以下のことについて知りたい人向けの記事。
①機械学習の利点と欠点、TensorFlowの利点と欠点
②ニューラルネットワークの原理についての簡潔な説明
(オンライン書籍:http://nnadl-ja.github.io/nnadl_site_ja/index.html
をまとめたもの)
③TensorFlowのチュートリアルに沿ってプログラム作成、その実行結果
以下、参考にしたサイト
1次関数の近似:
https://www.tensorflow.org/versions/master/get_started/index.html
http://qiita.com/MATS_ELB/items/fec7f54de2dd18b043ae
n次関数の近似:
http://msyksphinz.hatenablog.com/entry/2015/11/19/085852
手書き数字画像認識:
http://tech.mof-mof.co.jp/blog/tensorflow-tutorial.html
http://blog.amedama.jp/entry/2016/02/08/204551
④TensorFlow以外のライブラリとの比較
以下の構成で記述する。
1.結論の提示
2.背景
3.目的
4.関連知識・原理・方法の解説
5.実証実験/文献探索
6.考察(結果の解釈)
7.まとめ(結論の再提示)
///追記
この記事の内容を膨らませたものを本にしました。
TensorFlowを使った 「ニューラル・ネットワーク」の構築法
http://www.kohgakusha.co.jp/books/detail/978-4-7775-2058-9
※自著のURLを載せることはQiitaの規約に違反しないとQiitaさんに問い合わせで確認しています。ただし「読者に違和感のないようにしてね」と言われました。後でなんとかするので、今はこの追記という形で載せさせてください。以上です。
///
1.結論
1-1.ニューラルネットワークの利点と欠点
ニューラルネットワークの利点と欠点を以下に述べる
利点
①あらゆる関数を近似できる(あらゆる問題にある程度確からしい解を答えられる)
欠点
①大量の処理が必要である
CPUのみだと明らかに速度が足りない。
②開発には特別な知識が必要である
多次元行列(テンソル)の表現と計算についての深い知識が必要である。画像処理、音響処理などになると、その分野の専門知識が必要である。
③機械学習分野の専門学者の経験則によって採用されるアルゴリズムが多い
長年の研究の結果によって採用されたアルゴリズム(コスト関数など)が多い。これからもそのような新しいアルゴリズムが開発されると予想される。解決したい問題ごとに適したモデルがあるが、中には「何故かはわからないけど、うまくいった」モデルもあるようなので、新しくかつ複雑なモデル設計は手探りでしなければならないという側面がある。
1-2.TensorFlowの利点と欠点
TensorFlowの利点と欠点を以下に述べる。
利点
①モデル設計が簡単でコード記述も簡潔に書ける
②商用フリーのライセンスであるため、機械学習システム導入のコストを抑えられる
③学習がし易い
④導入しやすい
欠点
①ほとんどの処理がブラックボックスである
関数の処理フローが明確でない。エラーを動作原理まで遡って特定することができない。
②Windowsに対応していない
追記:バージョン0.12からWindowsに対応しました。
以下はGoogle Developers Blog の記事 "TensorFlow 0.12 adds support for Windows"の翻訳です。
今回の TensorFlow r0.12 のリリースに合わせて、Windows 7、10、Server 2016 向けのネイティブ TensorFlow パッケージを提供します。このリリースでは、CUDA 8 対応の GPU で TensorFlow トレーニングを高速化できます。
2.背景
