はじめに
「Rxを使った設計をビジュアル化する」の続きです。
前回はフルに Rx を使った設計をどのように行うか1を考えて、ビジュアル化して説明しました。その際にシステムを分割する手法として従来のクラス分割の考え方が利用できることを示しました。
しかしコード例を見ると、クラスの内部実装は従来のオブジェクト指向、手続き型のコードとは似ても似つかないものになっています。
ここでは従来の実装が、 Rx のオペレータを使った実装にどのように置き換わるのかを例をあげて解析してみようと思います。
そして、なぜ Rx が関数型プログラミングとの絡みで語られることがあるのかを考えてみます2。
実装がどう変わったか?
メソッドがやっていたこと
メソッドがやっていたことを分類してみます。
プロパティの読み書きは getter / setter アクセスでも同じことなので、これらはメソッド呼び出しと捉えられます。getter 以外のメソッドが戻り値を返さないように変更しておけば、以下のようになるかと思います。
- 条件分岐
- ループ
- 他のメソッドに渡す引数を計算する
- 他のメソッドを呼び出す
- プロパティの値を取得
これらをオペレータに置き換える例を紹介します。
メソッドはObservableかObserverになる
クラス設計の時点でメソッドは全て Observable か Observer に置き換わっています。
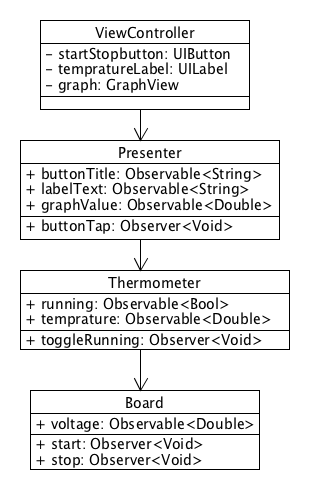
Observer の実体は Subject なので、それを持っているクラス内では Observable としても扱えます。プロパティも同様です。つまりこれらはそのクラス内であればオペレータで他の Oberavable と合成できます。
デリゲートメソッドの呼び出しはObservableの生成に
値に変化があったらデリゲートのメソッドを呼んで通知するコードがあるとします。
class Thermometer : BoardDelegate {
private var runnning = false
func toggleRunning() {
running = !running
delegate?.didChangeRunning(running)
}
func didChangeVoltage(voltage: Double) {
delegate?.didChangeTemprature(convertToTemprature(voltage))
}
デリゲートなどで上層クラスへイベント通知するメソッド呼び出しや、自身のプロパティの setter 呼び出しは、Observable の生成に置き換わります。
class Thermometer {
// ...
init(/* ... */) {
running = runningVar.asObservable()
temprature = board.voltage
.map(convertToTemprature)
.shareReplayLatestWhileConnected()
// ... (runningのトグル処理は省略)
}
下層クラスのメソッド呼び出しはObservableのバインドに
下層クラスのメソッドを呼び出す部分は、
class Thermometer : BoardDelegate {
private var runnning = false {
didSet: {
if running {
board.start()
} else {
board.stop()
}
}
}
Observable を bindTo での接続する形に置き換わります。
init(/* ... */) {
// ...
running
.filter { $0 }
.map { _ in () }
.bindTo(board.start)
.addDisposableTo(disposeBag)
running
.skip(1)
.filter { !$0 }
.map { _ in () }
.bindTo(board.stop)
.addDisposableTo(disposeBag)
条件分岐で呼び出しメソッドが変わるならfilter
if や switch で条件分岐して他のメソッドを呼び出す処理は、 Rx では filter で置き換えることになります。filter は else のない単発の if に相当します。複数の分岐をまとめて記述できる if 〜 else 〜, swith に比べると正直ちょっと面倒で記述性は悪いです。
class Hoge : CacheDeleage {
private let cache: Cache
var delegate: HogeDelegate?
