夏休みの自由研究 〜不労所得の夢〜
せっかくCourseraでCertificateを取ったので、機械学習なりDeepLearningなりで何か作ってみようという夏休みの過ごし方です。
世の中には偉い人がいて、すでに飽きるほど試されたアプローチがあり、そこに対して勉強したなりの考察力を持ってトライしてみます。
将来的には精度の高いモデルを作って夢の不労所得を作って税金払っていきたいですね
導入
勉強したりしてたら1日かかりました。
環境構築
機械学習の初心者でもすぐに出来るTensorFlowのインストール方法
もう色んな人がやっているので、真似してください。気をつけるのはPython3でやるってことですね、pyenvなどで使うバージョンを指定するといいでしょう。
たぶん10分くらいでできると思います。
ライブラリ
Keras
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです.
「DeepLearningってTensorFlowがあればいいのでは?」と思ってたんですが、もちろんそれだけじゃなくてそれをラップしたフレームワークなどがたくさんあり、Kerasはその一つです。 ドキュメントにあるようにtheano/tensorflowのどちらを使うかを選べます。
結局どちらもテンソルを扱うためのもので、違いはよくわかってないですが、最初はそこまで重要じゃないと思いスキップ。
numpy
言わずとしれたpythonの数値計算の便利なやつ
pandas
時系列のデータを扱う便利なやつ
data = pandas.read_csv('./csv/bitcoin_log_1month.csv')
data = data.sort_values(by='date')
data = data.reset_index(drop=True)
こんな感じでcsvをロードしたりするのに便利。ロードするだけじゃなくて、sortしたりindexを付ける機能がある。
Scikit-learn
機械学習の便利なモジュールを提供してくれます。numpy.ndarrayに対する処理を前提としているので、これに対して実施します。正規化のモジュールなどもある。
tflearn
TensorFlowをScikit-learnっぽく使えるようにしたライブラリですね。TensorFlowに組み込まれているので、これでニューラルネットワークを構築したりモデルを定義します。
matplotlib
みんな大好きmatlabですね。作ったグラフを可視化したり画像で保存したりするのに使います。importでエラーが出るので、以下のリンクを参考にmatplotlibrcを一部修正します。
pyenvとvirtualenvで環境構築した時にmatplotlib.pyplotが使えなかった時の対処法
設計
まずは何をしたらいいのか?参考になるリンクをたくさんみてみる。
結局したいことは「明日の終値が上がるのか、下がるのか」という2値分類を解決できる物を作ればいい。参考リンクを呼んで、みんなの不労所得を作りたい気持ちが伝わってきました。Ah yeah.
参考
- TensorFlow(LSTM)で株価予想 〜 株予想その1 〜
- RNNで来月の航空会社の乗客数を予測する:TFLearnでLSTMからGRUまで実装しよう
- TensorFlow (ディープラーニング)で為替(FX)の予測をしてみる
理解しよう
やはりMLとDLは結構違うので、扱われるものがとても異なるので整理しました。
必要な流れ