ニューラルネットワークと深層学習は、現時点において、画像認識、音声認識、自然言語処理などの分野の問題に対して、もっとも優れた解決策を与える手法である。
例えば画像認識に注目すると、従来の画像認識技術に、認識したいものの特徴を人が見つけ、プログラムに記述する手法がある。しかし、この手法には以下の問題点がある。
①画像認識に有効な画像の特徴を人が見つけなければならない
②各特徴を認識するためのアルゴリズムを個別に開発しなければならない
③画像認識の試験のための、大量のデータセットの用意が必要である
近年、このような問題を解決するために、人間の脳の仕組みを模倣した人工知能、ニューラルネットワークと深層学習の技術の研究が盛んに行われている。
各企業が人工知能の開発競争に加わっている中、株式会社Googleが自社開発した人工知能である、機械学習システム「TensorFlow」を商用利用も可能なフリーライセンスであるApache 2.0でオープンソース化した。これにより、TensorFlow利用者にとって、以下の利点が考えられる。
①フリーライセンスにより機械学習システム導入のコストを抑えられる
②フリーライセンスにより、全世界で便利なライブラリの開発が盛んに行われ、利用できる
③フリーライセンスにより、参考文献、知識の共有が盛んに行われ、TensorFlowを利用した、機械学習を学ぶための環境が整えられる
以上の利点を踏まえ、TensorFlowには多大な将来性があると判断した。よって、TensorFlowの学習と、評価をすることにした。
3.目的
TensorFlowを学習し、その利点と欠点を明らかにする。
4.関連知識・原理・方法
4-1. ニューラルネットワーク
ここで、ニューラルネットワークと深層学習について説明する。
まず、ニューラルネットワーク技術は人間の脳を模倣したものである。人間の脳の中にはニューロンという神経細胞が千数百億個あり、各ニューロンがシナプスと呼ばれる接合部位によって繋がっている。ニューロンは入力される電気信号の閾値がある一定の量を超えると発火し、シナプスによって次のニューロンに電気信号を出力する。この動作の連続により、脳は信号の伝達を行っている。このニューロンを模倣した人工ニューロンのモデルを図1に示す。
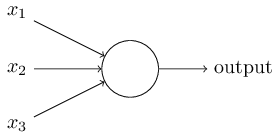
図1 人工ニューロン
この人工ニューロンはシグモイドニューロンと呼ばれるものである。シグモイドニューロンはそれぞれの入力に対して、重み(w 1 ,w 2 ,… )を持ち、またニューロン全体に対するバイアスと呼ばれる値(b)を持っている。出力は
σ(w⋅x+b)
という値をとる。σはシグモイド関数と呼ばれており、次の式で定義される。
σ(z)≡1/(1+e^(−z)) ...(1)
σのグラフを次の図2に示す。
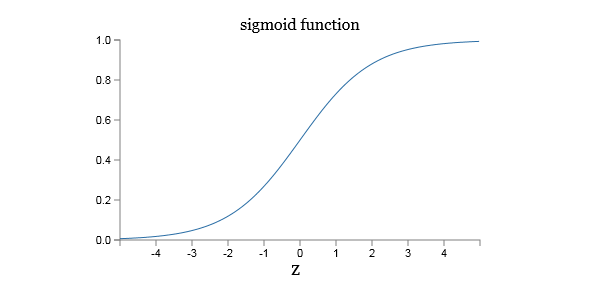
図2 シグモイドニューロン
これにより、シグモイドニューロンの出力は0~1の間の数値をとる。
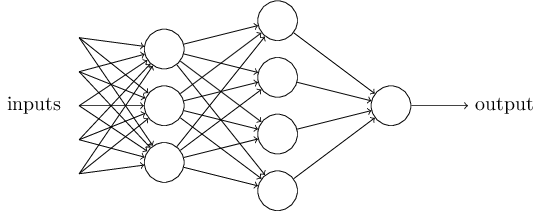
この人工ニューロンを無数に組み合わせることにより、ニューラルネットワークを形成する。ニューラルネットワークのモデルを図3に示す。
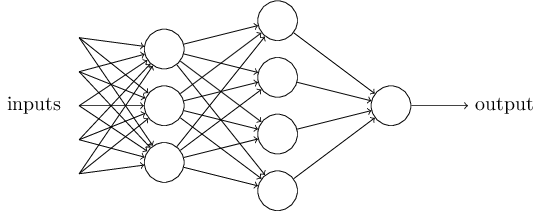
図3 ニューラルネットワークのモデル
最後の出力も0から1の間の値をとるため、ルールを設定する必要がある。例えば、「入力画像が9」もしくは「入力画像が9でない」と示したいときには、0.5より大きな出力は"9"とみなし、0.5以下の出力は"9でない"とみなす方法などである。
次に、ニューラルネットワークと深層学習をより深く理解するために、ニューラルネットワークのそれぞれの部分の名前を説明する。
ニューラルネットワークのモデルを図4に示す。
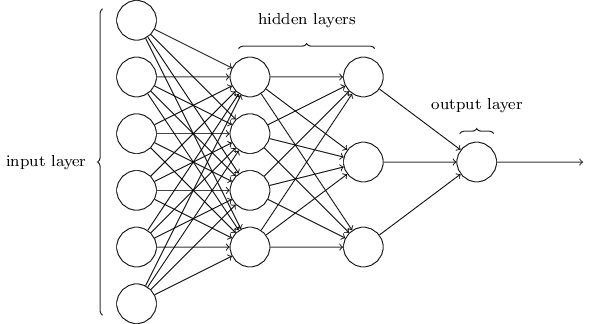
図4 ニューラルネットワーク名部分の名前
