いきなりですが以下はenebular.comの2014年5月のWebアーカイブです。
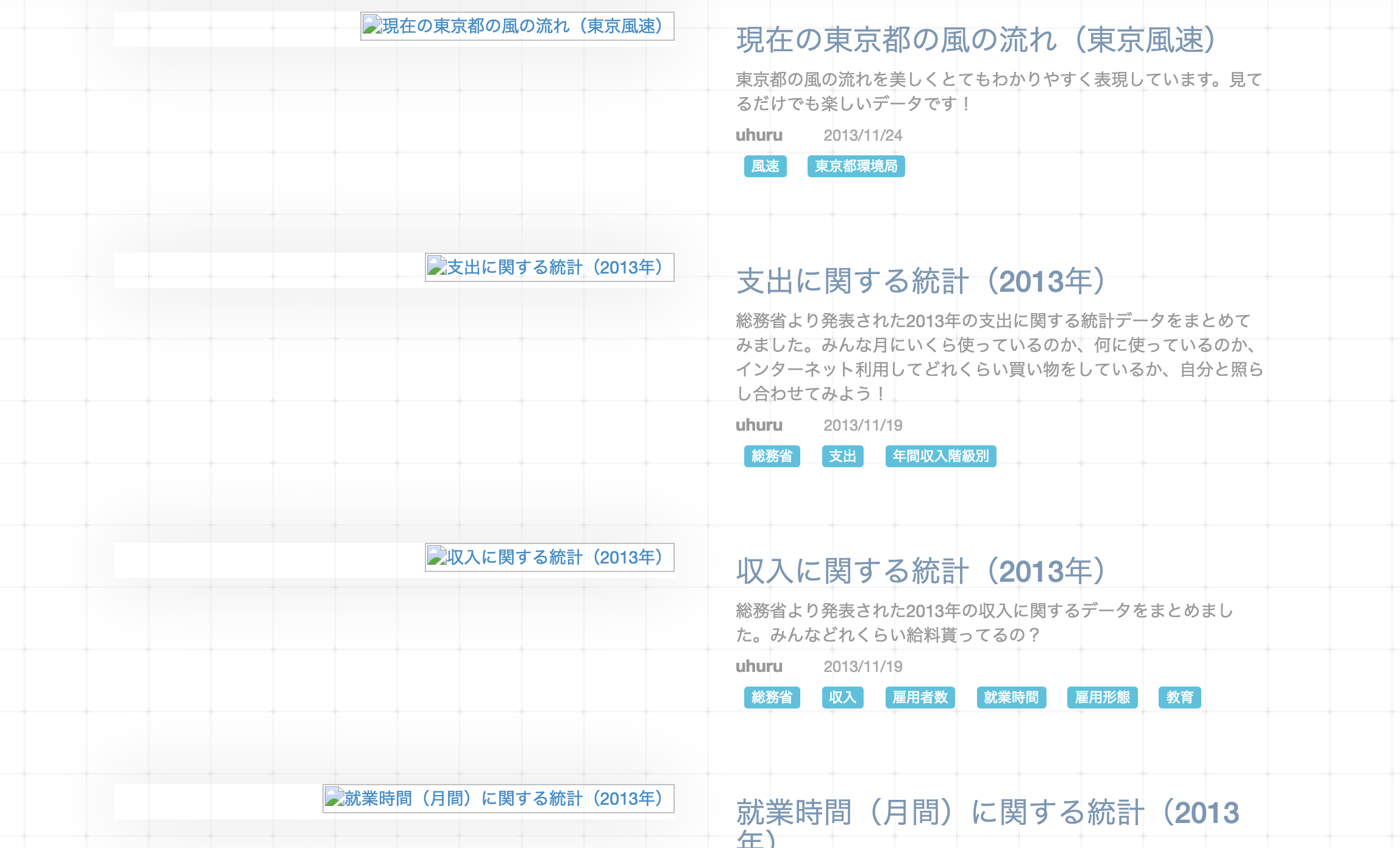
実はこれ、enebularのINFOMOTIONがNode-RED補完機能より先に構想されていた残骸なんです。
enebularの初期コンセプト
enebular.comドメイン情報を見ると2013年10月8日にドメインを取得しています。もちろんウフルが取得していますが、この頃に以下のコンセプトのサービスをやろう、ということで取得しました。
当時、LOD Challenge 2013に応募するためにまとめた資料。

- オープンデータを簡単に持ってこれる
- 簡単にデータ加工したり統合できる
- 簡単にビジュアライズできる
- 作ったビジュアライゼーションを簡単に共有できる
これは現在も変わっていませんが、当時はD3とか使ってビジュアライゼーション(可視化)の方を先に作って、まずはこういうことやるサービス(サイト)なんだよ、と公開しておきたいね(せっかくドメインもとってるしね)という感じで上記のようなトップページになってました。
ただ、今考えるとコレだけ表示されていても上記コンセプトが伝わるわけでもなく、なんだこりゃってなってしまっていたと思います。あと、よくあるグラフ並べただけなら似たようなもの結構あるよね?という意見も多数ありました。
簡単にデータを持ってきて加工や統合ができる?
