概要

スパムレビュア発見アルゴリズムの評価用に,
論文 A Bipartite Graph Model and Mutually Reinforcing Analysis for Review Sites にて作成した
人工データを公開しました.本記事では使い方をまとめます.
また,Google Cloud Platform を使った並列評価についてもまとめます.
インストール
パッケージは PyPI に登録してあるので,pip コマンドでインストールできます.
$ pip install --upgrade rgmining-synthetic-dataset
人工グラフデータの読み込み
rgmining-synthetic-datasetには,syntheticパッケージが含まれており,
synthetic.load関数とsynthetic.ANOMALOUS_REVIEWER_SIZE定数をエクスポートします.
synthetic.load関数は人工レビューグラフデータの読み込みを行い,
synthetic.ANOMALOUS_REVIEWER_SIZE定数はこのデータセットに含まれている
特異なスパムレビュアの人数(57)を表しています.
特異なスパムレビュアは,その名前に anomaly が含まれています.
よって,このデータセットを使った評価では,
57人のスパムレビュアをどれだけの精度・再現率で発見できるのか?を調べます.
なお人工データがどのようにして作られたのか,については割愛します.
興味のある方は元論文を参照してください.(いつか別記事でまとめるかも知れません)
synthetic.load関数は,引数としてグラフオブジェクトを受け取ります.
このグラフオブジェクトは,
-
new_reviewer(name):nameという名前を持つレビュアーオブジェクトを作成して返す. -
new_product(name):nameという名前を持つ商品オブジェクトを作成して返す. -
add_review(reviewer, product, rating):reviewerによるproductへのスコアがratingであるレビューを追加する.なお.ratingは 0 以上 1 以下に正規化されているものとする.
という三つのメソッドを持っている必要があります.
先日紹介した Fraud Eagle はこの条件を満たしています.したがって,
import fraud_eagle as feagle
import synthetic
graph = feagle.ReviewGraph(0.10)
synthetic.load(graph)
とすれば,Fraud Eagle アルゴリズムを使ってこの人工データの解析が行えます.
実際の解析
Fraud Eagle はパラメータを一つ取るアルゴリズムだったので,
どのパラメータがこの人工データセットに適しているのか調べてみます.
今回は,簡単にanomalous_scoreが高いトップ 57人のうち,
実際に特異なスパムレビュアだった割合を使って評価します.
(この割合が高い方が正しく特異なスパムレビュアを発見できたことになります.)
# !/usr/bin/env python
import click
import fraud_eagle as feagle
import synthetic
@click.command()
@click.argument("epsilon", type=float)
def analyze(epsilon):
graph = feagle.ReviewGraph(epsilon)
synthetic.load(graph)
for _ in range(100):
diff = graph.update()
print("Iteration end: {0}".format(diff))
if diff < 10**-4:
break
reviewers = sorted(
graph.reviewers,
key=lambda r: -r.anomalous_score)[:synthetic.ANOMALOUS_REVIEWER_SIZE]
print(len([r for r in reviewers if "anomaly" in r.name]) / len(reviewers))
if __name__ == "__main__":
analyze()
コマンドラインパーサには click を使いました.
$ chmod u+x analyze.py
$ ./analyze.py 0.1
とすれば,パラメータを 0.1 として実験ができます.出力は,
$ ./analyze.py 0.10
Iteration end: 0.388863491546
Iteration end: 0.486597792445
Iteration end: 0.679722652169
Iteration end: 0.546349261422
Iteration end: 0.333657951459
Iteration end: 0.143313076183
Iteration end: 0.0596751050403
Iteration end: 0.0265415183341
Iteration end: 0.0109979501706
Iteration end: 0.00584731865022
Iteration end: 0.00256288275348
Iteration end: 0.00102187920468
Iteration end: 0.000365458293609
Iteration end: 0.000151984909839
Iteration end: 4.14654814812e-05
0.543859649123
となっていたので,トップ 57人のうち約54%が特異なスパムレビュアだったようです.
クラウドで最適パラメータの調査
先ほどはパラメータを 0.1 に設定しましたが,他の値で結果は変わるのか.複数の値に対して調べてみます.
基本的には上記のスクリプトをパラメータを変えて一つずつ実行して行けば良いのですが,
時間がかかりそうなのでGoogleのクラウドを使って並列に実行します.
Googleクラウドの利用には,もっと簡単にGoogleCloudPlatformを使う で紹介したツール roadie を使います.インストール及び初期設定方法は上記の記事を参考にしてください.
まず,先ほど作成した analyze.py の実行に必要なライブラリを requirements.txt に列挙します.
click==6.6
rgmining-fraud-eagle==0.9.0
rgmining-synthetic-dataset==0.9.0
そして,roadie 実行用のスクリプトファイルを作成します.
run:
- python analyze.py {{epsilon}}
今回は外部データファイルや apt パッケージなどは必要ないので,
シンプルに run コマンドのみ記述します.{{epsilon}} の部分はプレースホルダで,
インスタンス作成時に引数として渡します.
また,今回は多くのインスタンスを作成する予定なので,キューを使います.
まず初めに,ソースコードのアップロードも兼ねて,一つ目のタスクを実行します.
$ roadie run --local . --name feagle0.01 --queue feagle -e epsilon=0.01 analyze.yml
一つ目はパラメータを 0.01 に設定しました.
-e epsilon=0.05 で,analyze.yml の {{epsilon}} に値を設定しています.
次に,残りのパラメータについてタスクを実行します.
$ for i in `seq -w 2 25`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.${i}" \
--queue feagle -e "epsilon=0.$i" analyze.yml
done
—source feagle0.01.tar.gz で最初にアップロードしたソースコードの利用を指定しています.