一番左の層は入力層(input layer)と呼ばれ、その中のニューロンを入力ニューロン(input neurons)と言う。一番右の層または出力層(output layer)は、出力ニューロン(output neurons)から構成されている。中央の層は入力でも出力でもないことから、隠れ層(hidden layer)と呼ばれる。この"隠れ"という用語は、何か数学的な、または哲学的な意味があるのだと誤解されがちだが、ただ単に"入出力以外"ということを意味しているにすぎないので注意が必要である。図4のニューラルネットワークは2つの隠れ層を持っているが、1つの隠れ層しか持たないニューラルネットワークや、より多くの隠れ層を持ったニューラルネットワークも存在する。
4-2. 学習方法
次に、ニューラルネットワークがどのように学習するのかを説明する。学習には「教師あり」学習と「教師なし」学習の2種類があるが、ここでは教師あり学習について説明する。
教師あり学習において、最初に必要になるものは学習するためのトレーニングデータセットである。例えば、手書き数字認識のデータセットとしてよく使われるのが、MNISTデータセットである。MNISTデータセットは数万件の手書き数字スキャン画像と、その正しい分類がなされているデータセットである。
最終的に私たちが得たいものは、全入力xについて、ネットワークの出力がMNISTのy(x)になるべく近くなるような重みとバイアスを見つけるアルゴリズムである。この目標をどれだけ達成できたか測るために、コスト関数を定義する。コスト関数とは、損失関数、または目的関数とも呼ばれる。それからコスト関数の最小値を求める。結果、例えば最小二乗法では、それが0に近くなれば、目標を達成できたといえる。
深層学習でよく使われるコスト関数を用いる手法には以下のものがある。
・最小二乗法
C(w,b)≡(1/2n)∑ x ∥y(x)−a∥^2
・クロスエントロピー
コスト関数の最小値を求めるための手法には以下のものがある。
・勾配急下法
勾配急下法とは、関数の傾きのみから、関数の最小値を探索する最適化問題の勾配法のアルゴリズムのひとつである。
図4のようなニューラルネットワークを設計できるのがTensorFlowである。
TensorFlowの使用できる環境と言語は以下の通りである。
対応OS:Linux, Mac OS X
開発言語:C++, Python
TensorFlowの主な特徴や利点を以下に示す。
・スケーラビリティ
PC、サーバ、モバイル端末まで、各マシンのリソースに応じてスケールする。つまり、低スペックなマシンでも動作し、GPUが使用できるハイスペックなサーバであればそのリソースを活用した計算が可能である。
・簡易/柔軟な記述方式
TensorFlow以外のどのライブラリでもよく特徴としてあげられるものであるが、具体的に示すと、チュートリアルとしてちょうど良い難易度である90%前後の認識率の手書き数字認識プログラムを20行程度のコードで記述することが可能である。また、熟練者向けの99.2%前後の認識率の手書き数字認識プログラムは70行程度のコードで記述することが可能である。
・多数のプログラミング言語からの利用
現在(2016/06/24)はC++/Pythonのみであるが、将来的には多言語からも利用可能なインタフェースが提供される予定である。
・可視化機能
TensorBoardという構築した計算フローの可視化機能が付属している
・過去の実績
Googleの各種サービスで使用された実績がある
4-3. ニューラルネットワークは任意の関数を表現できる
ニューラルネットワークに関して最も衝撃的な事実の1つは任意の関数を表現できることだ。図5のグラフについて考える。
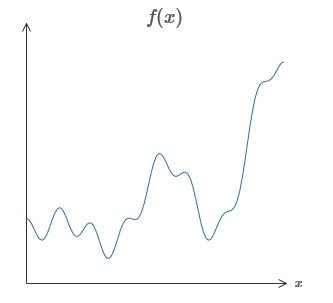
図5 任意の関数の例
//補足
ニューロンにより、補足図1のようなステップ関数の近似を作ることができる。
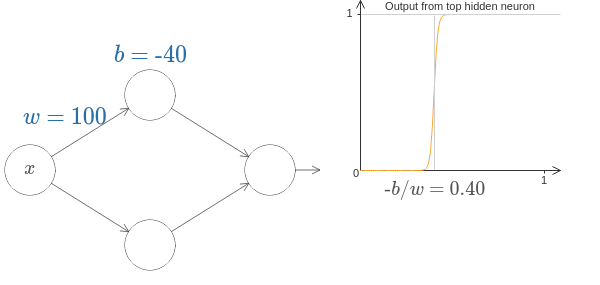
補足図2のように簡略化する。
s=-b/w