// CacheDelegateのメソッド。キャッシュ最大サイズの変更を通知してもらう。
func didChangeMaxSize(size: Int) {
if size == 0 {
delegate?.didClearCache()
} else {
delegate?.didChangeMaxCacheSize(size)
}
}
init(cache: Cache) {
self.cache = cache
cache.delegate = self
}
// ...
こんな感じで filter を使います。
class Hoge {
let cacheClearedEvent: Observable<Void>
let maxCacheSizeChangedEvent: Observable<Int>
init(cache: Cache) {
cacheClearedEvent = cache.maxSize
.skip(1)
.filter { $0 == 0 }
.share()
maxCacheSizeChangedEvent = cache.maxSize
.skip(1)
.filter { $0 != 0 }
.share()
}
}
メソッドへの引数の用意はmap
class Presenter : ThermometerDelegate {
// ...
func didChangeRunning(running: Bool) {
let buttonTitle = running ? "停止" : "開始"
delegate?.didChangeButtonTitle(buttonTitle)
}
}
呼び出すメソッドの引数を用意する処理は、map で置き換えます。
class Presenter {
let buttonTItle: Observable<String>
// ...
init(thermometer: Thermometer) {
buttonTitle = thermomether.running
.map { $0 ? "停止" : "開始" }
.shareReplayLatestWhileConnected()
// ...
}
}
map 内の条件分岐は普通に if や switch が使えます。この例では三項演算子を使っています。
プロパティ値の利用は合成で
以下のように条件分岐でプロパティ値を利用したり、
class Hoge : CacheDeleage {
// ...
// Cache クラスからの maxSize 変更を受け取る
// 受け取った内容に応じてキャッシュクリアか最大サイズ変更かを上位に伝える
func didChangeMaxSize(size: Int) {
if cache.enabled { // ここの条件で cache の enable プロパティを利用
if size == 0 { // ゼロに設定することでキャッシュクリアする仕様(良い悪いは置いといて)
delegate?.didClearCache()
} else {
delegate?.didChangeMaxCacheSize(size)
}
}
}
// ...
引数を用意している時にプロパティ値を利用したり、
class Presenter : ThermometerDelegate {
// ...
var count = 0
func didChangeRunning(running: Bool) {
// 以下で count プロパティを利用している
let buttonTitle = " \(count)回目の測定を" + (running ? "停止" : "開始")
delegate?.didChangeButtonTitle(buttonTitle)
}
}
する場合について考えます。つまりメソッドの引数で渡されるイベント値(上記例では running)以外に、プロパティで管理している値(上記例では count)も利用する場合です。
メソッドもプロパティも Observable になっているのだから、これらは合成すればいいんです。これも元のコードに比べて正直読みやすいとは思えません。
class Hoge {
private let disposeBag = DisposeBag()
let cacheClearedEvent: Observable<Void>
let maxCacheSizeChangedEvent: Observable<Int>
init(cache: Cache) {
let maxCacheSizeUpdatedEvent = cache.maxSize
.skip(1)
.withLatestFrom(cache.enabled) { newSize, enabled in (newSize, enabled) }
.filter { _, enabled in enabled }
.map { newSize, _ in newSize }
.share()
cacheClearedEvent = maxCacheSizeUpdatedEvent
.filter { newSize in newSize == 0 }
.share()
maxCacheSizeChangedEvent = maxCacheSizeUpdatedEvent
.filter { newSize in newSize != 0 }
.share()
}
}
もう一つの例は thermometer.running, count のどちらが変化しても buttonTitle が変化するので、combineLatest を使って合成しています。
class Presenter {
private let countVar = Variable(0)
let buttonTItle: Observable<String>
let count: Observable<Int>
// ...
init(thermometer: Thermometer) {
count = countVar.asObservable()
buttonTitle = [thermometer.running, count].combineLatest {
running, count in
" \(count)回目の測定を" + (running ? "停止" : "開始")
}
.shareReplayLatestWhileConnected()
// ...
