列の若いインデックスからYMMの下位に積まれるので、配列の初期化子リストの順番と逆順になることに注意。
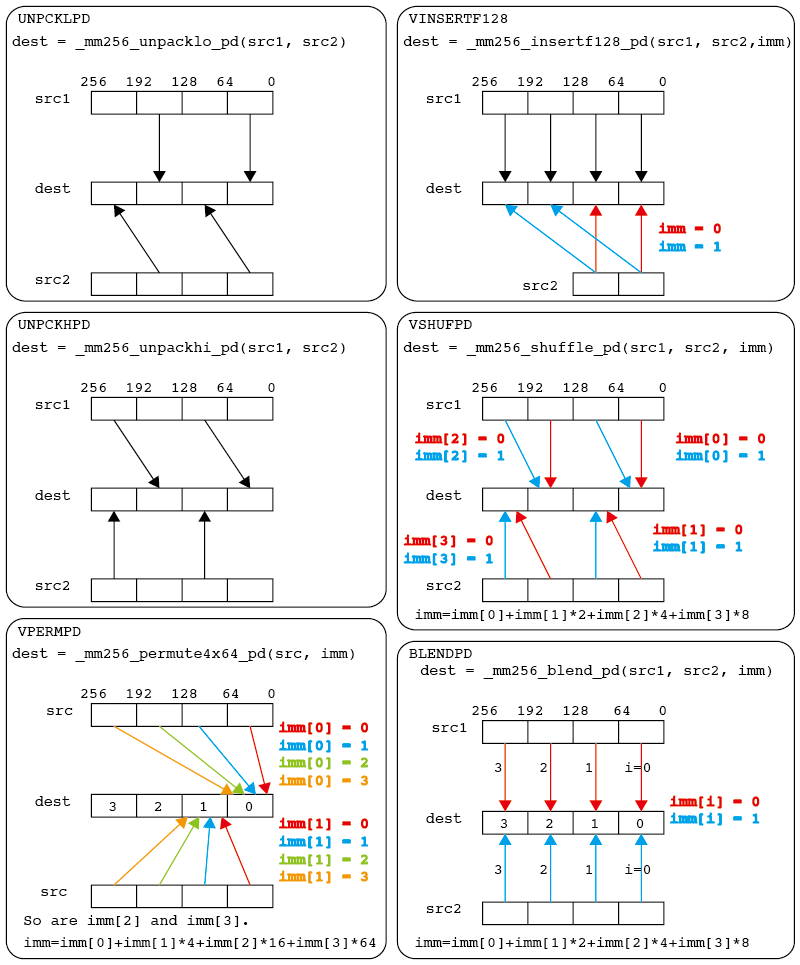
unpacklo/UNPCKLPD
二つのYMMレジスタの、上下128bitのそれぞれ下位64bitをまとめて取ってくる。具体例をみるのが早いと思う。
__m256d src1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
__m256d src2 = _mm256_set_pd(7.0,6.0,5.0,4.0);
print256d(_mm256_unpacklo_pd(src1,src2));
// 6.000000 2.000000 4.000000 0.000000
二つのベクトルsrc1=(3,2,1,0), src2=(7,6,5,4)が与えられた時、src1から(2,0)を、src2から(6,4)を持ってきて、それを混ぜて(6,2,4,0)を作る。
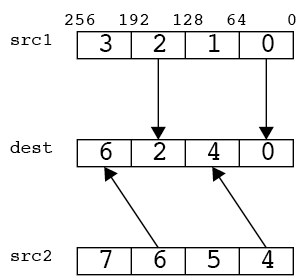
unpackhi/UNPCKHPD
unpackloの上位64bit版。
__m256d src1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
__m256d src2 = _mm256_set_pd(7.0,6.0,5.0,4.0);
print256d(_mm256_unpackhi_pd(src1,src2));
// 7.000000 3.000000 5.000000 1.000000
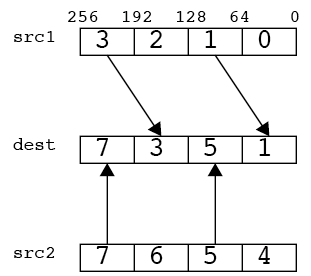
insertf128/VINSERTF128
XMMレジスタの値をYMMレジスタにコピーする。この時、下位128bitにコピーするか、上位128bitにコピーするかを選べる。第三引数が0なら下位に、1なら上位にコピー。コードは両方やっているが、図は引数が0の時の例。
__m256d src1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
__m128d src2 = _mm_set_pd(5.0,4.0);
print256d(_mm256_insertf128_pd(src1,src2,0));
// 3.000000 2.000000 5.000000 4.000000
print256d(_mm256_insertf128_pd(src1,src2,1));
// 5.000000 4.000000 1.000000 0.000000
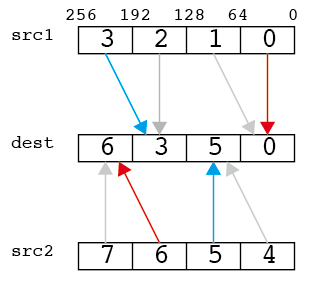
shuffle/VSHUFPD
