■ Bluemix x Apache Spark ハンズオン資料
・Bluemix新規登録(30日間、無料枠あり)
Bluemix新規アカウント取得はこちら
※ この30日間、Bluemixと連携されている100以上のAPIやIBMのサービスがほとんど無料で使えます。
■ Open Cloud Innovation Festa 2016を開催します。
2016年9月16日(金)- 2016年9月17日(土)、二日間電気通信大学にて技術カンファレンス「Open Cloud Innovation Festa 2016」を開催いたします。
★ 今「旬」のテクノロジーや革新的なサービス一挙ご紹介 ★
オープンイノベーションを支える国内外の最新事例を始め、最先端の技術を活用しサービスを展開している企業やコミュニティの皆さまより、全32セッション(クラウド・ロボティックス・IoT・DevOps・ビックデーターなど)が予定されています。
インフラエンジニアも、開発エンジニアも、営業の方も、そうでない方も、クラウドを活用した、最新のサービスやテクノロジーに興味のある方ならどなたでも参加していただけます。イベント開催の二日間、今「旬」のテクノロジーやビジネスをお楽しみください。
・イベント申し込みはこちら
http://softlayer.connpass.com/event/34524/
・セッションの詳細や協力企業はこちら
http://open-cloud-innovation-festa.com/
ハンズオンで使うサービス
・Apache Spark - https://console.ng.bluemix.net/catalog/services/apache-spark/