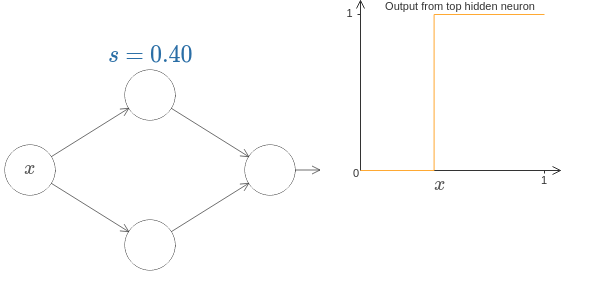
以下のようにニューロンを2つ並べると、コブを作ることができる。
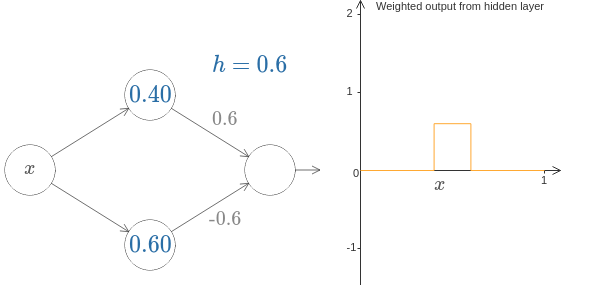
さらにそのニューロンのペアを並べることによってコブを増やすことができる。
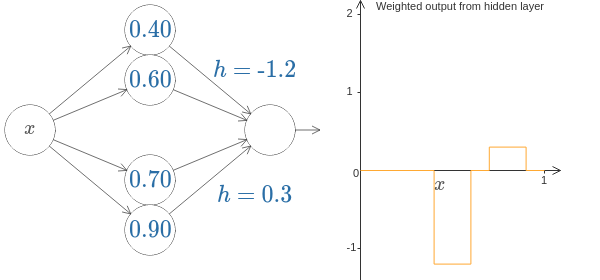
図6では、オレンジの色のグラフがニューラルネットワークのグラフであり、各hの値によって、こぶが並んだようなグラフになることがわかる。
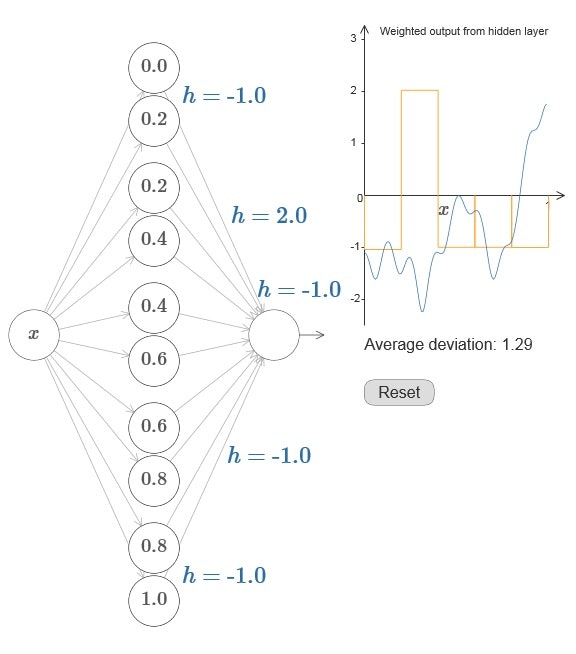
図6 ニューラルネットワークのグラフ
図7では、粗い近似として、図6のhの値を変えてみた。このことから、隠れニューロンのペアの数を増やすことで簡単に近似精度を良くできるとわかる。
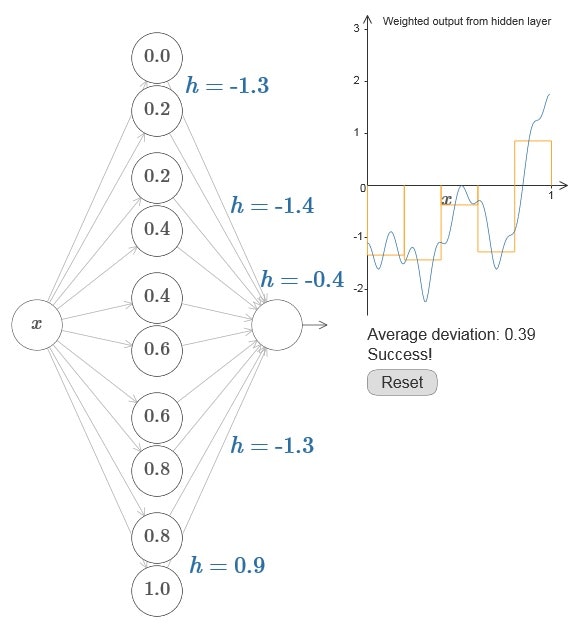
図7 ニューラルネットワークによる粗い近似
3次元以上の関数についても、層を厚くし、ニューロンの数を増やすことによって、任意の関数を表現できる。(4次元以上の関数のモデル作成においては、そのグラフをどう視覚化するかについての数学者の議論が参考になるだろう。)
ただし、この結果はニューラルネットワークを構成するのに直接有用ではない。機械的にニューロンの数を増やすより、より良いモデルがあるからだ。しかし、これは任意の関数をニューラルネットワークで計算可能かという問いを議論から外すことができる、という点では重要だ。その問いへの答えは常に「可能である」だからだ。従ってモデルを構築する際の正しい問題設定は、ある特定の関数を計算可能かではなく、その関数を計算する良い方法は何か、である。
5.実証実験/文献探索
実験環境は以下の通りである。
OS:Windows7 64bit
プロセッサ:Intel Core i7-5500U(2.40GHz)
メモリ:8.00GB
VirtualBOX, Dockerを利用してLinuxの仮想環境上でPythonのコードを処理する。
追記:Dockerの仮想環境の設定はコア1個、メモリ1GBでした。
追記:python(2.7.12)、tensorflow(0.11.0)
5-1. 1次関数(線形の関数)の近似
y = 0.1*x + 0.3 の近似をする。データセットを100個用意し、機械学習を行う処理を1001回繰り返すことによって2つのパラメータを求めることができる。
入力はx1個、出力はy1個、隠れ層として人工ニューロン1個の非常に簡単なニューラルネットワークのモデルを作成した。
結果は
W=0.09999991
b=0.30000007
処理時間は
0.253083944321[sec]
であった。
図8,9に実行結果を示す。まず、ステップ100ごとにWとbを出力し、学習の経過を見ることができる。その後、学習したニューラルネットワークにxを0から99まで入力し、出力した。
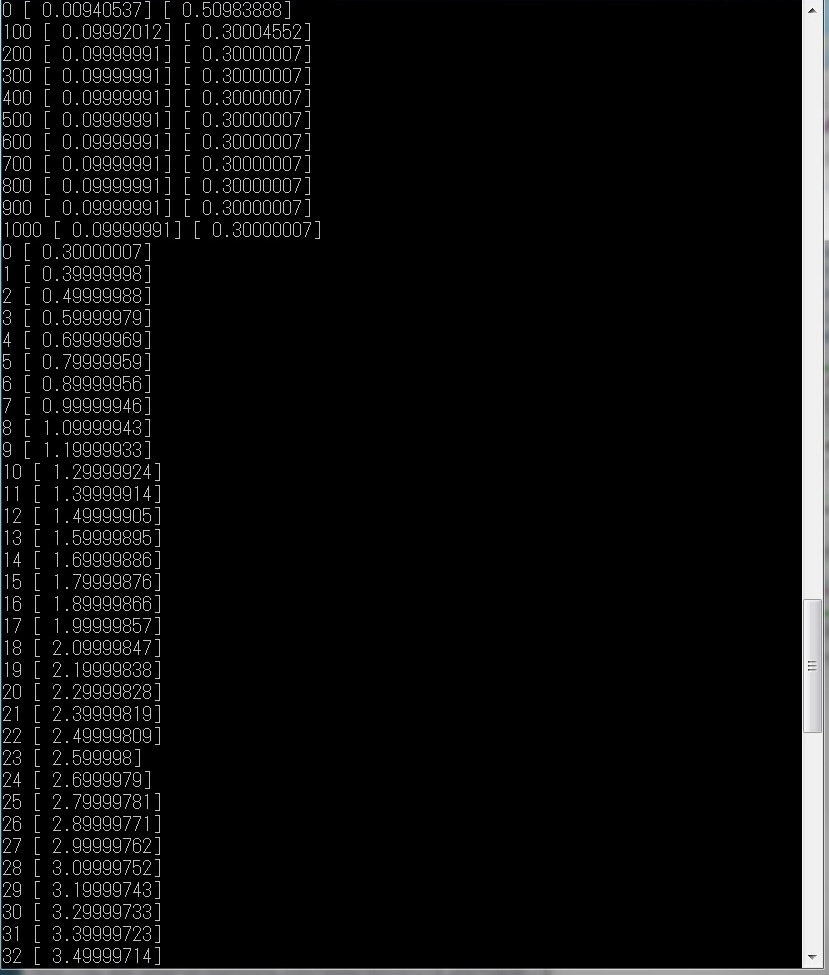
図8 1次関数の近似プログラムの結果①
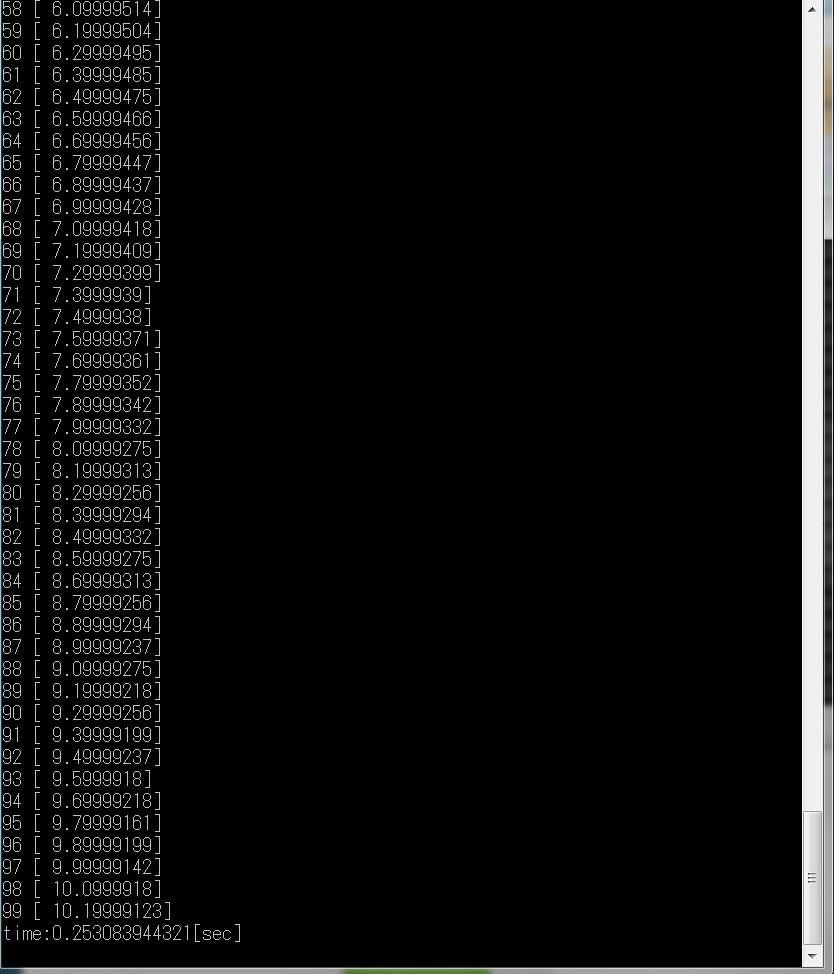
図9 1次関数の近似のプログラムの出力結果②
コードを以下に示す。
import tensorflow as tf
import numpy as np
import time
start = time.time()
x_data = np.random.rand(100).astype("float32")
y_data = 0.1 * x_data + 0.3
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
loss = tf.reduce_mean(tf.square(y_data - y))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in xrange(1001):
sess.run(train)
