はじめに
今年はTreasureDataも分析基盤としての利用用途が大きく変わった年だった気がする。
同時に基盤の集計やデータ連携も複雑になり、速度を含めたリアルタイム性なども求められる
ことが多くなってきています。
そんな中、DataConnector(Embulk)のようなデータ連携をシームレスにするモジュールが
リリースされ、サーバーレス、コーディングレスで容易にデータを移すことができるようになりました。
またHadoopが得意ではない更新処理やBIツール連携をスムーズにするためにDatatanksを
用意したりとスピードを担保するような機能もリリースされています。
たまたま今週EmbulkのMeetupに参加し、データ基盤を構築している方々のお話や友人と
話をしていて、意外とEmbulkを試しているなぁと思ったのと各社利用するために工夫している部分
が多いなというのを感じました。
主には
- configファイルの管理(ファイル数の多さや動的パラメータの管理)
- 全体のハンドリングを含めたワークフロー
などデータを移動させるために必要なものを各自工夫している感じがしました。
データ連携をしてセグメントでも可視化してみるかぁと思ったのですが、意外と準備に
1日かかったので簡単にデータを集計して可視化するところまでで今回は時間切れでした。
セグメントを可視化するために...
今回やったこと
1, TreasureData上JSSDKで収集し、集まったデータでユーザセグメントをクエリで集計する。
2, 1のデータをDataTanksに転送(ResultOutput機能)
3, Eubulkを使ってElasticSearchに転送(InputがPostgreSQL,OutputがElasticSearch)
4, それをKibanaで可視化
(セグメント作成のクエリテンプレートは別で作成して載せておきます。)
来年できるようになるといいな!(期待を込めて勝手に書きます)
1, TreasureData上でセグメントをボタンで集計する(とあるセグメントの集計ボタンが付いているイメージ)
2, すぐ可視化