・Tone Analyzer - https://console.ng.bluemix.net/catalog/services/tone-analyzer/
・Object Storage - https://console.ng.bluemix.net/catalog/services/object-storage-v1/
・Twitter App - https://apps.twitter.com/
・jupyter - http://jupyter.org/
ハンズオン手順
・Twitter Application作成 ・Spark用notebook入手 ・Tone Analyzer作成 ・BluemixのSpark設定(追加)Twitter Application生成
まず、最初に今回のハンズオンで使用するtwitterデーターを取得するため、Twitter Appを生成し、そのAppのアクセスキーを入手します。
※ Twitterのアカウントをお持ちではない方は、この手順を実施せず次の「sparkの追加」に移動してください。
・Twitterログイン後、下記のURL実行
https://apps.twitter.com/

下記の画面にて、Twitter Apps情報を入力し、APIを生成します。
Website URLは、Bluemixランタイムで構築されたアプリのURLでも良い。
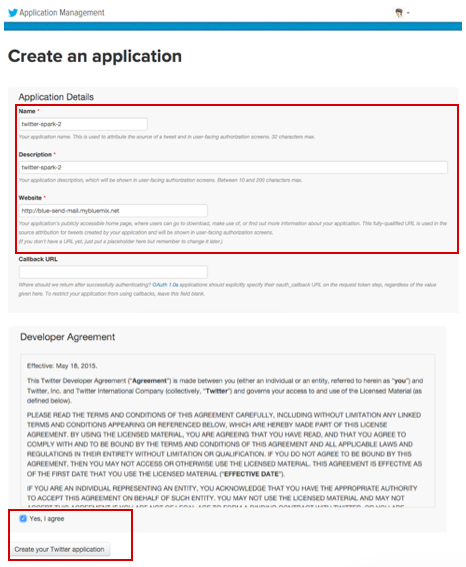
生成されたTwitter API アクセス情報を確認
① Twitter API 初期画面から「Keys and Access Tokens」タブに移動
② Consumer Key (API Key)とConsumer Secret (API Secret)を確認