当時のチームの中で私はビジュアライゼーション(可視化)以外のコンセプトをどう実現させるか頭を悩ませていました。
「オープンデータを簡単に持ってこれる」ということはデータの提供元への接続情報や接続手段をパッケージングしたものをプラグイン方式で扱えるようなものなんだろうな...「データを加工したり統合する」には表形式でデータを扱えてクエリもかけられるようなものなんだろうな...とか。
APIプラグイン的な何かは自前で作ったほうが良いなと考えてました。どっちかというとデータマネジメント的な何かはOSSでありそうということでSqlPadベースなどで実現できないか検証していました。
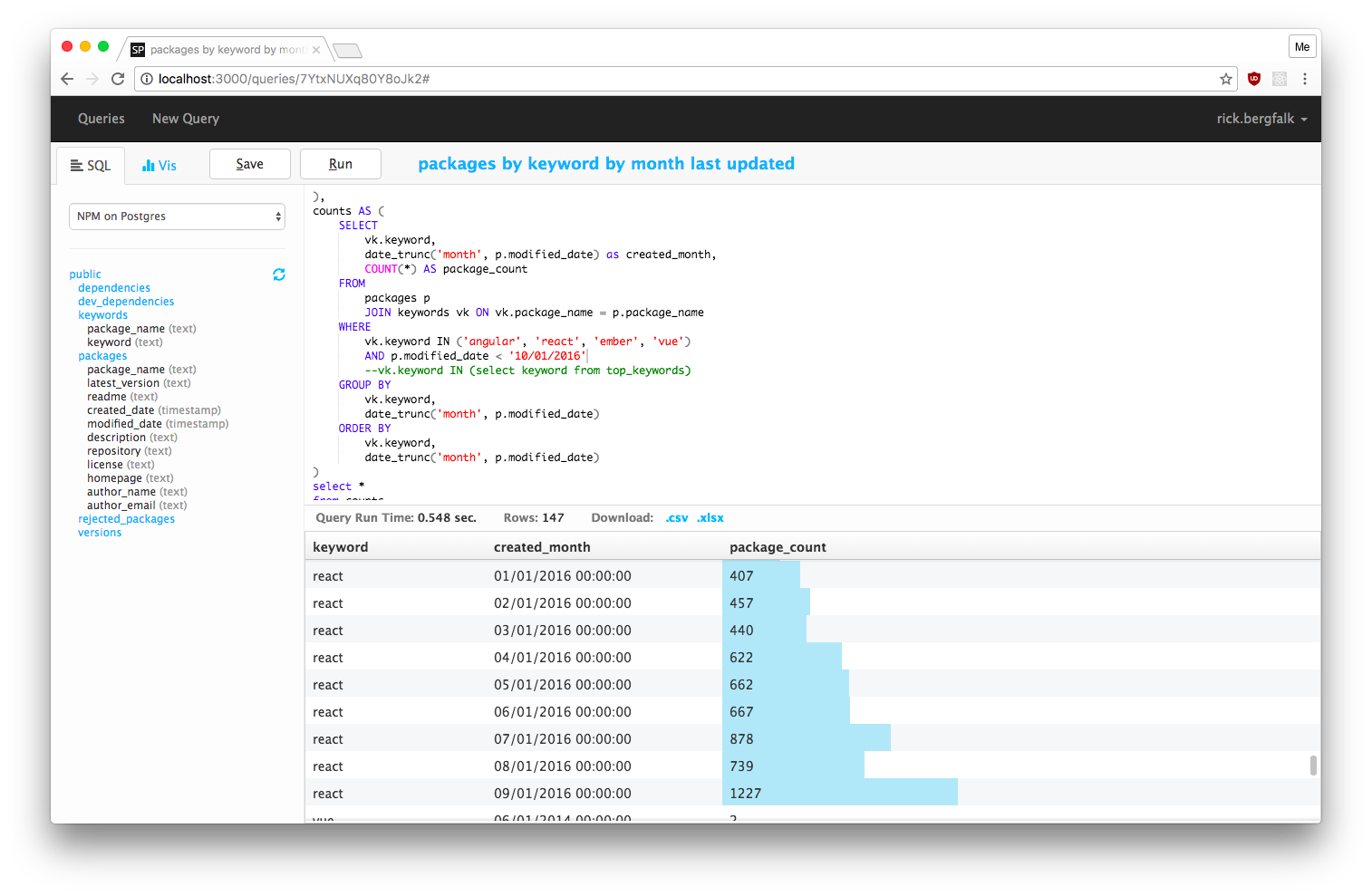
ストリームデータ処理の必要性
色々なプロダクトを検証した結果、採用に至らなかった大きな要因にストリームデータ処理の取り扱いに長けたものがなかった点があります。
ソーシャルデータやIoTによるストリームデータの急増でTreasureDataを利用したりしてましたが、それ以前に必須なのはストリームデータ処理だと思っていたからです。
当時はNorikraのようなCEP的なものの必要性が認識されて流行りだしていたので、やはりそういったものをコアにして自前でAPIプラグイン的なものを構築しようかとという方向になっていました。
あと、ストリームデータ処理の文脈からPub/Sub的なものの必要性も感じていましたのでメッセージブローカ系も何か取り込まないといけないなという感じでした。