}
}
他メソッドを複数回呼び出すループはflatMapで
ここで扱うのは以下のような場合です。
class Hoge {
func doSomething(count: Int) {
for i in 0..<count {
run(i)
}
}
1つのイベントを受信したら複数のイベントを発生させています(イベントとして count が渡され、count 回の run を呼び出す)。
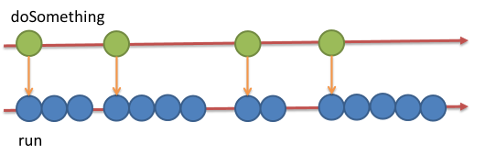
こういうのは flatMap を使うことで置き換えられます。う〜ん、for 文に比べると読みにくくなるなぁ。
run = doSomething
.flatMap { count in
Observable.generate(initialState: 0, condition: { $0 < count}) { $0 += 1 }
}
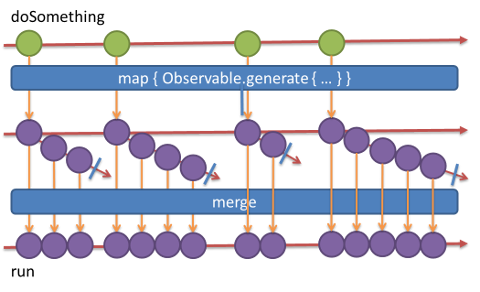
flatMap は map + merge と同様です。
run = doSomething
.map { count in
Observable.generate(initialState: 0, condition: { $0 < count}) { $0 += 1 }
}
.merge()
関数型プログラミングとの関係
もし自分がフルに Rx を使うならどんな設計になるだろうか?と考えてみたわけですが、この結果を元に、なぜ Rx が関数型プログラミングとの絡みで語られるのかを考えてみようと思います。
再代入可能な変数を使わない
状態を全て Observable (Variable) に包んでしまっているので、コードの中に let しか出てきません(if や switch が値を返さない Swift の特性上、オペレータに渡す関数の中では計算途中の一時変数として var を使うことがたまにあります)。
関数型プログラミングでは再代入可能な変数を使いません(または極力避けます)。その方が__動作が理解しやすく、テストしやすく、バグの原因を取り除ける__からです。
これがピンとこないという人は、以下についてなら納得できると思います。
- グローバル変数は(シングルトンもグローバル変数的には)できるかぎり使うな
- 変数はカプセル化しろ
どちらも状態の影響範囲を局所化することで、理解しやすく管理しやすくしようということです。状態をうまく管理しないと、動作が理解しづらく、テストしにくく、バグの原因になることは、関数型プログラミングうんぬん関係なく分かっているわけです。
状態をクラスにカプセル化するのをさらに推し進めて Observable に包んでしまい、アプリ側コードから再代入可能な変数を削除すれば、状態が原因の多くのバグを避けることができます。
データと関数
フルに Rx を使ったら、メソッドが無くなってしまいました。なお前の記事の例で class を使いましたが、Swinject で管理せずに自前でオブジェクトツリーを構築するなら、別に struct でも構いません。
メソッドがないのだから、もうこれはオブジェクト指向で言うところの「データと操作」をカプセル化したものではなく、単なる Observable, Variable, PublishSubject などを値に持つデータ型でしかありません。Observable が通知するものも、プリミティブ型だったり struct で表したデータ型です。
そして Observable に対してオペレータを適用するわけですが、このオペレータに渡す処理は関数です。クロージャ構文で書かれた名前のない即時関数であろうと、名前を付けて定義した関数であろうと、参照透過で副作用のない関数を渡します。
オペレータ自体は Observable のメソッドですが、
let newObservable = observable
.skip(1)
.filter { $0 }
.map { _ in () }
.share()
これらのオペレータは、以下のように第一引数に Observable を受け取り、新しく Observable を生成して返す参照透過で副作用のない関数としても実装できます。
let newObservable = share(map(filter(skip(observable, 1), { $0 }), { _ in () }))
でも読みにくいですよね? F#, Elixir, Elm などの幾つかの関数型言語にはパイプライン演算子というのがあります。left |> right と書くと、left を right の第一引数として渡してくれます。それがもし Swift にあれば、
let newObservable = observable
|> skip(1)
|> filter { $0 }
