はじめに
株式会社NTTデータ数理システムのitok_msiです。
みなさんご存知のように、GANを用いた画像変換が結果のセンセーショナルさもあいまって、注目を浴びています。
写真を絵画調にする、馬をシマウマに変換する、航空写真から地図を作成する、など様々な応用例が開発されています。
そこで、今回はその中でも比較的新しい手法であるcycleGAN [1]を使って「画像内の犬をポーズと毛並が似た猫に変換するモデル」を作成してみようと思います。
実は、犬を猫に変換するというタスクは、上に上げたような「馬をシマウマに変換する」「航空写真から地図を作成する」といったタスクとは微妙に異なるのですが、それに関しても後程説明します。
cycleGAN
cycleGANは、2つのデータソース間の変換を学習するGANの一種です。
pix2pix[2]とは異なり、2つのデータソースのインスタンスが1対1に対応していなくても学習が行えるのが特徴です。
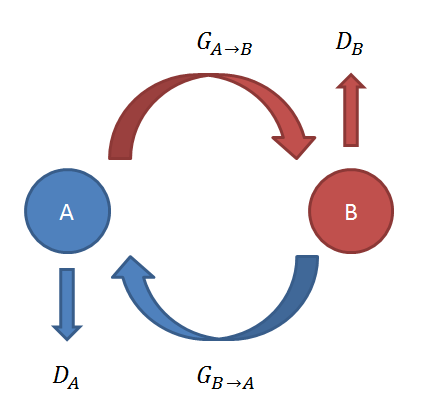
cycleGANでは2つの学習データソースA,Bを利用して
- ソースAのデータをソースBへ変換するGenerator $G_{A\to B}$
- ソースBのデータをソースAへ変換するGenerator $G_{B\to A}$
- 入力を、$G_{A\to B}$によって生成された偽物のBかオリジナルのBのデータか判別するDiscriminator $D_B$
- 入力を、$G_{B\to A}$によって生成された偽物のBかオリジナルのAのデータか判別するDiscriminator $D_A$
を学習します。このとき、
- Generator $G_{B\to A}, G_{A\to B}$は、Discriminator $D_A, D_B$をだませるほど本物に近いデータを生成しようとします。
- $D_A, D_B$は、$G_{B\to A}, G_{A\to B}$ が作成した偽物のデータと本物のデータを区別できるよう学習します。
- $G_{A\to B}$による変換結果を$G_{B\to A}$で変換すると、もとのデータに戻ることを要請します。
- $G_{B\to A}$による変換結果を$G_{A\to B}$で変換すると、もとのデータに戻ることを要請します。
具体的には、目的関数として次のような3つの誤差の和を用います。
$L(G_{A\to B}, G_{B\to A}, D_A, D_B) = L_{GAN}(G_{A\to B}, D_B, A, B) + L_{GAN}(G_{B\to A}, D_A, B, A) + \lambda
L_{cyc}(G_{A\to B}, G_{B\to A})$
- $L_{GAN}(G_{A\to B}, D_B, A, B)$
- $D_B$で本物のBと$G_{A\to B}$によって作られたBをどれだけ区別できているか
- $L_{GAN}(G_{B\to A}, D_A, B, A)$
- $D_A$で本物のAと$G_{B\to A}$によって作られたBをどれだけ区別できているか
- $L_{cyc}(G_{A\to B}, G_{B\to A})$
- $G_{A\to B}(G_{B\to A}(b))$ と$b$との距離 + $G_{B\to A}(G_{A\to B}(a))$ と$a$との距離
- 各ピクセル値の差を利用して計算
$G_{A\to B}, G_{B\to A}$はこの目的関数を小さくするように、$D_A, D_B$ は目的関数を大きくするように学習します。
$L_{cyc}(G_{A\to B}, G_{B\to A})$はcycle consistency lossと呼ばれるもので、いわゆる再構築誤差です。
cycle consistency lossを小さくするためには、$G_{A\to B}, G_{B\to A}$でデータを変換した結果がそれぞれ元のデータを再構築できるだけの情報を保持している必要があります。したがって、学習がうまくいった場合は$G_{A\to B}, G_{B\to A}$として「A,Bに共通する構造を保ったまま、あるソースのデータをもう一方のソースのデータに変換する」関数が得られることになります。
例えば、馬とシマウマのデータセットを与えると、画像内の馬のポーズを保ったままシマウマに変換する関数を学習できます。
次の画像がcycleGAN論文[1]で紹介されている$G_{A\to B}, G_{B\to A}$の例です。

それでは、猫と犬の画像を与えれば、ポーズや毛並を保ったまま犬を猫に変換するモデルが作成できるのでしょうか?
犬を猫に変換する難しさとcycleGANの問題点
残念がら犬を猫に変換するのは一筋縄ではいきません。cycleGANの論文でも次の図のように失敗例として犬猫変換が紹介されています。