また,このように roadie run コマンドに —queue <name> を渡すと
<name>というキューにタスクを追加していきます.(参考)
デフォルトでは,一つのインスタンスでキューを処理しているので,
並列で実行する場合はインスタンスを起動する必要があります.
今回は,とりあえず合計 8台ほどで実行してみます.
1台はすでに起動しているので,残り7台を起動させます.
$ roadie queue instance add --instances 7 feagle
各インスタンスの実行状況は,
$ roadie status
で調べられます.キューの名前 + ランダムな数字がそのキューを処理しているインスタンス名になります.
ステータスが表示されなくなれば無事終了です.
実行結果は Google Cloud Storage に保存されているので,
次のコマンドで取得し,CSV ファイルに書き出します.
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result.csv
done
roadie result show <task name> で各タスクの出力を取得できます.
得られた CSV をプロットしてみましょう.
# !/usr/bin/env python
import click
from matplotlib import pyplot
import pandas as pd
@click.command()
@click.argument("infile")
def plot(infile):
data = pd.read_csv(infile, header=None)
pyplot.plot(data[0], data[1])
pyplot.show()
if __name__ == "__main__":
plot()
かなり簡易的ですが,プロトタイプとしてはこれで良いでしょう.
$ chmod u+x plot.py
$ ./plot.py result.csv
手元の結果は次の通りになりました.
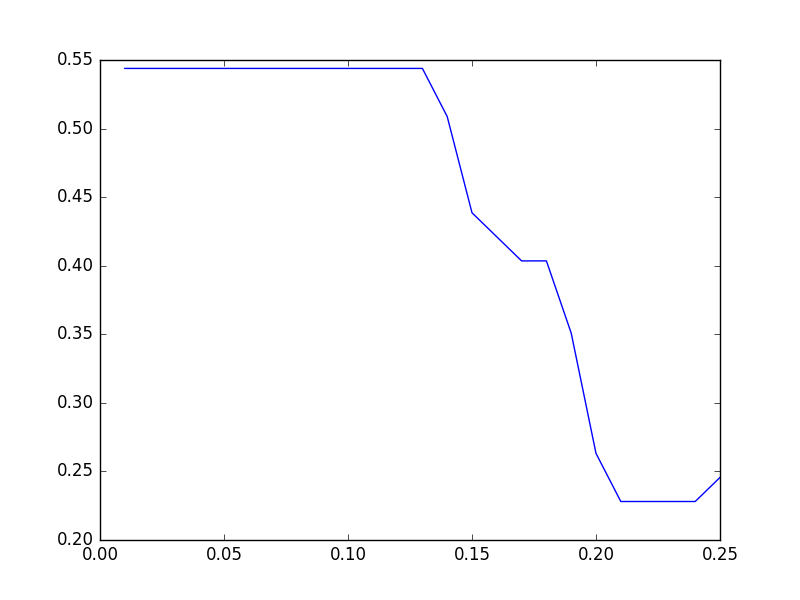
0.01から0.13はフラットになっているので,もう少し小さい値でも調べてみます.
先ほどと同様にキューにタスクを入れ,8並列で実行します.
$ for i in `seq -w 1 9`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.00${i}" \
--queue feagle -e "epsilon=0.00$i" analyze.yml
done
$ roadie queue instance add --instances 7 feagle
実行が終われば,下記のように CSV を作成しプロットします.
$ for i in `seq -w 1 9`; do
echo “0.00${i}, `roadie result show feagle0.00${i} | tail -1`" >> result2.csv
done
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result2.csv
done
$ ./plot.py result2.csv
結果は次のようになりました.Fraud Eagle では約54%がベストのようです.
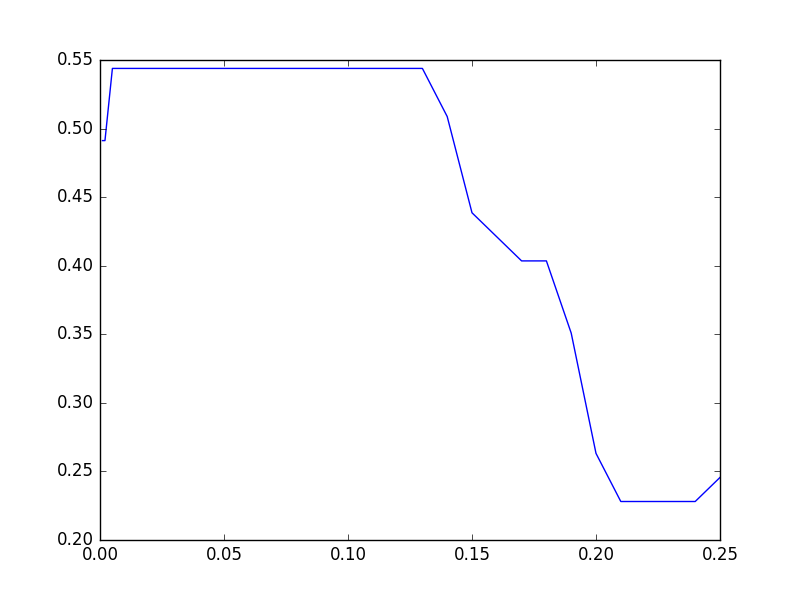
ところで,実はパラメータが 0.01 付近ではアルゴリズムは収束せず振動しています.
例えば,0.01の場合,出力は
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
のようになっています.なお今回は 100ループで打ち切っています.
元論文の方には収束条件についての話はなかったような気がするので,
もう少し詳しく調べてみる必要がありそうです.