|> map { _ in () }
|> share()
と書けます。でも Swift にはパイプライン演算子なんてないので、メソッド(隠れた第0引数 self にドットの前のオブジェクトが渡される)にして、ドット演算子で繋ぐように実装されていると捉えることができます。
このようにフルに Rx を使った設計は、__イミュータブルなデータと、参照透過で副作用のない関数でできている__と考えられます。
参照透過
参照透過という言葉を使ったので、一応何なのか説明しておきます。分かってる人は飛ばしてください。
参照透過性というのは、入力が同じなら出力も同じになるという特性です。このような関数は__動作が理解しやすく、テストしやすく(以下略)__。
例えば以下の関数は入力が同じなら出力は常に同じになります。引数以外の値を利用していません。
// minValue <= value <= maxValue に納まるようにする
func clamp(value: Double, minValue: Double, maxValue: Double) -> Double {
return min(max(value, minValue), maxValue)
}
以下の関数は参照透過じゃありません。関数の引数以外の変更可能な値を利用しています。
var minValue = 0.0
var maxValue = 100.0
func clamp(value: Double) -> Double {
return min(max(value, minValue), maxValue)
}
以下は参照透過ですね。minValue, maxValue は定数であり変更不可です。
let minValue = 0.0
let maxValue = 100.0
func clamp(value: Double) -> Double {
return min(max(value, minValue), maxValue)
}
これは参照透過じゃありません。minMax は再代入できませんが、そのプロパティは変更できます。いわゆる mutable なオブジェクトだからです。
struct MinMax {
var minValue = 0.0
var maxValue = 100.0
}
let minMax = MinMax()
func clamp(value: Double) -> Double {
return min(max(value, minMax.minValue), minMax.maxValue)
}
Rx でやってはいけない例を挙げると、以下のようなコードです。
class Hoge {
var running = false
let message: Observable<String>
init(fuga: Fuga) {
message = fuga.target
.map { [unowned self] target in
"\(self.running ? "動作中" : "停止中"): \(target)"
}
.shareReplayLatestWhileConnected()
}
}
map の中で、クロージャに渡される target 引数以外に、running プロパティを利用しています。これを避けるには running 自体も Observable にして合成します。
class Hoge {
let running = Variable(false)
let message: Observable<String>
init(fuga: Fuga) {
message = [fuga.target, running.asObservable()].combineLatest {
target, running in "\(running ? "動作中" : "停止中"): \(target)"
}.shareReplayLatestWhileConnected()
}
}
副作用
副作用についても説明しておきます。参照透過性は引数以外に変化するものを受け取らないという入力に注目しましたが、副作用は戻り値以外に出力がない(外部に影響を及ぼさない)という点に注目します。副作用がない関数は__動作が理解しやすく(以下略)__。
class Hoge {
var value = 0
// ...
func clamp(value: Double, minValue: Double, maxValue: Double) -> Double {
// ...
let result = min(max(value, minValue), maxValue)
self.value = result
print("new value = \(result)")
return result
}
// ...