猫と犬は毛並や質感こそ似ているものの、特に顔の形が異なります。このように形の変形を伴う変換は今後の課題として論文でも指摘されていました。
また、特に$G_{dog\to cat}$は恒等写像を学習してしまっているように見えます。
そこで、cycleGANで犬猫変換を作成しようとしたとき恒等写像を学習してしまう原因を考えてみました。
1. cycle consistency lossの効果が強すぎる
犬猫変換のように形状の変化を伴う変換は、入力画像の情報をある程度犠牲にせざるを得ません。これはcycle consistency lossを大きくしてしまいます。一方、$G_{A\to B}, G_{B\to A}$がともに恒等変換ならばcycle consistency lossは最小になります。つまり、cycle consistency lossを小さくするという観点では恒等変換の方が有利です。
もちろん恒等変換では犬を猫に変換できないため、cycleGANが想定する状況では$L_{GAN}$が大きくなってしまうはずです。言い換えると、恒等変換である$G_{dog\to cat}$で犬画像を変換した結果とオリジナルの猫画像は$D_{cat}$で明確に区別できることを想定しています。
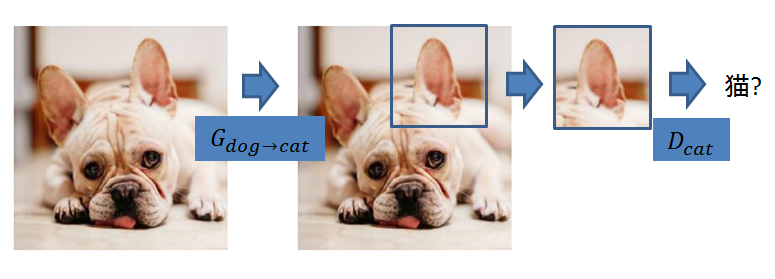
しかし、ここで問題になってくるのが犬と猫は局所的にとてもよく似ているということです。
2. 局所的には犬と猫はとても似ている
cycleGANではDiscriminator$(D_A, D_B)$の学習にpatchGAN[1][2]の機構を採用しています。これは入力画像がGeneratorによって作られたものかオリジナルのソースのものか判別するときに、画像全体を使わず、画像内の局所的なpatch(小領域)を元に判別するというものです。$L_{GAN}$の計算の際は画像上でpatchを滑らせていき、各patch上の判別の誤差の平均をとります。
Discriminatorのネットワークを小さくできるという利点はありますが、猫と犬は局所的にとてもよく似ているので、学習は難しそうです。
つまり、$G_{dog\to cat}$が恒等変換であっても$D_{cat}$をうまくだましてしまう可能性があります。
cycleGANの修正
今回は上に上げたような問題点を回避するために、cycleGANに簡単な2つの修正を施しました。
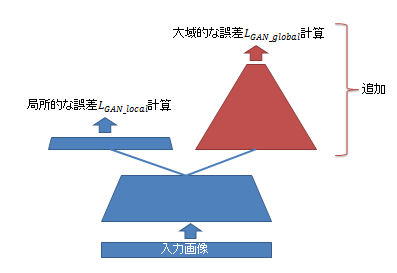
1. Discriminatorでglobalな情報も見るようにする
詳細は省略しますが、patchGANのDiscriminatorに層を追加し、globalな情報と局所的な情報の両方について$L_{GAN}$を計算するようにしました。
2. 誤差関数におけるcycle consistency lossの割合を小さくする
誤差関数におけるcycle consistency lossの係数をオリジナルの1/10程度に減らしました。
実験
cycleGANの論文の著者らにより公開されているpytorchによるcycleGANの実装に上記の修正を加えて実験を行いました。
実行環境はawsのp2.2xlargeインスタンスです。
使用データ
The Oxford-IIIT Pet Datasetから犬画像1922枚、猫画像3922枚を学習データとして、残りを検証用データとして使用しました。
実験結果
比較的うまくいった例(猫→犬)

なんかバカっぽい猫はなんかバカっぽい犬に変換されました。

比較的うまくいった例(犬→猫)

失敗例(猫→犬)

失敗例(犬→猫)

考察
安直な修正では、期待したような結果は得られませんでした。
特に、
- 動物の色の情報を保てていない
- 背景と動物が区別できていない
- ぼやけた画像になってしまっている
- 変換先の猫や犬がほぼ同一種にみえる
例が多い印象です。
原因としては
- 再構築誤差の割合を小さくしすぎた
- Discriminatorのネットワークが大きすぎてうまく学習できていない
などが考えられます。
今回は「画像内の犬をポーズと毛並が似た猫に変換するモデル」を作成を試みましたが、そもそも「ポーズ」や「毛並」は高次元な特徴量であり、再構築誤差として画像のピクセルごとの差を計算するcycleGANでは分が悪い気がします。
再構築誤差としてより高次元の特徴量を比較したら、、、という考えに基づくGANの手法もあるので、機会があればそちらも記事にしたいと思います。
追加実験結果 (2017/06/14追記)
上記の実験では再構築誤差の割合を小さくしすぎたため、形が大きく崩れてしまっていたようなので、再構築誤差を割合を元に戻し実験をし直しました。
比較的うまくいった例(猫→犬)

比較的うまくいった例(犬→猫)

失敗例(猫→犬)

失敗例(犬→猫)

犬や猫が正面を向いている場合は比較的うまくいく印象です。
正面から見ると、猫も犬も目鼻口の配置が似通っているためと思われます。
しかし最後の例のように、横を向いている場合や、猫にはない大きな耳を持った犬の変換は、大胆な形の変更が必要なため、依然難しいようです。
参考文献
[1]Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros, Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, arXiv preprint arxiv:1703.10593, 2017.
[2]Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, Image-to-Image Translation with Conditional Adversarial Networks, Image-to-Image Translation with Conditional Adversarial Networks, arXiv preprint arxiv:1611.07004 , 2016.