1. 時系列データの確保
bitcoinの時系列データの在り処はAPI経由で取るならいろんなものがあるのですが、とっととやりたかったのinvestingからDLしました。数年分の年次の終値を取ることができます。JPYでなければ他にもいろいろな選択肢があります。
2. データセットの整形
必要なデータを正規化・標準化を実施します。この時sklearnに入っている
processingパッケージを使うと以下のように簡単にできます。
data['close'] = preprocessing.scale(data['close'])
3. 使うモデル・誤差の選定
使うデータによって必要な誤差やモデルは異なるので、ここがあまり知識なくても引数の差し替えで検証できるとこです。ほんとはちゃんと勉強して意味ある結果を出せると言いと思います。
LSTM(Long Short-Term Memory)はRNNの欠点を解消し、長期の時系列データを学習することができる強力なモデルです。
GRUやLSTNなど様々なモデルがあります、特徴については述べませんが色々あります。
あとは誤差
いろいろな誤差の意味(RMSE、MAEなど)
MAPE、RMSEなど色々これもあります。評価指標なので、モデルを変更したりデータ量を追加したときに実測値と予測値がどれだけ離れているかを評価します。
4. 訓練データ・テストデータの準備
用意したデータを用いでどれだけ学習して、どれだけのデータと比較するかを選びます。訓練:テスト = 8:2 にすることが多いと感じました。
5. これらをもとに予測
構築したニューラルネットワークを使ってモデルを作り、それをもとにfittingを行い、予測を実施する。
6. 評価
あとは結果をグラフ化、可視化して評価します。
TensorBoardというのを使うと、モデルや誤差などを簡単に可視化できます。
大まかにはこの流れを実装できればいいと参考文献より学んだ。
実装
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tflearn
from sklearn import preprocessing
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
class Prediction :
def __init__(self):
self.dataset = None
# 算出する値たち
self.model = None
self.train_predict = None
self.test_predict = None
# データセットのパラメータ設定
self.steps_of_history = 3
self.steps_in_future = 1
self.csv_path = './csv/bitcoin_log.csv'
def load_dataset(self):
# データ準備
dataframe = pd.read_csv(self.csv_path,
usecols=['終値'],
engine='python').sort_values('終値', ascending=True)
self.dataset = dataframe.values
self.dataset = self.dataset.astype('float32')
# 標準化
self.dataset -= np.min(np.abs(self.dataset))
self.dataset /= np.max(np.abs(self.dataset))