二つのYMMレジスタを混ぜる。できるレジスタは、(src2,src1,src2,src1)の順番となる。第三引数で、128bitの上位、下位64bitのどちらを取ってくるかを選べる。第三引数は四桁の二進法になっており、0が下位、1が上位を表す。具体例を見るとわかりやすいと思う。以下は第三引数として「0110」、つまり「下位、上位、上位、下位」を選んだ例。
__m256d src1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
__m256d src2 = _mm256_set_pd(7.0,6.0,5.0,4.0);
const int imm = 0*8 + 1*4+ 1*2 + 0*1;
print256d(_mm256_shuffle_pd(src1,src2,imm));
// 6.000000 3.000000 5.000000 0.000000
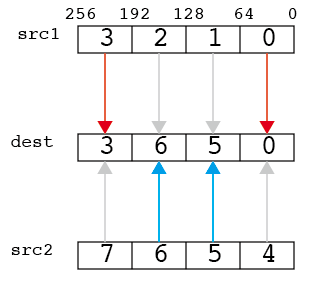
blend/BLENDPD
二つのYMMレジスタを混ぜる。これはdestレジスタの、対応する場所を、src1とsrc2のどちらを取ってくるかを選ぶ。第三引数は四桁の二進法になっており、0がsrc1を、1がsrc2を表す。以下は、第三引数として「0110」を指定した場合の例。
__m256d src1 = _mm256_set_pd(3.0,2.0,1.0,0.0);
__m256d src2 = _mm256_set_pd(7.0,6.0,5.0,4.0);
const int imm = 0*8 + 1*4 + 1*2 + 0*1; // 0110
print256d(_mm256_blend_pd(src1,src2,imm));
// 3.000000 6.000000 5.000000 0.000000
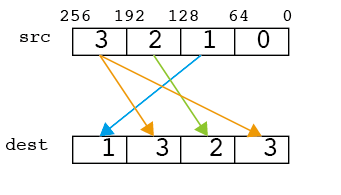
permute/VPERMPD
一つのYMMレジスタの値を任意に並び替える(AVX2)。この時、おなじ要素を重複して選んで、複数コピーすることもできる。だからもともとのベクトルが(3,2,1,0)だった場合、(0,0,0,0)から(3,3,3,3)まで自由に作ることができる。第二引数は四桁の四進数になっており、それぞれどこを取ってくるか指定する。以下は、第三引数として「1323」を指定した場合の例。
__m256d src = _mm256_set_pd(3.0,2.0,1.0,0.0);
const int imm = 1*64 + 3*16 + 2*4 + 3*1; // 1323
print256d(_mm256_permute4x64_pd(src,imm));
// 1.000000 3.000000 2.000000 3.000000
まとめ
いつも「あれ?どっちが上位だっけ?」とか、「混ぜる奴の第三引数ってどういう意味だっけ?」とかごちゃごちゃになるのでまとめてみた。