③ 「Create my access token」をクリックし、トークン生成
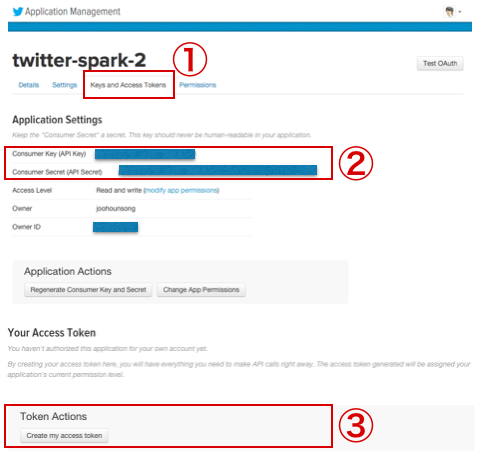
生成されたトークンが確認できます。
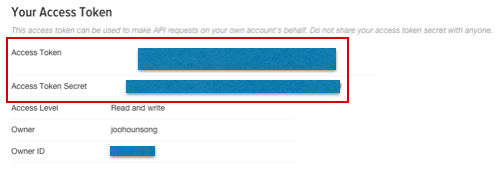
ここまで進んだら、下記の4つのキーをメモ帳などにコピーペーしてください。
・Consumer Key (API Key)
・Consumer Secret (API Secret)
・Access Token
・Access Token Secret
spark用のサンプルnotebookを入手
下記のリンクに接続してください。
https://github.com/ibm-cds-labs/spark.samples/tree/master/streaming-twitter/notebook
※ 下記の手順に従って「Twitter + Watson Tone Analyzer Part1.ipynbとTwitter + Watson Tone Analyzer Part2.ipynb」をそれぞれ実施(2回実施)してください。結果物として、2つ(Part1とPart2)の「ipynb」ファイルが入手できます。
① Twitter + Watson Tone Analyzer Part1(2).ipynbをクリック
② Rawをクリック
③ ページを別名で保存
※ ダウンロードされたファイルの拡張子が「ipynb」かを確認し、
違う場合は拡張子を「ipynb」に変更
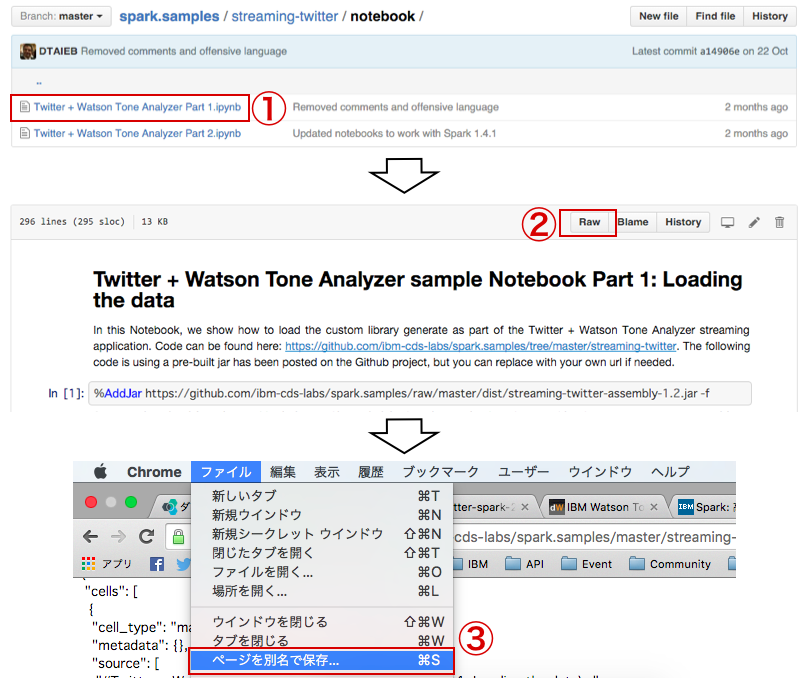
下記のようにローカルに「ipynb」ファイルがあれば次に進みましょう。

Tone Analyzer作成