def create_dataset(self):
X, Y = [], []
for i in range(0, len(self.dataset) - self.steps_of_history, self.steps_in_future):
X.append(self.dataset[i:i + self.steps_of_history])
Y.append(self.dataset[i + self.steps_of_history])
X = np.reshape(np.array(X), [-1, self.steps_of_history, 1])
Y = np.reshape(np.array(Y), [-1, 1])
return X, Y
def setup(self):
self.load_dataset()
X, Y = self.create_dataset()
# Build neural network
net = tflearn.input_data(shape=[None, self.steps_of_history, 1])
# LSTMは時間かかるのでGRU
# http://dhero.hatenablog.com/entry/2016/12/02/%E6%9C%80%E5%BC%B1SE%E3%81%A7%E3%82%82%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%A7%E3%81%8A%E9%87%91%E3%81%8C%E7%A8%BC%E3%81%8E%E3%81%9F%E3%81%84%E3%80%905%E6%97%A5%E7%9B%AE%E3%83%BBTFLearn%E3%81%A8
net = tflearn.gru(net, n_units=6)
net = tflearn.fully_connected(net, 1, activation='linear')
# 回帰の設定
# Adam法で測定
# http://qiita.com/TomokIshii/items/f355d8e87d23ee8e0c7a
# 時系列分析での予測精度の指標にmean_squareを使っている
# mapeが一般的なようだ
# categorical_crossentropy
# mean_square : 二乗平均平方根
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square')
# Define model
self.model = tflearn.DNN(net, tensorboard_verbose=0)
# 今回は80%を訓練データセット、20%をテストデータセットとして扱う。
pos = round(len(X) * (1 - 0.2))
trainX, trainY = X[:pos], Y[:pos]
testX, testY = X[pos:], Y[pos:]
return trainX, trainY, testX
def executePredict(self, trainX, trainY, testX):
# Start training (apply gradient descent algorithm)
self.model.fit(trainX, trainY, validation_set=0.1, show_metric=True, batch_size=1, n_epoch=150, run_id='btc')
