下図のように、「縦持ち」のテーブルを「横持ち」に置き換えることをピボット(pivot)、逆に「横持ち」のテーブルを「縦持ち」に置き換えることをアンピボット(unpivot)と呼びます。これらの変換を行なう方法をまとめました。
- 標準SQL
- Presto
- Hive
- Pandas (Python)
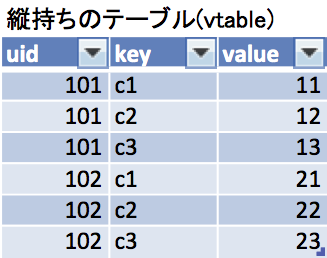

標準SQL
SQL-like なクエリ言語ならどこでも使える書き方です。
Pivot
SELECT uid,
max(CASE WHEN key = 'c1' THEN value END) AS c1,
max(CASE WHEN key = 'c2' THEN value END) AS c2,
max(CASE WHEN key = 'c3' THEN value END) AS c3
FROM vtable
GROUP BY uid
;
uid c1 c2 c3
--- -- -- --
101 11 12 13
102 21 22 23
Unpivot
SELECT uid, 'c1' AS key, c1 AS value FROM htable
UNION ALL
SELECT uid, 'c2' AS key, c2 AS value FROM htable
UNION ALL
SELECT uid, 'c3' AS key, c3 AS value FROM htable
;
uid key value
--- --- -----
101 c1 11
102 c1 21
101 c2 12
102 c2 22
101 c3 13
102 c3 23
Presto
標準SQLの方法でも構いませんが、以下のような書き方も出来ます。
Pivot
map_agg 関数でマップ型の構造を作ってから参照するやり方です。
SELECT
uid,
kv['c1'] AS c1,
kv['c2'] AS c2,
kv['c3'] AS c3
FROM (
SELECT uid, map_agg(key, value) kv
FROM vtable
GROUP BY uid
) t
uid c1 c2 c3
--- -- -- --
101 11 12 13
102 21 22 23
Unpivot
カラムの配列を作ってから CROSS JOIN unnest で展開するやり方です。PostgreSQL でも使えます。
SELECT t1.uid, t2.key, t2.value
FROM htable t1
CROSS JOIN unnest (
array['c1', 'c2', 'c3'],
array[c1, c2, c3]
) t2 (key, value)
uid key value
--- --- -----
101 c1 11
101 c2 12
101 c3 13
102 c1 21
102 c2 22
102 c3 23
Hive
Pivot
標準の Hive 関数ではありませんが、Treasure Data の Hive には to_map UDAF が組み込まれており、マップ型の構造を作ってから参照することが出来ます。
SELECT
uid,
kv['c1'] AS c1,
kv['c2'] AS c2,
kv['c3'] AS c3
FROM (
SELECT uid, to_map(key, value) kv
FROM vtable
GROUP BY uid
) t
uid c1 c2 c3
--- -- -- --
101 11 12 13
102 21 22 23
Unpivot
LATERAL VIEW explode で展開する方法があります。
SELECT t1.uid, t2.key, t2.value
FROM htable t1
LATERAL VIEW explode (map(
'c1', c1,
'c2', c2,
'c3', c3
)) t2 as key, value
uid key value
--- --- -----
101 c1 11
101 c2 12
101 c3 13
102 c1 21
102 c2 22
102 c3 23
Pandas
pivot や melt といった関数が使えます。
Pivot
In [1]: vtable.pivot('uid', 'key', 'value')
Out[1]:
key c1 c2 c3
uid
101 11 12 13
102 21 22 23
Unpivot
In [2]: pd.melt(htable, 'uid', var_name='key')
Out[2]:
uid key value
0 101 c1 11
1 101 c2 12
2 101 c3 13
3 102 c1 21
4 102 c2 22
5 102 c3 23