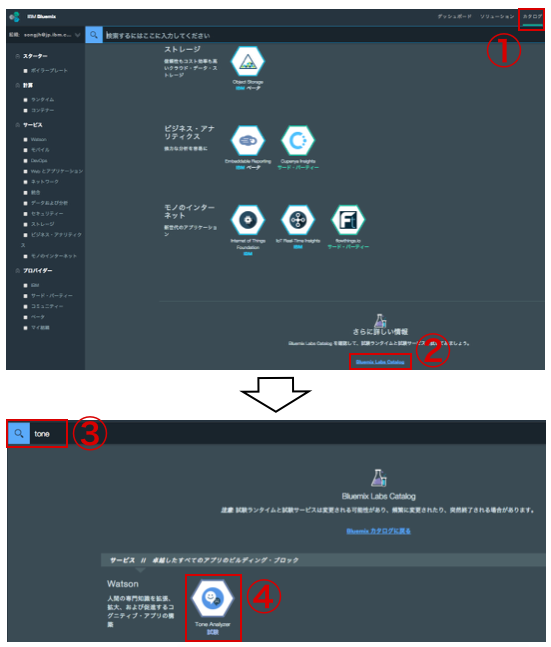
① カタログ
② 「Bluemix Labs Catalog」クリック(カタログ画面の一番下)
③ 検索バーにて「tone」を入力
④ Tone Analyzer選択
・Tone Analyzerのアクセスキー情報を取得
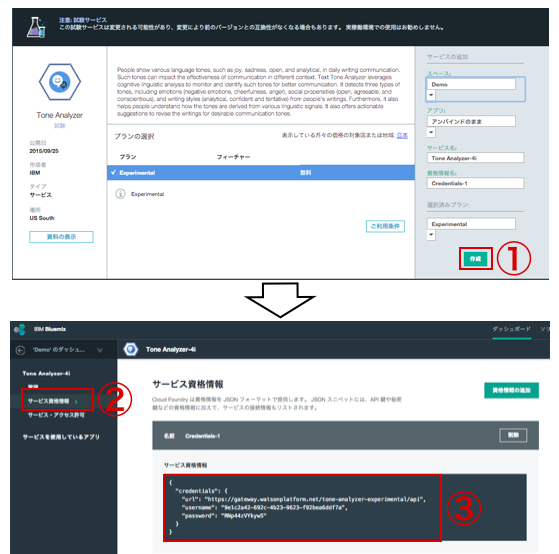
① 情報確認の後、「作成」クリック
② サービス資格情報クリック
③ 資格情報が表示されたら、下の3つの情報をテキストエディターなどにコピーペー。
・url
・username
・password
sparkの追加
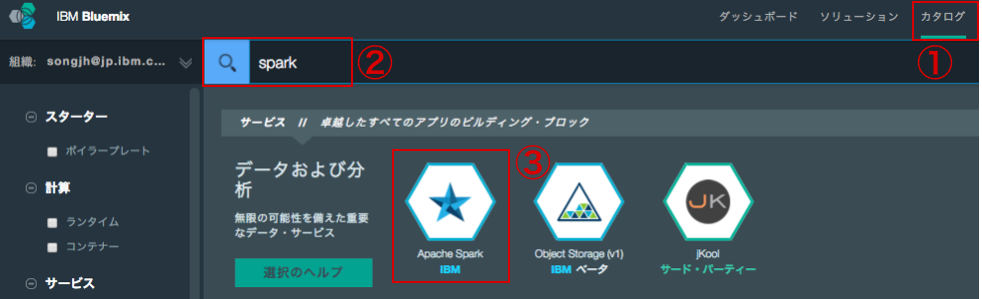
① カタログ → ② 検索バーに「spark」入力 → ③ Apache Spark選択
Spark作成
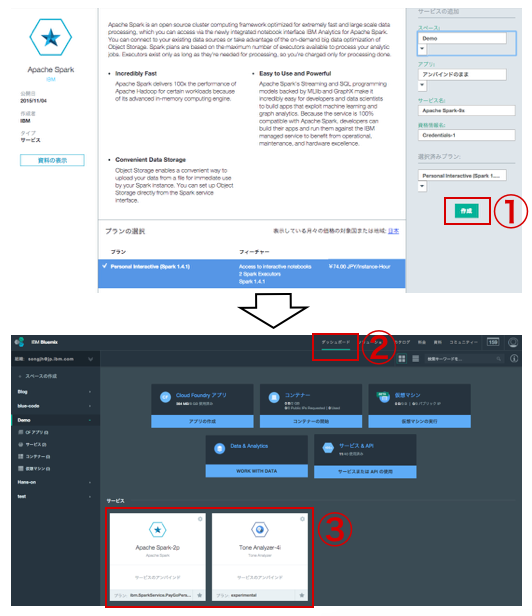
① Sparkの情報(スペース・アプリ・サービス名・資格情報名・プラン)を確認し
「作成」クリック、それぞれの情報は変更可能だが、デフォルトでも良い。
② 「ダッシュボード」へ移動
③ 作成済みの、「Apache SparkとTone Analyzer」が確認できる。
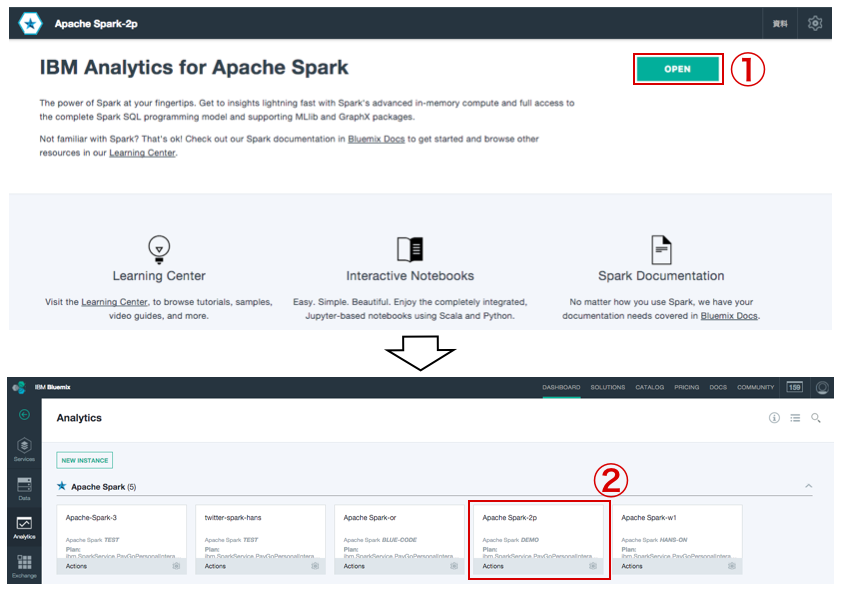
Sparkの設定を始める
※ 上記の画面(ダッシュボード)の「Apache Spark」をクリック
①「OPEN」をクリック
② 先ほど追加されたSparkのサービス名をクリック(今回は、Apache Spark-2p)
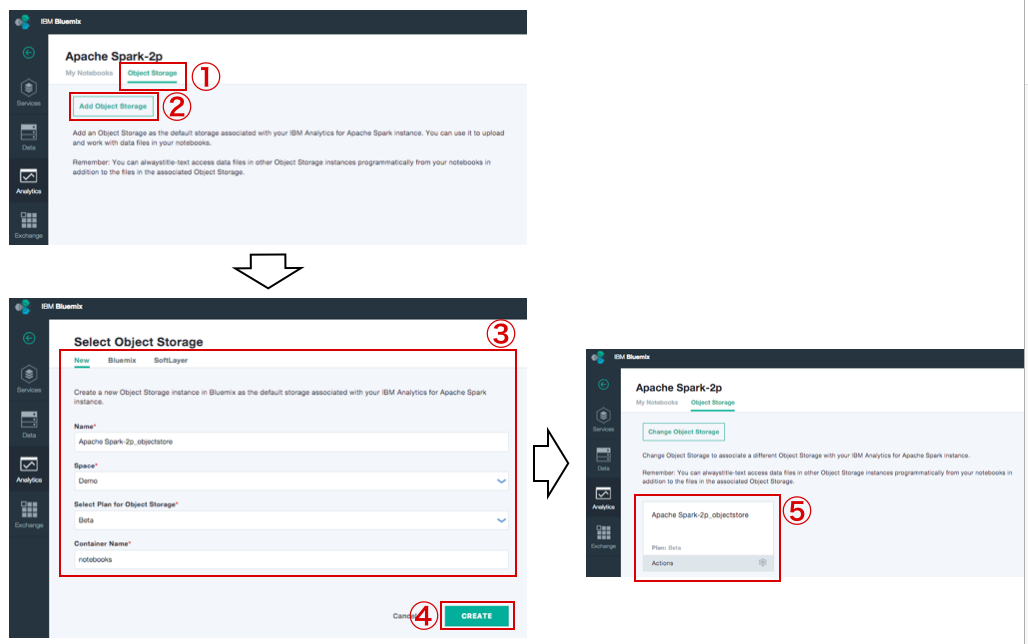
Object Storageを追加