# predict
self.train_predict = self.model.predict(trainX)
self.test_predict = self.model.predict(testX)
def showResult(self):
# plot train data
train_predict_plot = np.empty_like(self.dataset)
train_predict_plot[:, :] = np.nan
train_predict_plot[self.steps_of_history:len(self.train_predict) + self.steps_of_history, :] = \
self.train_predict
# plot test dat
test_predict_plot = np.empty_like(self.dataset)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(self.train_predict) + self.steps_of_history:len(self.dataset), :] = \
self.test_predict
# plot show res
plt.figure(figsize=(8, 8))
plt.title('History={} Future={}'.format(self.steps_of_history, self.steps_in_future))
plt.plot(self.dataset, label="actual", color="k")
plt.plot(train_predict_plot, label="train", color="r")
plt.plot(test_predict_plot, label="test", color="b")
plt.savefig('result.png')
plt.show()
if __name__ == "__main__":
prediction = Prediction()
trainX, trainY, testX = prediction.setup()
prediction.executePredict(trainX, trainY, testX)
prediction.showResult()
参考にしたサイトをとても参考にしたんですが、実装して理解するのに1時間くらいかかりました。
簡単にコードの説明を入れます。
load_dataset
今回使っているデータはこんな感じです。これを読み込んでデータセットとして利用します。データの順番が逆なのでsortなどします。
"日付け","終値","始値","高値","安値","前日比率"
"2017年09月03日","523714.1875","499204.7813","585203.1250","499204.7813","4.91"
"2017年09月02日","499204.7813","542277.3125","585203.1250","498504.5000","-7.94"
setup
ニューラルネットワークを構築します。GRUはDLの手法の一つです。LSTMやRNNなどいろいろなものがありますが、今回は速度を重視して選びました。
net = tflearn.input_data(shape=[None, self.steps_of_history, 1])