上のコードは入力が同じなら戻り値は同じであり参照透過です。でもインスタンス変数が変化します。また標準出力にテキストを出力します。戻り値以外に外部への影響という出力があります。これを副作用といいます。
Rx では、サーバーとの通信やファイルの読み書きなどの__副作用を伴う処理は subscribe されると実行される Cold な Observable に包んでしまう__ことができます。さすがにログ出力まで Observable で包むことは普通しないかと思いますが、その場合は doOn や debug などのオペレータを使って、イベントシーケンスに影響を与えないようにします。
モナド
Rx では UI などの外部からのイベントや内部状態、外部に影響を与える副作用を伴う処理を Observable で包むことができます。そうすることで、それらを使う部分では
- イミュータブルなデータ
- 参照透過で副作用のない関数
だけでプログラミングすることができます。
これって純粋関数型言語である Haskell がモナドを使ってやっていることと同じです。実は __Observable はモナド__なんです。モナドが何なのかの説明は世の中に溢れている3ので、ここでは割愛します。モナドに拒否反応がある人も大丈夫です。別にモナドが何かを知らなくても、使えればいいんです。
スマホアプリは状態の塊ですし、ファイル操作やネットワーク通信などの副作用だらけです。そんなアプリでも、それらをモナドである Observable に包むことで、下図のようなユートピアでプログラミングできるようになります。
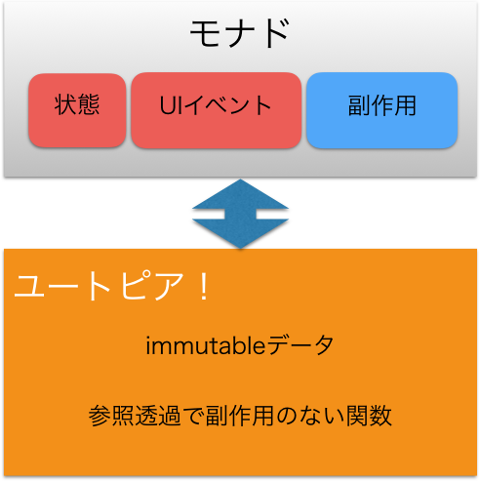
このようにバグの原因になりやすい内部状態や副作用を、__隔離することでプログラムを安全にする__という方針です。
オブジェクト指向との関係
一方、オブジェクト指向では内部状態や副作用をクラスにカプセル化して、その__影響範囲を局所化して扱いやすくする__という方針です。
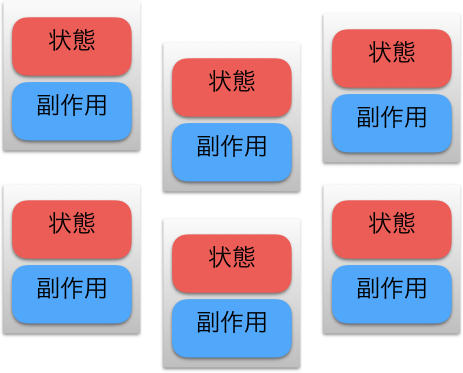
__関数型もオブジェクト指向も、同じ問題に対処しようとしています__が、オブジェクト指向が問題の影響を小さくしようとするのに対して、関数型プログラミングのモナドを使ったアプローチの方は、問題を完全に追い出そうとしているのが分かるかと思います。
対象によって設計のしやすさとかプログラミングのしやすさとかも違うでしょうし、向き不向きがあるかと思いますので、一概にどちらが優れているとか言うつもりはありません。少なくとも現時点では、オブジェクト指向の方が普及しており「関数型プログラミングはハードルが高い」という状態かと思います。
今回の記事では、私自身がオブジェクト指向に慣れていることもあり、モジュール分割をオブジェクト指向的に行いました。これにより少なくとも設計に関しては、Rx を介することでオブジェクト指向との橋渡しができたんじゃないかと思います。例えば、以下のように VIPER (Stroyboard 使うならいらないかと思って Router 除いてますが)のような設計にするのも容易にできます。
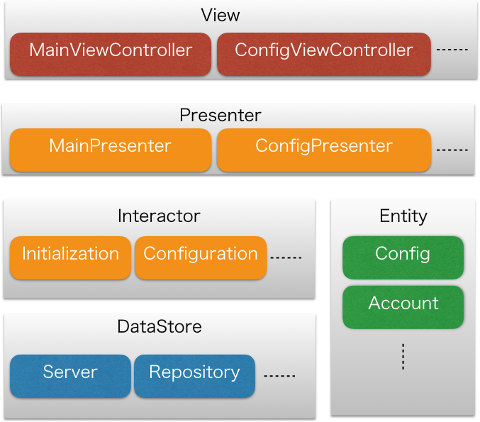
iOS SDK の UIKit が継承を使うように設計されているので、上図で赤色のものは普通のオブジェクト指向のクラスです。緑色のものは Observable を流れるデータ型、青色のものは副作用を伴う非同期処理を行う Cold な Observable を生成する関数をまとめる単位(名前空間)です。
オレンジ色のものは
- 出力が Observable
- 入力が Observer
- 内部状態が Variable
なデータ型です。