① Object Storage クリック
② Add Object Storage クリック
③ New → 内容入力
・Space情報などに間違いがあるかを確認してください。
・3番目の項目「Select Plan ~」では、「Free」を選択します。
④ 内容確認後、CREATE クリック
⑤ 生成された「Object Storage」が確認できる。
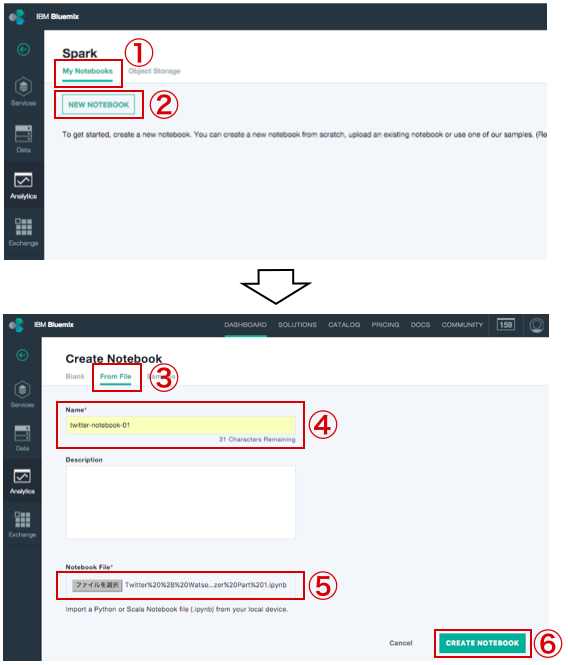
jupyter Notebookを作成
Notebookに設定する、TwitterやTone Analyzerのキーセット作成

・下記のテキストをコピーペーして、「XXXXX」の部分を埋めてください。
val demo = com.ibm.cds.spark.samples.StreamingTwitter
demo.setConfig("twitter4j.oauth.consumerKey","XXXXX")
demo.setConfig("twitter4j.oauth.consumerSecret","XXXXX")
demo.setConfig("twitter4j.oauth.accessToken","XXXXX")
demo.setConfig("twitter4j.oauth.accessTokenSecret","XXXXX")
demo.setConfig("watson.tone.url","XXXXX")
demo.setConfig("watson.tone.password","XXXXX")
demo.setConfig("watson.tone.username","XXXXX")
Notbook1を作成
※ 注意