net = tflearn.gru(net, n_units=6)
net = tflearn.fully_connected(net, 1, activation='linear')
最適化手法・誤算の選択
今回は最適化はAdam法と誤差はmean_square(RMSE(Root Mean Square Error))を用います。MAPEなどの手法はデフォルトで準備されてないので、ライブラリを一部書き換えて使えるように必要がありそうです。
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square')
executePredict
訓練・テストデータを選択して予測します。
# 今回は80%を訓練データセット、20%をテストデータセットとして扱う。
pos = round(len(X) * (1 - 0.2))
trainX, trainY = X[:pos], Y[:pos]
testX, testY = X[pos:], Y[pos:]
# Start training (apply gradient descent algorithm)
self.model.fit(trainX, trainY, validation_set=0.1, show_metric=True, batch_size=1, n_epoch=150, run_id='btc')
# predict
self.train_predict = self.model.predict(trainX)
self.test_predict = self.model.predict(testX)
結果を見る
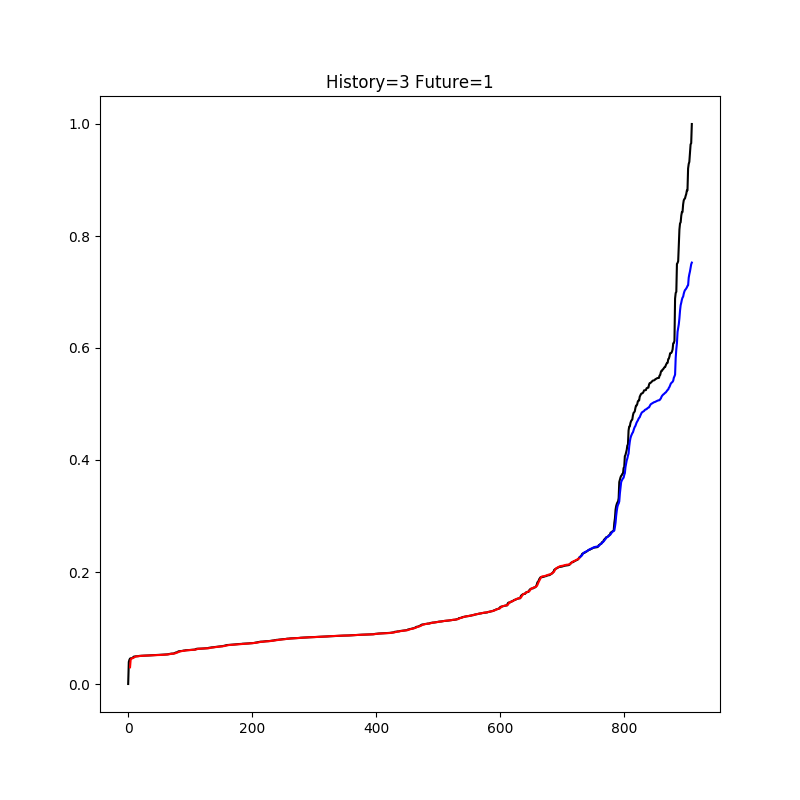
黒が実際のデータで、赤が訓練データ、青がテストデータをもとにした予測値。
こちらがTensorBoardの結果です。
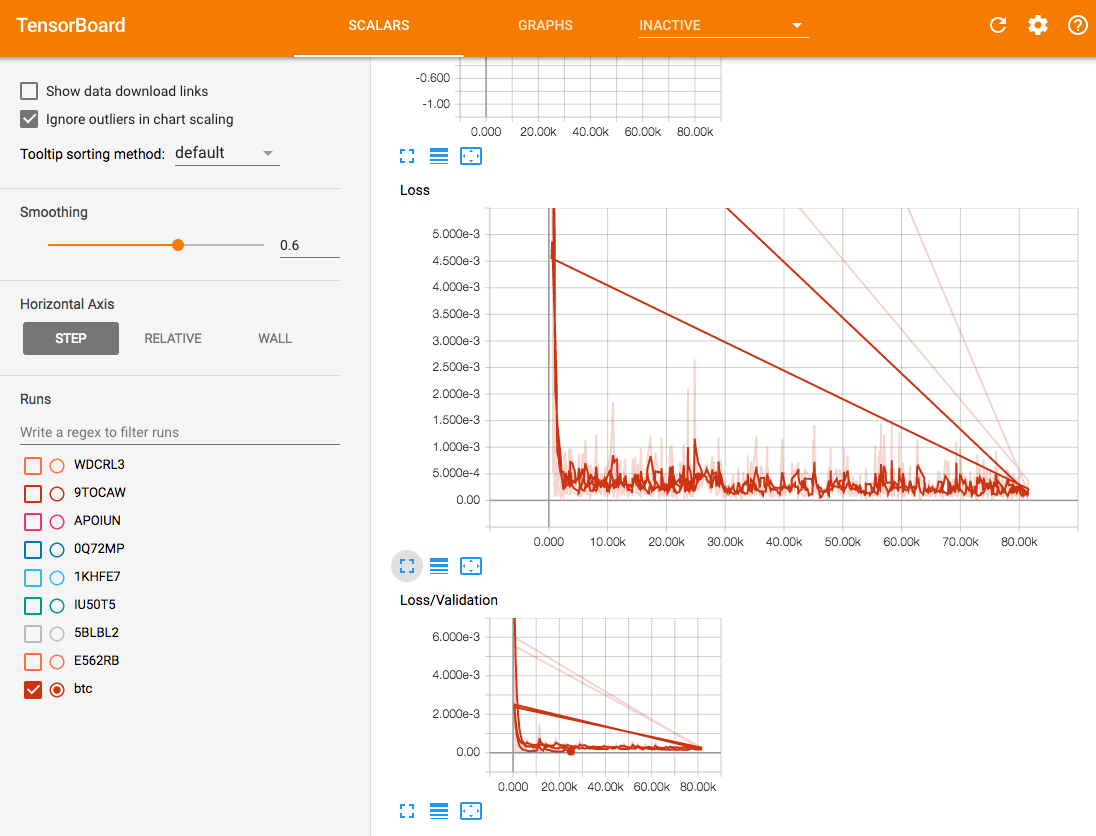
フムゥという感じです。とりあえずLoss/Validationがおかしい。ここからEpoch数やモデルやステップ、訓練データ比率やデータ量、GRUの層の数などを変更しながら誤差が小さくなりそうなパラメータなどをがんばって調査していく。
ちなみに以下のようにtflearnを使わずにsklearnでLSTMを使って予測してみたのは以下。
model.add(LSTM(self.hidden_neurons, \
batch_input_shape=(None, self.length_of_sequences, self.in_out_neurons), \
return_sequences=False))
model.add(Dense(self.in_out_neurons))
model.add(Activation("linear"))
model.compile(loss="mape", optimizer="adam")
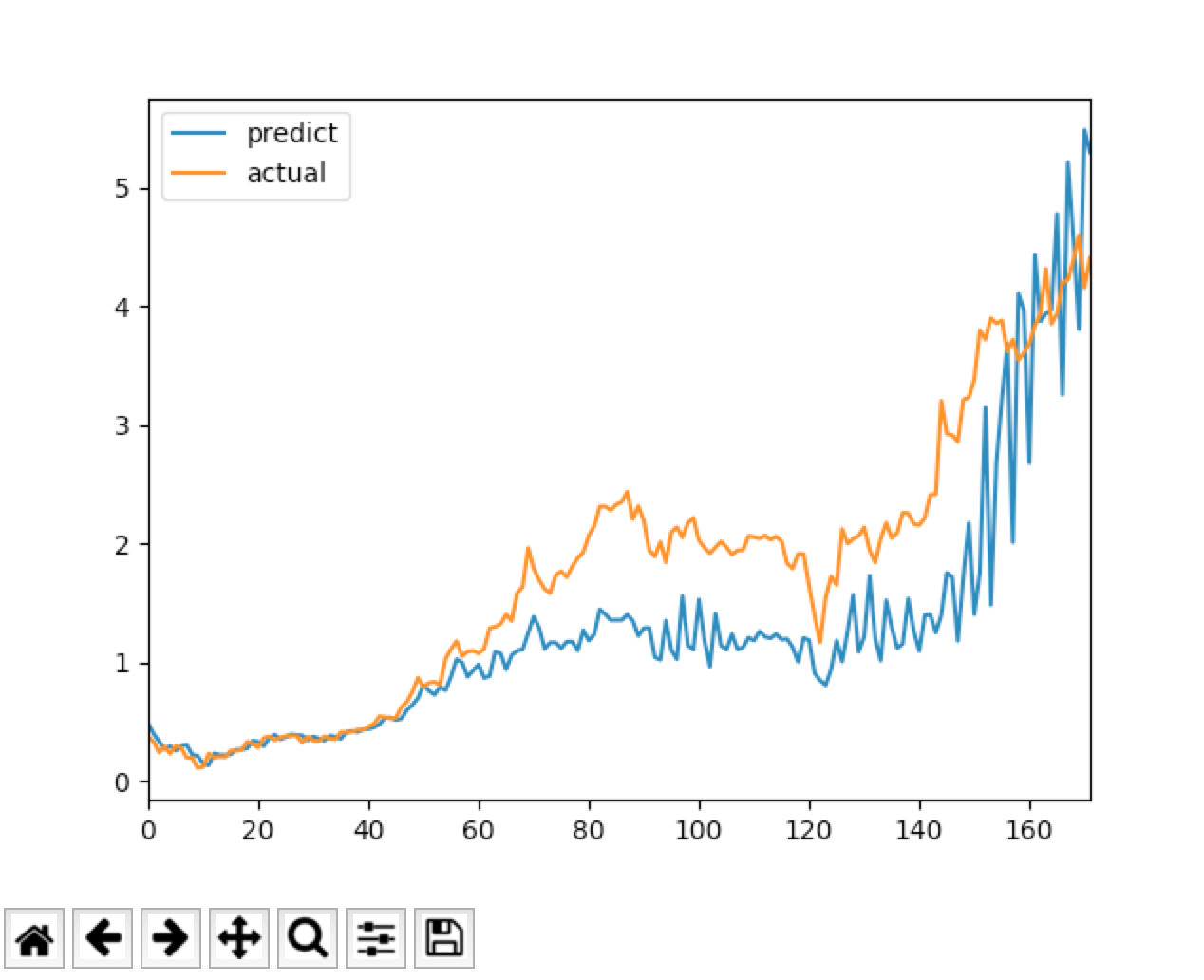
mapeはtflearnにはないけどsklearnにはあるのか・・・??とても難しい。
まとめ
とりあえず動くものはできたけど、夏休みは終わったし続きは後日。とりあえず動かせるようになったので検証方法をもっと学び精度を上げていくぞ
あと
Visual studio Code for Macがとても良かった。pythonの実装はPycham一択だと思ってたけど、とてもいいです。