(1), DataConnectorsでElasticsearchに書き込み,すぐ可視化。(eubulk-output-elasticsearchが取り込まれるのか)
(2), もしくはトレジャーデータ内で可視化
準備
Embulkインストール
$ curl --create-dirs -o ~/bin/embulk -L http://dl.embulk.org/embulk-latest.jar
$ chmod +x ~/bin/embulk
$ cat << 'EOF' >> ~/.bash_profile
export PATH=$PATH:$HOME/bin
EOF
$ source ~/.bash_profile
Embulkで利用するプラグインのインストール
$ embulk gem install embulk-input-postgresql
$ embulk gem install embulk-output-elasticsearch
Embulkで利用するYMLの作成
in:
type: postgresql
host: 00.00.00.00
user: tank_user
password: "XXXXXXXXXXXXXXXX"
database: datatank
query: |
SELECT os,device,flag,count
FROM device_master
out:
type: elasticsearch_2x
nodes:
- {host: localhost, port: 9300}
index: device
index_type: test
bulk_actions: 200000
ElasticSearchのインストール
https://www.elastic.co/downloads/elasticsearch
こちらのサイトより最新版をダウンロード。
最終的には2.1.1。
kibanaのインストール
https://www.elastic.co/downloads/kibana
上記のサイトで最新版をダウンロード
あとはtarを展開して適当に配置
ただしembulk-output-elasticsearchのバージョン問題に
気づくまでkibana+elasticsearchは何度もバージョンを入れ替えて