Notebookの実行は、一行の処理が終わってから次に進みましょう。
処理が行なわれている間は、「[数字]」の部分が「*(アスタリスク)」になり、処理が終わったら数字に変わります。
① My Notebooksをクリック
② NEW NOTEBOOKをクリック
③ From Fileをクリック
④ Neme 入力
⑤ ファイルを選択で、先ほど「spark用のサンプルnotebookを入手」で
作成した「Twitter + Watson Tone Analyzer Part1.ipynb」を選択。
⑥ CREATE NOTEBOOKをクリック
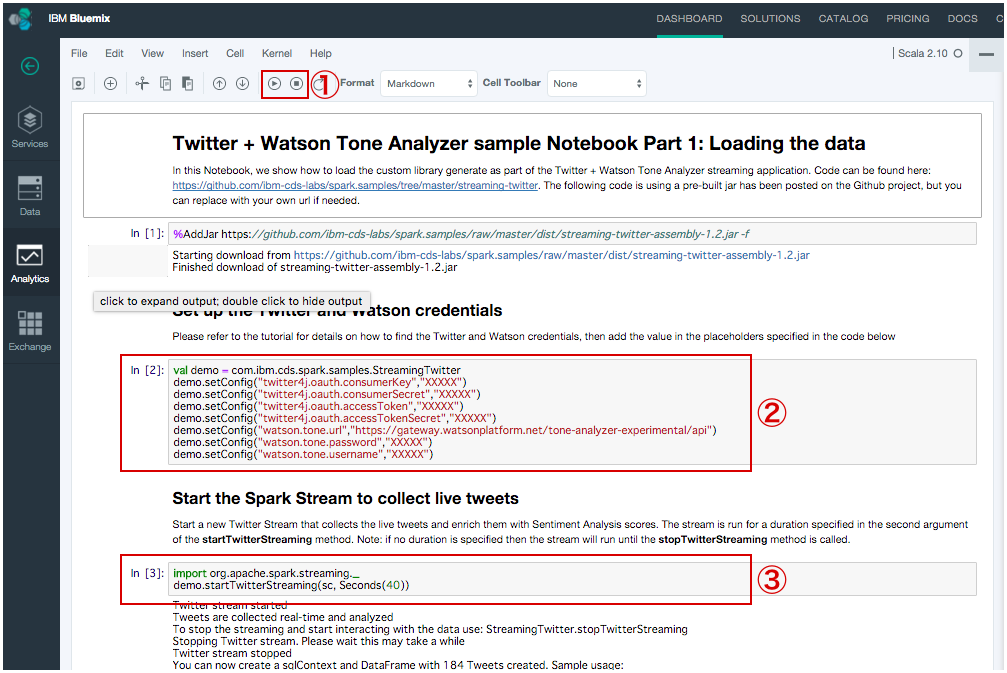
上記の作業を完了すると、下記のNotebook画面が表示されます。
① 「PLAY」アイコンで1行ずつ、実行していきます。
「STOP」アイコンで実行を止めることができます。
② 上記の「Twitter Application生成」で生成された、Twitterのアクセスキーと「Tone Analyzer作成」で生成された、Tone Analyzerのアクセス情報を設定します。
③ コードに設定されている時間間データーを取得するので、処理が終わるまで待ちます。
この部分は、TwitterStreamからデーターを取得します。
処理の途中に「*(アスタリスク)」が数字に変わり、処理が終わっているように
見えるが、最終的に検索されたデーターの件数が表示されるので、検索データーの数字が
出力されるまで待っていてください。
処理が終わっていない状態で次に進むとエラーになるので要注意です。
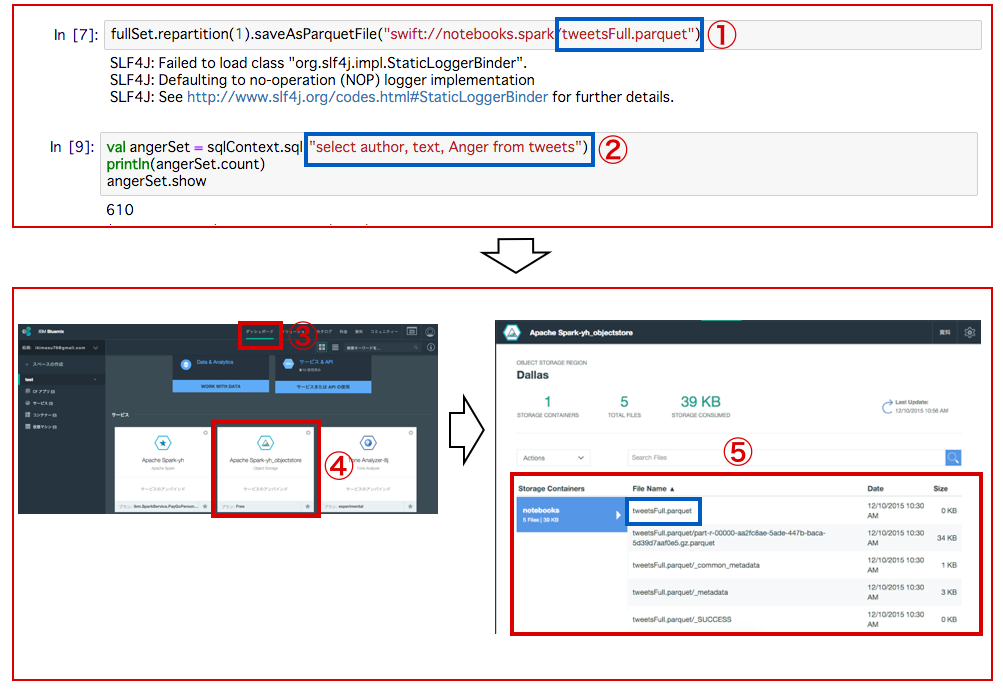
・Notebook1では、Object Storageにデーターを保存します。