if step % 100 == 0:
print step, sess.run(W), sess.run(b)
for i in xrange(100):
print i, sess.run(W) * i + sess.run(b)
sess.close()
timer = time.time() - start
print ("time:{0}".format(timer)) + "[sec]"
5-2. n次関数の近似
y = 0.3x^2 + 0.2x + 0.1
のグラフのデータセットを用意し、機械学習により近似を行う。
図10、11、12に実行結果を示す。
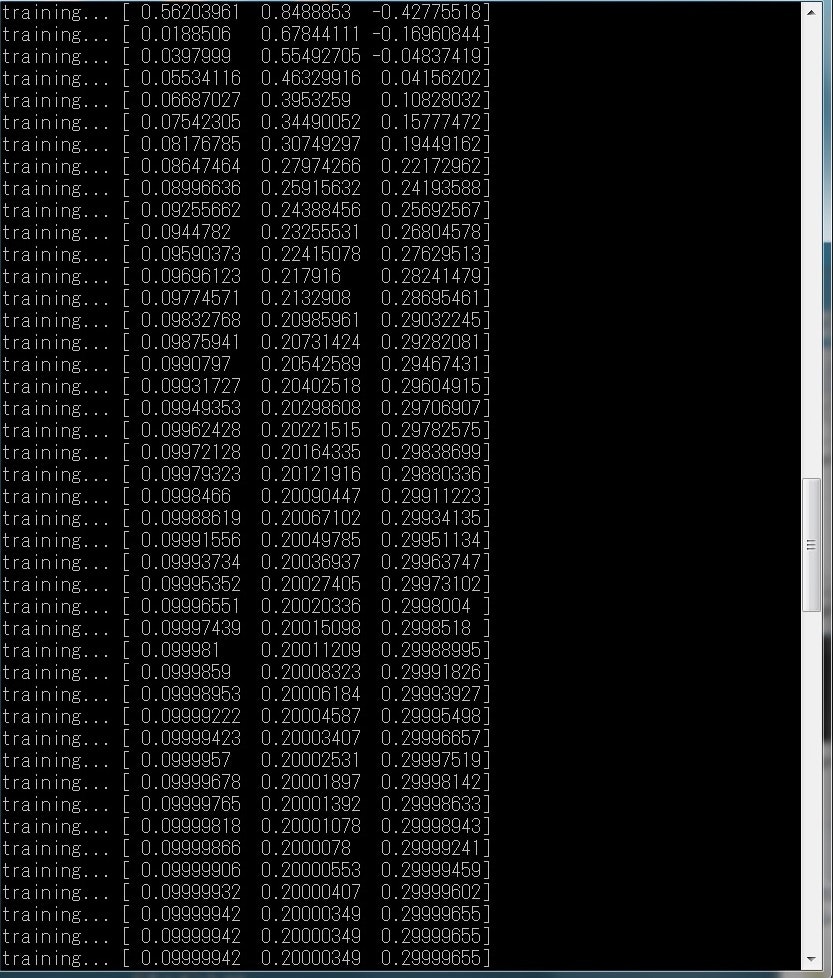
図10 n次関数の近似プログラムの出力結果①
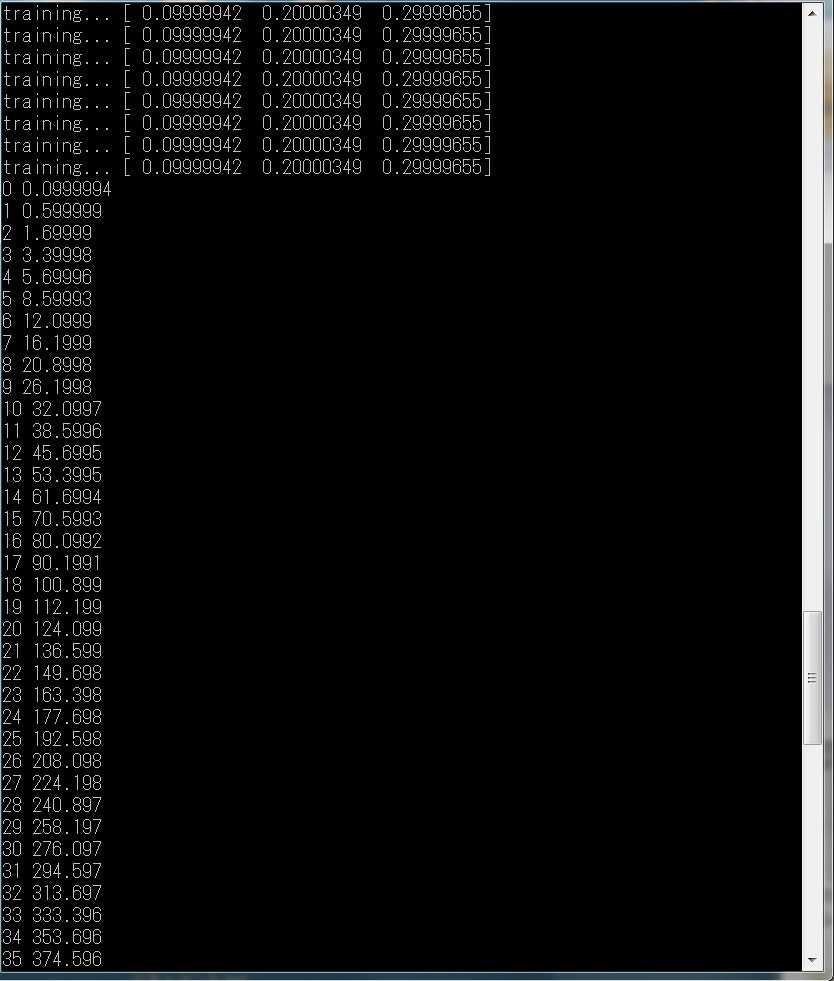
図11 n次関数の近似プログラムの出力結果②
図12 n次関数の近似プログラムの出力結果③
以下にコードを示す。
import tensorflow as tf
import numpy as np
import random
import math
import time
start = time.time()
AC=100
# number of W
WN=3
# 1+number of the function s dimention
NN=3
a = np.arange(0.1,(WN+1)*0.1,0.1)
def y_from_x(_x,_W,_b):
_y = np.dot(_W,_x) + _b
return _y
x_data = np.random.rand(AC,NN,1).astype("float32")
y_data = np.zeros((AC,NN,1)).astype("float32")
npow = 1
for i in xrange(NN):
y_data += a[i] * npow
npow *= x_data
W = tf.Variable(tf.random_uniform([WN], -1.0, 1.0))
y = 0
npow = 1
for i in xrange(WN):
y += W[i] * npow
npow *= x_data
loss = tf.reduce_mean(tf.square(y_data - y))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in xrange(5001):
sess.run(train)
if step % 100 == 0:
print "training...", sess.run(W)
for i in xrange(100):
result = 0
npow = 1
for j in xrange(WN):
result += W[j] * npow
npow *= i
print i, sess.run(result)
sess.close()
timer = time.time() - start
print ("time:{0}".format(timer)) + "[sec]"
5-3. 手書き数字の画像認識
結果は
認識率:0.911
処理時間:4.97089481354[sec]
となった。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf
import time
start = time.time()
x = tf.placeholder(tf.float32,[None,784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,W)+b)
y_ = tf.placeholder(tf.float32,[None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