ここで注意して欲しいのは、Cold な Observable を生成する関数自体は参照透過で副作用のない関数だということです。引数が同じなら同じ処理をする Observable を生成して返すので、参照透過です。そして関数を呼び出しても副作用を起こす処理を実行するわけではありません。実行されるのはその Observable が subscribe される時であり、それは Rx が行います。
データフロープログラミングとの関係
前の記事で「データフロープログラミングとリアクティブプログラミングは、捉え方が違うだけで本質的には同じものに思えます。」と書きました。しかしリアクティブプログラミングの方が後発であり、__データフロープログラミングを発展させたもの__と捉える方が正しいのでしょう。
概念的な捉え方やコードの記述方法だけでなく、本質的なところで何か発展があるかと考えると、
- イベントを通知する Observable をイベントとして通知する Observable が作れる(Observableを入れ子にできる)
点でしょうか?
Observable を入れ子にし、処理を実行する Observable をイベントとして流すことで、非同期処理に対して
- 順次実行
- 並列実行
- 前のが処理中だったら次の処理開始要求は無視
- 次の処理開始要求が来たら処理中のものを中止して実行
などの制御を簡単に行うことができます。
設計や記述の統一性
ここで紹介したフルに Rx を使った設計は、__設計や記述の仕方がかなり統一__されています。
選択肢が複数あると、考えるべきことが増えます。最適な選択ができるかどうかはプログラマのレベルに左右されます。そして人によって選択が違う、あるいは場所によって最適なものが違うと、記述方法があちこちでバラバラになって保守しにくいコードになります。
ここで紹介した
- 状態は Variable で保持
- 入力は Observer で受け、出力は Observable で通知
- プロパティは全て let で変更不可
- 関数は全て参照透過で副作用がない
- (ロギングを除いた)副作用は Observable 化する
- ロギングには doOn, debug を用いる
といったルールを守ることで、設計やコードの記述方法が統一され、複数のプログラマが関わった際の品質の均質化が期待できます。
つまりこの点において、リアクティブプログラミングが向く領域 -- 主に内部状態・データがリアルタイムに表示に反映されるような GUI プログラムにおいては、__フレームワークを導入するのと同じような効果__が期待できます。
欠点もフレームワークと同様です。
- 向いていない領域ではかえって「悪い選択」を強要されている状況になる
- 学習コストがかかる
- ロックイン4のリスクがある。
Rxの記述は分かりやすいと思えない
今回の記事で所々、「記述性が悪い」とか「読みやすいとは思えない」とか書いています。個人的な意見ですが、Rx で書いたら必ずしもコードが分かりやすくなるとは思いません。この記事で挙げた例では、ほとんどは制御構文で書いた方がオペレータで書くより読みやすいし分かりやすいと感じます。自分が手続き型に慣れているからってだけではないと思います。
手続き型のこちらを
var a = 1
let b = a + 1
a = 2
print("b = \(b)")
リアクティブになるようにしたこちらは
let a = BehaviorSubject(value: 1)
let b = a.map { $0 + 1 } // b = a + 1
b.subscribeNext { print("b = \($0)") }
a.onNext(2)
概念うんぬんプログラミングスタイルうんぬん以前に、表現したいことに対してゴチャゴチャしすぎです。
リアクティブではないんですが、例えば 以下の Makefile を見てください。
animal := A dog
text = $(animal) is walking.