① 「tweetsFull.parquet」のファイル名で保存する。(変更可)
② 保存されたファイル(データー)をセレクトしてみます。
③ Object Storageにデーターがどのように生成されているのかを確認してみましょう。
「ダッシュボード」をクリックします。
④ Object Storageをクリック
⑤ Notebook1で生成した、ファイル名で「Notebook」が保存されているのが確認できる。
Notebook2を作成
手順は、「Notebook1を作成」と同じですが、手順⑤のファイル選択で「Twitter + Watson Tone Analyzer Part2.ipynb」を選択してください。
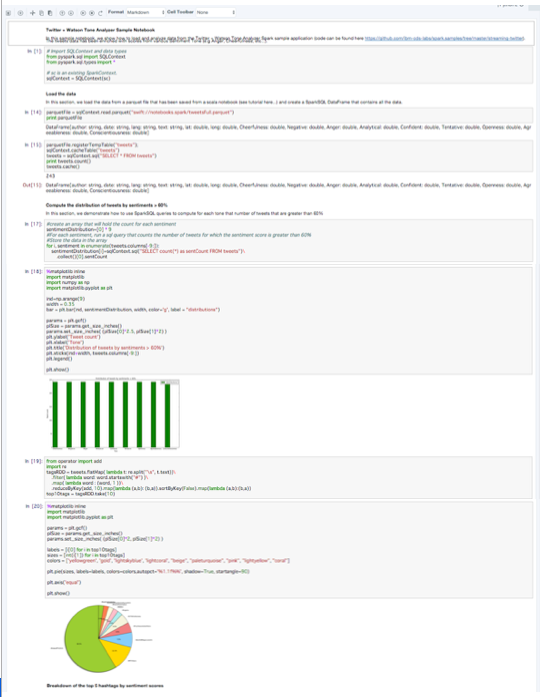
Notebook2では、「Notebook1」で入手されたデーターを使ってデーターを可視化します。
「Notebook1」と同じく一つずつ実行していてください。Notebookのクエリなどを変えながら実行していくと、違う形のグラフを表示することができます。
Bluemixコミュニティ
※ Bluemixに関する技術関連情報や最新情報、イベント告知、Bluemixユーザーコミュニティの皆さんからの最新記事などを配信しています。
下記のリンクから「Bluemix」の「今」をフォローできます!
・Facebook : Bluemixユーザーグループ
・Qiita : Bluemix Qiitaページ
・Slack : Bluemix User Group(BMXUG)の交流用
・stackoverflow : stackoverflow(コミュニティQ&A)
・Twitter : @ibm_ecod_japan