print tf.argmax(y, 1)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
timer = time.time() - start
print ("time:{0}".format(timer)) + "[sec]"
5-4.他の機械学習ライブラリとの比較
他の機械学習ライブラリと比較するとなると、そのための開発環境を整えなければならない。よって比較実験は今後の課題とし、今回は文献やインターネットの調査から考察する。以下の表に主な機械学習ライブラリを示す。
表1 機械学習ライブラリ一覧
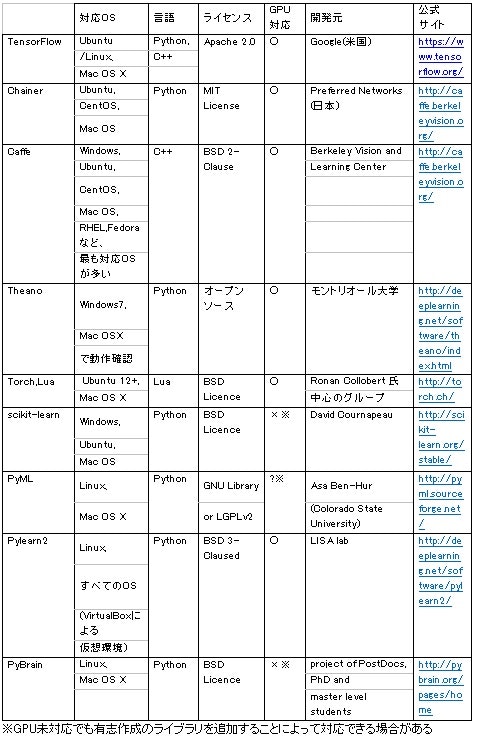
※公式サイトリンク一覧
TensorFlow:https://www.tensorflow.org/
Chainer:http://chainer.org/
Caffe:http://caffe.berkeleyvision.org/
Theano:http://deeplearning.net/software/theano/index.html
Torch:http://torch.ch/
scikit-learn:http://scikit-learn.org/stable/
PyML:http://pyml.sourceforge.net/
Pylearn2:http://deeplearning.net/software/pylearn2/
PyBrain:http://pybrain.org/pages/home
・TensorFlow
1.結論、2.背景、7.まとめ、において言及しているのでここでは省略する。
・Chainer
参考文献:
http://qiita.com/icoxfog417/items/96ecaff323434c8d677b
http://nonbiri-tereka.hatenablog.com/entry/2015/06/14/225706
Chainerは、Preferred Networksが開発したニューラルネットワークを実装するためのライブラリである。記法が直感的かつシンプルなので、単純なネットワークから、複雑なディープラーニングまで幅広くカバーできる。
日本発のライブラリである。
また、短く書ける。Caffe上のコード2058行がChainerでは167行で書ける。
そして、設定ファイルや固定データセットが必要ない。Caffeでは、設定ファイルと構築したデータセットを主に使うことになっていたので、動的にDataArgumentationしようとすると面倒になる。
最後に、インストールが簡単である。
・Caffe
参考文献:
http://caffe.berkeleyvision.org/
CaffeはPython向けの代表的なディープラーニングライブラリである。C++で実装され、GPUに対応しているため、高速な計算処理が可能である。
Caffe is a community というキャッチコピーもあるほど、その開発コミュニティーが活発にgithubを更新していたり、サンプルコードも多く初心者に推奨される。
大規模画像認識のコンテストILSVRCで2012年に1位となった畳み込みニューラルネットワークの画像尾分類モデルがすぐに利用できるようになっている。
Caffeは、カリフォルニア大学バークレー校のコンピュータビジョンおよび機械学習に関する研究センターであるBVLCが中心となって開発している。ヤフージャパンは2014年6月から同センターのスポンサーになっていて、Caffeの開発を含めたセンターの研究の支援を行っている。
・Theano
参考文献:
http://aidiary.hatenablog.com/entry/20150127/1422364425
http://www.chino-js.com/ja/tech/theano-rbm/#id5
TheanoはPython向けの「ディープラーニング(Deep Learning)」ライブラリである。
