はじめに
ARP、Address Resolution Protocol、あーぷ
世界で少なくとも10億人は何らかの形で使ったことがあるはずのもの、ARP ![]()
もう30年以上使われているプロトコルなのにいまだに人類はこのARP周りのトラブルに頭を悩まされている ![]()
今回はそんなARPについて以外と知られていないであろうマニアックなことを書きたいと思います
他にもこんなあるあるあるよ!という方は是非コメント下さい ![]()
ARPは一往復で両機器のARP tableが更新される
例えばマシンA、マシンBがあったとして、マシンAがARP requestを投げ、マシンBがARP replyを返したとする。
この段階でマシンAがマシンBのARP tableを学習をするだけでなく、マシンBもマシンAのARP tableを学習する。
もっと言うと、同じセグメントにいるマシンCもマシンAのARP tableを学習する。
つまりはARP requestを受信したタイミングで、受信側マシンもARP tableを学習するということだ ![]()
ふーん、と思う方が大多数だと思うが、実はIPv6のNDPではこうではなく、各マシンそれぞれでNS(Neighbor Solicitation)、NA(Neighbor Advertisement)のやり取りが必要となる。
ARPはUnicastのものもある
ARPと言えば、必ずBroadcastだと思いがちだが、UnicastのARPもある ![]()
最初のARP Requestは必ずbroadcastで行われる必要があるが、ARP Replyや、その後ARP tableの更新をする際のARP RequestはOSの実装にもよるが、大抵はunicastになる。
RFC826の一番下方に一応記載があるが、非常に分かりづらい。RFCの優柔不断さにも困ったもんだぜ ![]()
Another alternative is to have a daemon perform the timeouts.
After a suitable time, the daemon considers removing an entry.
It first sends (with a small number of retransmissions if needed)
an address resolution packet with opcode REQUEST directly to the
Ethernet address in the table. If a REPLY is not seen in a short
amount of time, the entry is deleted. The request is sent
directly so as not to bother every station on the Ethernet. Just
forgetting entries will likely cause useful information to be
forgotten, which must be regained.
ARPはIPパケットではない
これも良く勘違いされることがあるが、ARPはIPパケット(Ethernetタイプ番号0800)ではない ![]()
destination IPヘッダもなければ、source IPヘッダもない。
じゃあIPの情報はどこにあるんだよ?というとそれらの情報はARPのヘッダに記載されている。
百聞は一見にしかずだと思うので、パケットキャプチャの画面キャプチャを貼っておく ![]()
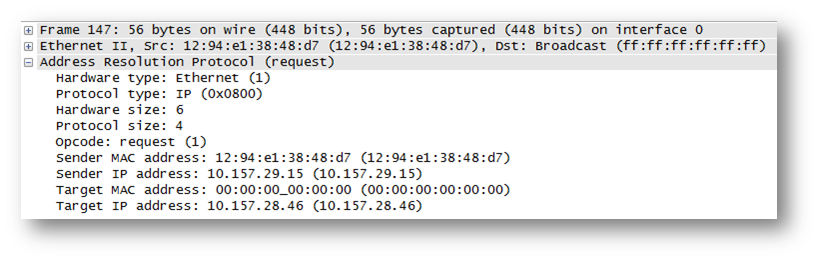
これも、だからどーした、と思われる話かもしれないが、QoSなどでARPをACLでひっかけるときに注意が必要になる。
要はIPパケットではないので、255.255.255.255といった形でIPベースでの表現では引っかけられないのだ。
ffff-ffff-ffffという形でEthernetフレームベースでのBroadcastとして表現するか、Ethernetタイプ番号0806で引っかけるか、"match ARP"みたいにARPとして引っかけるかしかない。(match arpのような形でinterface単位でQoSをかけられる機器を僕は知らない)
ARPはCPUを食う
例えば、Who has 192.168.1.1?というARP Requestを投げたとしよう。
このときのdesctination Ethernetアドレスはff:ff:ff:ff:ff:ffでブロードキャスト。
なので、これを受信した同一セグメントの全マシンはEthernetアドレスを見ただけでは「もしかしたら自分かも」と考え、ARPパケットの中身を見て、ようやく自分は関係ない、ということで破棄をする。
ARPの中身を見て判断、という時点でNICレベルでの処理は難しく、CPUまで判断を仰ぐ形になる。
これもふーん、そりゃそうだろ、と思うかもしれないが、IPv6のNSは、要請ノードマルチキャストアドレス(Solicited-Node multicast address)を使うので、賢いNICだったら、NICレベルで破棄できるのだ。
(何でNICレベルで破棄できるのか、書くと長くなるので割愛しますが、もし反響が大きかったら別で記事書きます)
ちなみに、ARPのBroadcast Stormが発生すると、普通のマシンのCPU負荷はおそらく100%近くまで持っていかれるだろう ![]() (昔検証したがトラウマになりその後二度と検証できていない)
(昔検証したがトラウマになりその後二度と検証できていない)
トラフィック切替時のARP学習に注意しよう
例えば、Active/Standbyの冗長構成のL3スイッチをメンテナンスでトラフィックを切り替えることを想定しよう。
Active側L3スイッチで10,000個のARPを学習している状態でトラフィック切り替えを行うと、Standby側機器はARP tableを持っていない宛先に対して急いでARP学習をしないといけない。
その際に数が多かったりすると、ARP Requestの送信やARP Replyを受信しきれず、上手くARP解決されないことがある。
また、機器の実装にもよるが、最初のARP解決に失敗すると、次は20秒程度待たないとARP Requestの再送は行われなかったりする ![]()
要は運が悪いと何故か20秒程度切り替えに時間がかかる、ということが発生し得るのだ。
この手の障害があった際にはARPを疑ってみよう。
ARPの取りこぼしに注意しよう
例えば、L3スイッチAとL3スイッチBが接続されていて、link upするやいなやその部分にトラフィックが流れ、通信が始まるような場合、まずARP解決をしなくてはいけない。
link upする際にL3スイッチAの方がごくわずかに先にlink upしfowarding readyな状態になり、L3スイッチBの方がforwarding readyになるのに時間がかかるような場合、L3スイッチAから送られるARP RequestがL3スイッチBでdropされてしまうことがあり得る。いわゆる相性問題というやつだ ![]()
双方向でトラフィックが発生する場合には、L3スイッチBからのARP RequestでARP解決されるはずだが、L3スイッチA側からのみ通信が始まるような通信の場合、運が悪いと通信が始まるまでに20秒程度時間がかかることがあったりする。
この手のトラブルはなかなか気づかず、ついつい気のせい木の精、などと言ったりすることが多いが、そんなことはない。ARPの仕業だ ![]()
大量のARP更新には落とし穴があることも
通常、ARP table更新のためのARP Requestは、ARP expireされるある一定時間前にARP更新のRequetstが(Unicast)で行われる。
各アドレス毎にそれぞれ適切なタイミングでARP Requestを投げてくれれば良いが、とあるルータなどは1分間隔にARP expireが近いものをチェックし、まとめてARP Requestを送信するものがあったりする。
例えば10,000個のARPを学習していて、ARP timerを5分などに短く設定している場合、一編に2,000個くらいのARP Requestをドーンと送り、2,000個のARP Replyがドーンと返ってくるハメになる ![]()
加えてルータには自衛機能があったりして、ARP受信数が制限されていたりするので、自分で送ったARP RequestのReplyを処理できない、というなんともお粗末な事象が起きたりする ![]()
以上、ARPトラブルあるあるでした。
他にもこんな困った事象が起きたぜ、なんていう方がいれば共有いただけると助かります ![]()