この辺が揃ってくると「よくあるグラフ並べただけなら似たようなもの結構あるよね?」という意見に対しても、これまでにないビジュアライゼーション体験を提供できるようになるだろう、そして検討しているそれぞれがその技術的根拠になるだろうと漠然と考えていました。
そんな時にNode-REDと出会う
メッセージブローカの調査のために参加したMQTT Meetup Tokyo 2014.08のIBM鈴木さんのプレゼンでNode-REDがチラッと見えました。上記のようなことで頭がいっぱいだったので即検索してOSSであることを知りました。
すぐに動かして検証して正に「これはAPIプラグイン的な何かだ」と思いました。最初はそれだけでも良かったんですが使っていくうちに「ある程度のストリームデータ処理も全然いける」「ストリームデータ処理的なアプローチではあるけどデータの加工や統合もできなくはない」というポテンシャルを感じました。
これはすぐにユーザに使ってもらって価値を検証した方が早いなと思って11月にNode-REDをホスティングしただけのβ版をリリースしました。
リリースすると同じようにポテンシャルを感じていただける方が多く、ウフル、三井物産エレクトロニクスとIoT分野での協業を発表 〜 IoT分野における事業開発を早期に実現 〜 から クラウド事業を含むIoTビジネスのさらなる拡大に向けて 資金調達を実施 は大きな成果でした。
そして、元々最初に着手したはずだったビジュアライゼーション機能の開発に移行します。
※並行してNode-REDユーザ会も運営しています!