animal := A cat
all:
@echo $(text)
make を実行すると all に書いてある部分が実行され、text の内容が表示されます。
A cat is walking
後に代入した方の A cat が採用されました。Makefile には代入演算子が2種類あって、:= は即時代入されますが、= の方は利用時に評価されます5。そのように宣言的に記述することを想定して文法が設計されています。
Rx の例より遥かに分かりやすい。結局、言語自体が指向していない概念をライブラリで無理に持ち込むから、ゴチャゴチャしたコードになるんです。関数型言語から多くを取り入れている Swift でさえです。
確かに Rx はオブジェクト指向言語にリアクティブプログラミングのメリットを持ち込みます。バグも減るし、大抵はコード量も減ります。並列処理もしやすい。
しかし言語が本来指向しているのと違うものを持ち込むことによる、__記述のしにくさ、分かりにくさを持ち込む面もある__ということです。まるで Swift 上で動くパラダイムの違う新たな言語を使っているかのようです。
そして__一番大きな問題はチームメンバーのプログラミングスタイルへの親和性__です。全員を教育できるでしょうか?このスタイルに慣れた人員を確保できるでしょうか?
実際のところ、__多くのプロジェクトでは Rx をフルに使うのはやりすぎ__なんじゃないでしょうか? デメリットもあることを知った上で、Rx がもたらすメリットをどこにどの程度取り入れるか選択できるようになりましょう。
まとめ
徹底的に Rx 化しようとすると、手続き型で制御構文を使っていた部分の多く6がオペレータに置き換わります。どのように置き換わるのかを例をあげて説明しました。何か例を思いついたら適宜追記します。
リアクティブプログラミングの関数型プログラミング的な側面についても考察しました。Rx を利用することで、関数型プログラミングの持つメリットを取り入れることができます。
オブジェクト指向プログラミングとの関係も考察しました。実装は関数型プログラミング的になりますが、設計においてシステムを分割する方法は(慣れた、あるいは情報が多い)オブジェクト指向の手法が使えます。Rx はオブジェクト指向で一般的なオブザーバーパターンをベースにしており、オブジェクト指向で使われる各種イベント通知方法を置き換える形から導入できます。Rx を介することで、オブジェクト指向プログラミングから関数型プログラミングへ移行する橋渡しができるのではないでしょうか。
また Rx のオペレータを使った記述がコードを読みにくく分かりにくくする場合があること、チームにパラダイムの違うプログラミングスタイルを持ち込むことの難しさも指摘しました。全く違うパラダイムにいきなりジャンプするのではなく、イベント通知を置き換えるところから順に移行できるとはいえ、その終着点に到達したフル Rx なプロジェクトにいきなり放り込まれる人は大変でしょう。
もしメンバー全員が Rx を十分に使えるレベルに教育できるなら、フルに Rx を使った設計にすることで、そのメリットを享受しつつ、コード品質の均質化が期待できそうです。
-
もし自分がやるとしたら、こんな感じにするだろうなというものに過ぎませんが。 ↩
-
関数型プログラミングの定義ってないみたいなので、あくまで関数型プログラミングの文脈で語られることが多いものの一部です。 ↩
-
SwiftのOptionalもモナドです。モナドの例を色々知って使い慣れてからこれらの説明を読むと、その共通点からどんなものか分かってくるんじゃないでしょうか? ↩
-
特定のフレームワークやバージョンに依存してしまう。 ↩
-
Makefileは文字列操作は得意なんですが算術演算がないので、文字列の例で説明しています。シェルを呼び出せば算術演算も簡単にできますが。 ↩
-
オペレータに渡す処理(関数)内では制御構文が使えます。 ↩