機能としては、ディープラーニングの他に「行列演算」「実行時にCコードを生成してコンパイル」「自動微分」「GPU処理(要CUDA)」もあり、ケースによっては数値計算ライブラリ「Numpy」よりも高速に計算できる。
Deep learning に関するTutorialの量がとても多い。Theano自体は自動偏微分機能・GPU対応などをサポートする計算ライブラリで、Deep learning専用のパッケージではない。自分で理論から理解してScratchで実装したい人にはとても参考になる。
Theanoをベースに開発されたライブラリが多いようだ。
・Torch,Lua
参考文献:
http://conditional.github.io/blog/2013/12/07/an-introduction-to-torch7/
畳み込みニューラルネットワークを用いた、低画質画像から高画質画像を生成するソフトであるwaifu2xなどはこれを利用して開発されている。
・scikit-learn
機能としては、分類 (Classification)や回帰 (Regression) 、クラスタリング (Clustering) 、次元削減(Dimensionality reduction)などが実装されている。
・PyML
SVM、再近傍法、リッジ回帰等に適している。
・Pylearn2
機械学習向けライブラリのPylearn2は、画像の認識処理等に適している。
・PyBrain
ニューラルネットワーク系に強いライブラリである。
6.考察
6-1. 1次関数(線形の関数)の近似
チュートリアルとして非常に簡単なニューラルネットワークモデルを構築した。使用した数式は行列を使わないスカラーの掛け算のみである。
図8をみると、step200の時点で、コスト関数が収束し、学習が完了していることがわかる。学習時間は1/5になると推測していいだろう。
以下に、一次関数をこのモデルで近似することの利点と欠点を示す。
利点
・解析学の知識なしに近似を行える。数学の深い知識なしに近似を行える、と言い換えても差し支えない
・単純なモデルであるため、ニューラルネットワークのチュートリアルとしてわかりやすい
・単純なモデルであるため、高速である
・トレーニングデータセットに誤差があっても近似できる。ただし、結果にもごく小さい誤差が出る
欠点
・普遍性、一般性がない
・行列を扱わないため、TensorFlowの強みであるmatmul関数を使わず、それについて学べない
6-2. n次関数の近似
次に、より一般性を高くした、n次関数の近似のニューラルネットワークモデルを構築した。行列の計算をするので、難易度があがる。
利点
・理論上、すべてのn次関数の近似を行える(ただし、次数をあげると大幅に処理時間が増えるので、現実的ではない)
・行列、テンソルを理解するのにちょうど良い難易度である
欠点
・4次以上で処理時間が大幅に上がる。4次では、収束するまで数時間かかると推測される
・正規化しないので、クロスエントロピーについて学べない。クロスエントロピーを使うものも、今後書きたい
・matmul関数は便利だが、ブラックボックスであり、詳しい処理が不明である。matmul関数は行列の内積やスカラー量の掛け算を行える。行列の内積と、スカラーの掛け算は基本、別物であるが、matmul関数はその違いを意識せずに、単に「行列の掛け算」として使うことができる関数である
6-3. 手書き数字の画像認識
TensorFlowで画像認識を行う。画像認識の分野でよく使われるMNISTという手書き数字のデータセットを使用する。この結果で、ニューラルネットワークでは人間が複雑なアルゴリズムを考えることなく、画像認識できることがわかる。
入力は784個(ピクセルの数)、出力は10個(0から9までの数字に対応するそれぞれの確率)である。例えば数字が9であれば、10個目の出力に、(9である確率が)0.92などと、出力される。この場合、2個目の出力には、(1である確率が)0.0012など、ごく少ない確率が出力されるだろう。
最終的に、学習を完了した後、新しいデータセットをテストデータとして入力しその正解率を計算して出力する。