ガチャガチャしました。
結果はEmbulk-pluginの方で別branchでマルチバージョンの対応が
されており、こちらをフェッチしてリコンパイルが必要みたいです。
https://github.com/muga/embulk-output-elasticsearch/tree/support-multiple-versions_3gems
branchを切り替えてビルドし、
$ git co support-multiple-versions_3gems
$ ./gradlew gem
$ embulk gem install embulk-output-elasticsearch_2x-0.1.8.gem
$ embulk gem list
実行
1,DatatankにResultoutput
書き込み設定
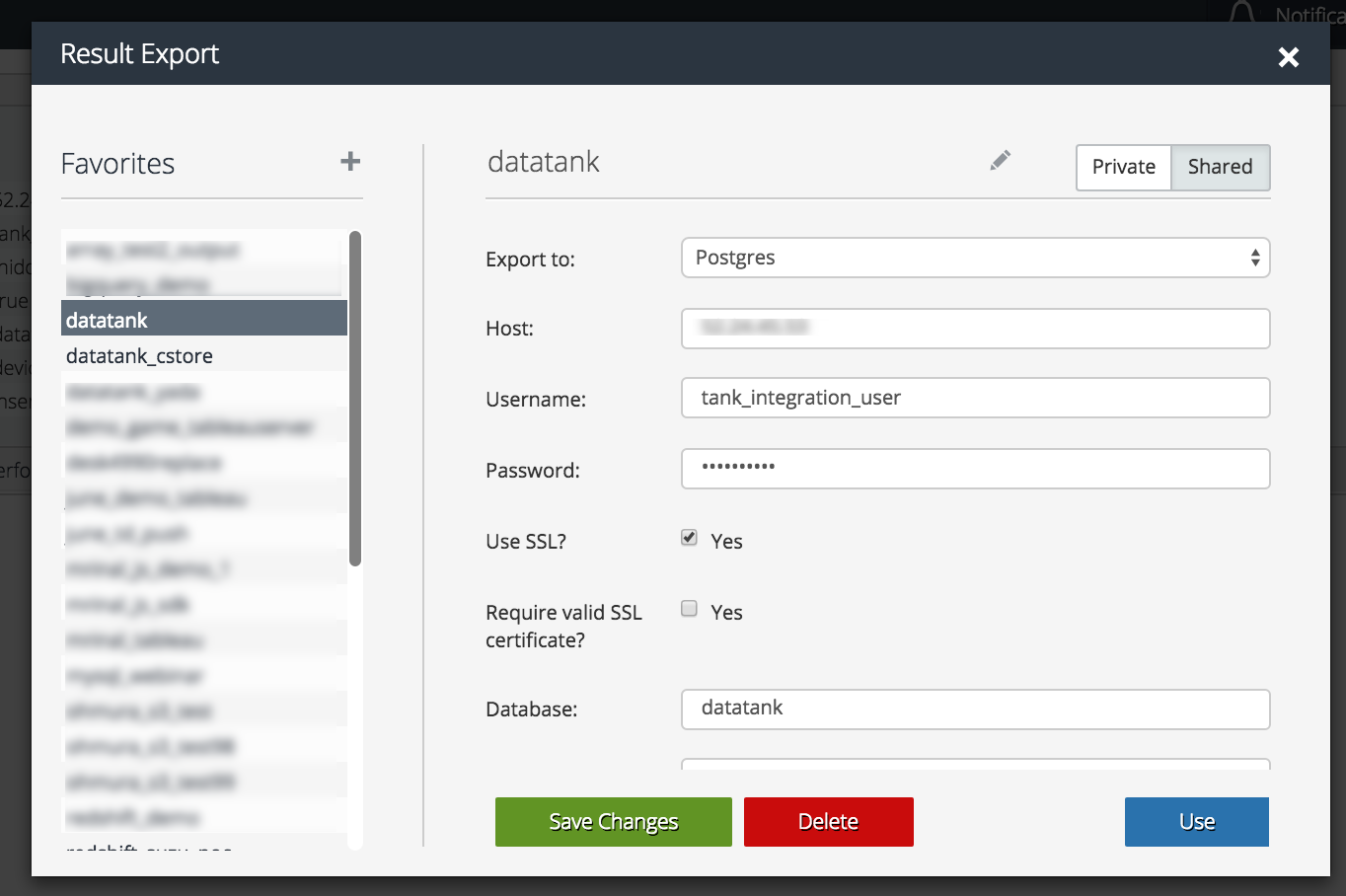
DBに書き込み実行
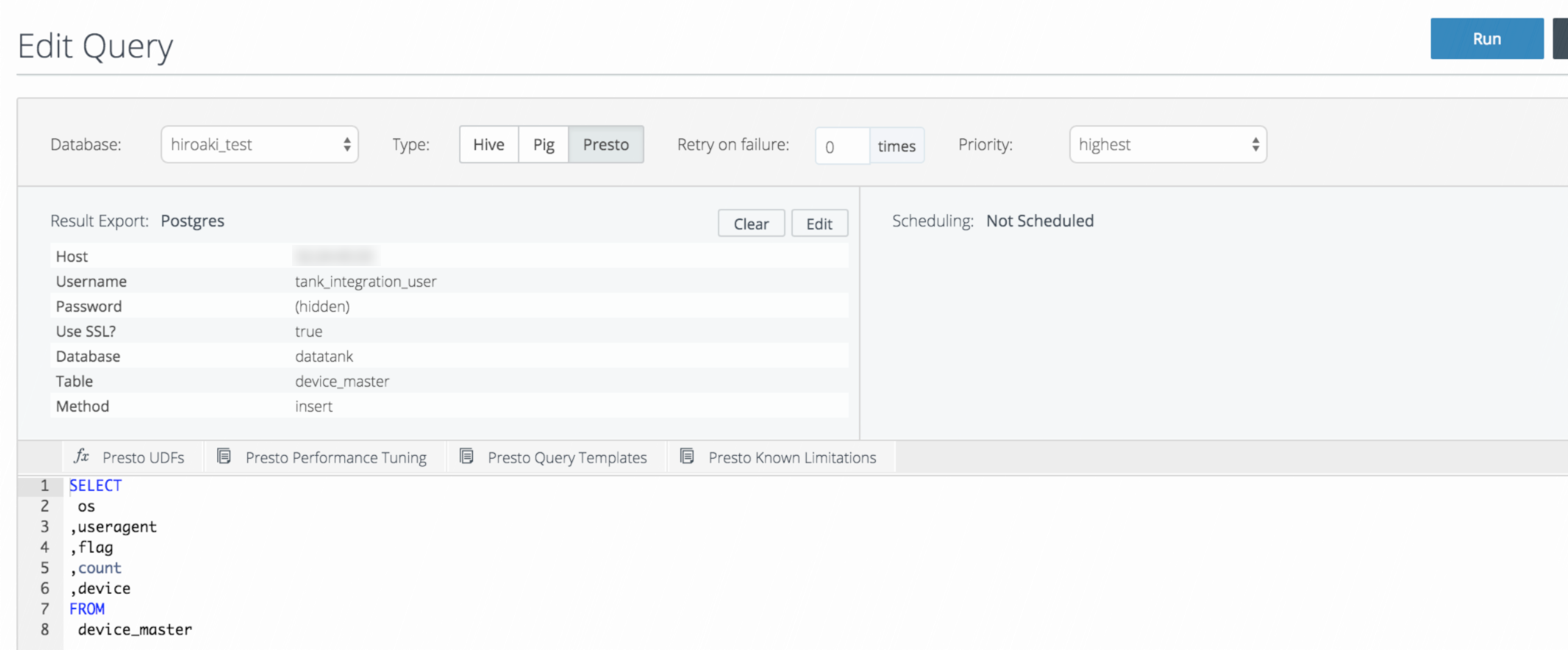
2, Datatankに入っているか確認
$ psql -h XX.XX.XX.XX -U tank_user datatank
> select * from device_master
3, EmbulkでElasticsearchにデータを投入
$ embulk run config/config.yml

4, kibanaからデータを確認

終わりに
本当は今までクエリでセグメントを作るためのログを揃えたり、クエリを書いてきたので
まとめにしようと思っていたが、Embulkに気づくまでに時間がかかってしまったので可視化
までとなってしまったのは反省です。
またやって疑問に思ったことと要望ですが、
- embulk-input-tdは何故ない?
(apiから想像するにデータ結果を返すapiが無いからなのか?jobid返ってくる...それを待ってデータセットを取得する面倒??) - DataConnectorのelasticsearchはそろそろ出るのか。
- そして来年はTreasureData内にViewerが付くといいですね!