enebular Marketing Intelligence
この頃から社内の他の部門から「簡単にデータ統合ができると聞いて」という相談が増えます。主にデジタルマーケティング領域のお話です。
デジタルマーケティングの領域では様々なデータが散在していて、人手でデータ収集から統合や集計を行っていることが多く、これを以下のように自動化できるのではないか?というニーズでした。

そこから、あるモニタ的な顧客のフラグシップ案件が始まり、私もオブザーバ的に支援して、ある程度形になった段階でウフル、IoT×マーケティングを実現する 「enebular Marketing Intelligence」販売開始 を発表します。
並行してenebularプロジェクトにおいても、enebular Marketing Intelligenceをプラガブルに汎用的に誰でも利用できるような機能としての組み込みが進みます(というかenebularって元々これがしたかったんだよね)
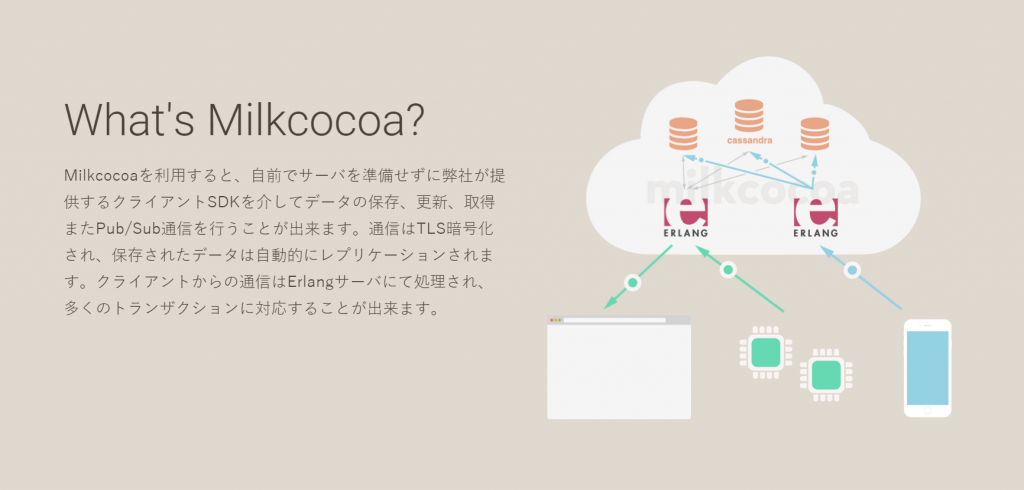
Milkcocoa
enebular Marketing Intelligenceは時系列データを表現するコンセプトなんですが、これをするためにPub/Sub的な何かを自前で持つことの重要性を感じていましたし、enebularプロジェクトとしても前述の通りメッセージブローカの必要性を感じていました。
MeshbluなどのOSSやSalesforceとのアライアンスの関係でXivelyを検討していたのですが、Milkcocoaの実現している使いやすさと、すぐに意見を反映してくれそうなカジュアルな開発体制に惹かれてアライアンスの話をさせていただきました。
その結果、IoTプラットフォーム「Milkcocoa(ミルクココア)」サービス事業の事業譲受に関する基本合意のお知らせにより、上記の両方の課題を巻き取ってくれるような華麗なジョインでした!
そしてリリース
この後は本当に作るだけで、クローズドβを経て今年の11月にINFOMOTIONがリリースされました!

まとめ
enebularは元々INFOMOTIONを先に作ろうと思ってたのに紆余曲折あって今のタイミングになってしまいましたが、その結果より良いものが出来上がったのではないかと思っています。
特に今年の2月からジョインいただいているTechnical Rockstarsの皆さんの技術力のおかげです!大感謝です!