利点
・20行程度の少ないコードで画像認識を行える
・関数の近似より、難易度が上がり、多くのことを学べる
欠点
・難易度が上がったので、コードの修正が難しい。サンプルのコードをそのまま書いて、満足しがちである
・認識率90%はこの分野では低い。上級者向けの層を増やしたモデルならば、99%の認識率になる
・行列の定義について、正しく理解するのが難しい。行列のライブラリnumpyと、TensorFlowでは、行列の定義の仕方が異なるのか、定義が曖昧だ。生成した行列が横ベクトルになるのか縦ベクトルになるのかわかりづらい。また、3次元の行列(テンソル)以上になると、可視化できないので、扱いがとても難しい。行列の深い知識が必要である。
7.まとめ
ニューラルネットワークの設計について、押さえておくべき点をまとめる。
7-1.利点と欠点
利点
①あらゆる関数を近似できる(あらゆる問題を解ける)
欠点
①大量の処理が必要である
少なくともGPUが2台以上欲しいと感じた(なんとなくなので根拠はない)。CPUのみだと明らかに速度が足りない。
②開発には特別な知識が必要である
多次元行列(テンソル)の表現と計算についての深い知識が必要である。画像処理、音響処理などになると、その分野の専門知識が必要である。
③機械学習分野の専門学者の経験則によって採用されるアルゴリズムが多い
長年の研究の結果によって採用されたアルゴリズム(コスト関数など)が多い。これからもそのような新しいアルゴリズムが開発されると予想される。解決したい問題ごとに適したモデルがあるが、「何故かはわからないけど、うまくいった」モデルがあるようなので、複雑なモデル設計は手探りでしなければならないという側面がある。
7-2.万能なひとつのモデルはない
あるひとつの万能なモデルを作成して、関数近似や画像認識、音声認識をさせることは現状できない。解決したい問題ごとに適切なニューラルネットワークモデルを設計するのが良い。
7-3.行列、テンソルの知識は必須である
特に非線形の問題に対しては、複雑なテンソルを使ったニューラルネットワークのモデルを構築することになり、それを可視化する方法や、記述方法は必ず習得すべき技術である。
TensorFlowについて、押さえておくべき点をまとめる。
7-4.TensorFlowの利点と欠点
利点
①モデル設計が簡単でコード記述も簡潔に書ける
②商用フリーのライセンスであるため、機械学習システム導入のコストを抑えられる
③学習し易い
④導入しやすい
欠点
①ほとんどの処理がブラックボックスである
関数の処理フローが明確でない。エラーを動作原理まで遡って特定することができない。
②Windowsに対応していない
追記:バージョン0.12からWindowsに対応しました。
以下はGoogle Developers Blog の記事 "TensorFlow 0.12 adds support for Windows"の翻訳です。
今回の TensorFlow r0.12 のリリースに合わせて、Windows 7、10、Server 2016 向けのネイティブ TensorFlow パッケージを提供します。このリリースでは、CUDA 8 対応の GPU で TensorFlow トレーニングを高速化できます。
7-5.開発環境について
今回はWindowsにDockerにより、Linuxの仮想環境を構築し、TensorFlowを動作させた。しかし、DockerはGUIをサポートしていないため、グラフや画像を表示できなかった。Windowsに対応するまで、TensorFlowはMacOSまたはLinuxで開発したほうが良い。
[参考文献]
ニューラルネットワークと深層学習:Michael Nielsen:2014.12
http://nnadl-ja.github.io/nnadl_site_ja/index.html
TensorFlowを算数で理解する
http://qiita.com/icoxfog417/items/fb5c24e35a849f8e2c5d