ORACLEのオプティマイザについて
ORACLEの実行計画を決める方法としてルールベースオプティマイザ(RBO)と
コストベースオプティマイザ(CBO)があります。
最近のORACLE(バージョン10以上)ではRBOはサポート外の為、
この記事は基本的にCBOでのチューニングについての内容になります。
CBOとは
ORACLEがSQLを実行する前に、その要求データに対して
どのようにアクセスしたら効率的かを自動で判断してくれる機能になります。
また、テーブルのデータカラムに対してのアクセス増減までも自動で解析し、
実行計画を計算してくれます。
ただ、これは入力されたSQLに対して効率的にアクセス解析を行うといだけなので、
関係ないテーブルとかが指定されていた場合でも、CBOはSQLに書かれていたら
コストとして算出してしまいます。
例
SELECT
E.member,
D.dept_id
FROM
EMP E,
DEPT D,
MEMBER M
WHERE
E.member_id = D.member_id
↑の場合などに、MENBERテーブルは参照してないが、
実行計画でCBOによってコストが加算されてしまったりする。
チューニングの準備として
性能測定などをする場合は、
ALTER SYSTEM FLUSH SHARED_POOL;
ALTER SYSTEM FLUSH BUFFER_CACHE;
などのDDL文を流し、DBのキャッシュクリアを行った後に
改善前後のSQLでパフォーマンス測定をしなければなりません。
と、いうのもSQL一度発行した時に、実行文や抽出したデータブロックなどをキャッシュとして保持し、
次回実行時により高速に動かそうとする為、キャッシュのクリアが行われてないと
何も変更してないSQLなのに初回実行と二回目だと勝手にパフォーマンスが上がるなどがあるからです。
ちなみにキャッシュの確認は以下SQLで行えます。
select
b.obj,
o.object_name,
count(*) blocks,
b.lru_flag,
b.tch
from
x$bh b
left outer join dba_objects o
on b.obj = o.object_id
group by b.obj, o.object_name, b.lru_flag, b.tch
実行計画の見方
実行計画は次のように表示されます。
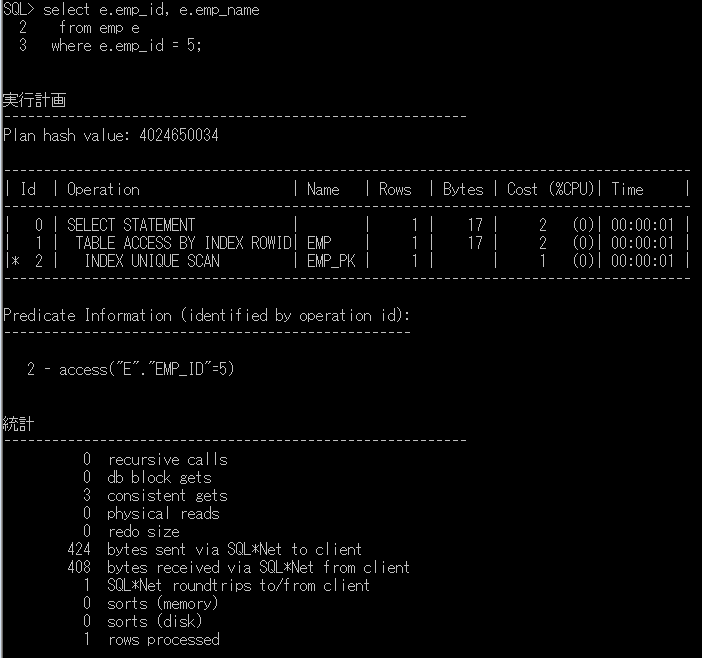
↑の画像ですと、empテーブルに対して、TABLE ACCESS BY INDEX ROWIDでアクセスを行い
INDEX UNIQUE SCAN で empテーブルのemp_pkの索引を使用して該当レコードを取得しています。
#INDEXの見方(の一部)
FULL SCAN → 索引からのすべての ROWID の取得
UNIQUE SCAN → ユニークキーを使用して1つの ROWID を取得する
RANGE SCAN → 索引から範囲(スタート・キー、ストップ・キー)をキーにして1または複数 ROWID の取得
などがあります。
ROWIDとは
ROWIDはテーブルに格納されているデータを一意に決める事が出来る文字列で、
意図して取得しないとカラムとして見えませんが
SELECT E.ROWID,E.EMP_ID FROM emp E;
とかやると取れる値です。
プライマリーとは別で、ORACLEがレコードを識別するのにつかわれたりするカラムで、
値は'OOOOOOFFFBBBBBBRRR'とかランダムな文字列が格納されています。
実際にその文字列をWHEREとかで指定して、レコードを取得する事もでき
単一レコードへのアクセスは最速ですが、ORACLEの機嫌で値が変わる(ALTERやCREATEなどのDDL実行とか)
ので、実際にプログラム上で安易にROWIDを指定したSQLは書けません。
(変更がない事が確定してたり、1Trunsactionが確定していたりする場合とか・・・?)
INDEXを使えば必ず早くなるというわけでもない
SQLチューニングを行う場合にINDEXを使えば必ず早くなる、
というわけでもないらしいです。
実は違うパターンもあったりします。
例えば、上で書いたように、
UNIQUE SCANとかで絞り込みを行いデータを抽出する場合、
全体的なテーブルデータ量の20%以上だと
FULL SCANの方が早かったりする。
っていうのをどっかの記事でみて、
実際に気になって試してみました。
テストデータとして300万レコードをInsertしたテーブルにて、
INDEXと別のカラムを指定してSELECTをしてみました。
SELECT
M.MEMBER_ID,
M.MEMBER_NAME
FROM
MEMBER M
WHERE
M.MEMBER_ID >= '1000000'
MEMBERテーブルのIDは1−3000000入っていて、
指定のWHEREだと全体の2/3を取得する事になります。
私の環境だと上記のSQLとWHEREの指定が無いSQLだと
WHEREが無いFULL SCANの方が実行結果は
1/2ほど早くなりました。
ただ、これはデータカラムの定義や、実際に格納されている値や環境の使用しているCPUなどでも
結構差が出てくるっぽいです。
FULL SCANのが早い理由として、WHERE指定ありだと一度INDEXのスキャンを行ったのちにサイドレコードをINDEXの指定で絞り込んでから表示するのに対し、
FULL SCANで最初からINDEXのスキャンなどを行わずにデータを表示するかららしいです。
SQLの組み方などでは、INDEXをあえて指定せずに、
データごっそり抜き出して後で、結合などでふるい落としたりしたほうが
早かったりするパターンなどもあるみたいです。
結局どうしたらよいか
・SQLを解析し、コストが掛かっている部分を疑い別の表現で書き直せないか試す。
・必ずINDEXを使えば早くなるというわけでもない。
・SQLキャッシュのクリアを行い事前後で実測値を図りチューニングを行う。
などになるんでしょうか。
まだ、あやふやな部分が多いので勘違いしてたりする部分ばあればご指摘いただければと思います。
参考サイト
実行計画について:http://www.magata.net/memo/index.php?%BC%C2%B9%D4%B7%D7%B2%E8%A4%CE%C6%C9%A4%DF%CA%FD(Oracle)
オプティマイザについて:http://www.oracle.com/jp/corporate/branch/20130417-yokata-cbo-1-1936862-ja.pdf