(2019/10/25 追記)
2019/10/19に33店舗目である、炭焼きレストランさわやか浜松遠鉄店がオープンしたため、記事を一部修正しました。
きっかけ
静岡県内のみ店舗を持つハンバーグレストランの炭焼きレストラン さわやか(以下、単にさわやかと表記する)へ行ったことがある人はわかると思いますが、以下のようなハンバーグ用のマットが敷かれたときがありました。
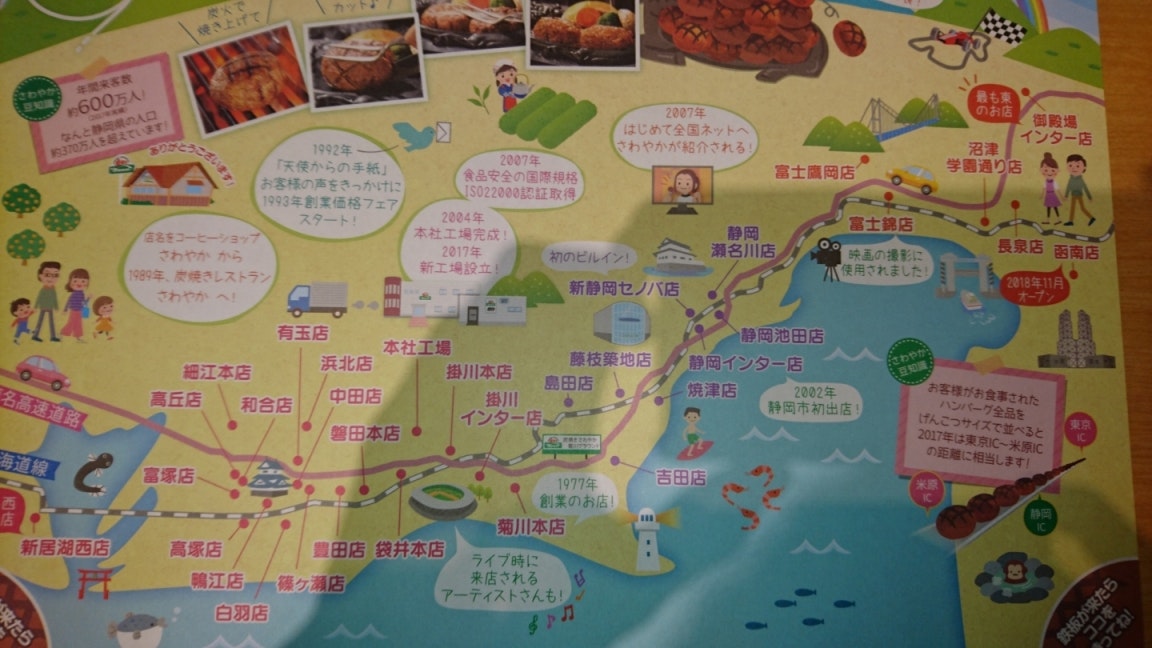
これは静岡県内にあるすべてのさわやかの店舗を大まかに地図で図示したマットですが、初めてさわやかに入店したとき、こんなに多くの店舗があるのかと驚いた記憶があります。しかし、当時何を思ったのか、「これ、すべてのさわやかの店舗を車で一巡すると、静岡県の一巡旅行ができるのでは?」と考えるようになってきました。されども、一時期車のガソリンが高くなったときもあるし、静岡県は無駄に東西に長い県なので、なるべく無駄に移動したくないよなぁ…なんて考えている内に、昔ちょこっとだけ勉強していた組合せ最適化問題の1つである巡回セールスマン問題(Traveling Salesman Problem)の内容が、ふと頭の中をよぎりました。そこで、自分自身の復習を兼ねて、移動時間を最小にするさわやかの全店舗の巡回ルートを考えてみようと当記事を作ってみたというのが、たいへん自己満足的なきっかけです。
なお、この記事の掲載内容は、さわやか株式会社様の利益向上ではなく、あくまで私自身の所見であることを特に強調させてください。また、数学の記号が多く登場してきますので、そういうのが苦手な方は、適当にすっ飛ばしながら読んでいただけると幸いです。
グラフ理論の簡潔な紹介
最初に、本記事で取り扱うにあたって、必要最小限のグラフ理論の知識を紹介します。定義を羅列しただけであるため、より具体的な説明を知りたい方は、恐縮ですが各々リンク先を参照してください。
記号表記
この記事では、有限個の**頂点(Vertex)を$V$という集合、ある2つの頂点同士を結んだ辺(Egde)を$E$という集合として表わすとします。また、これらの頂点と辺で構成されるグラフを$G = (V, E)$と表わすとします。あるグラフ$G = (V, E)$の頂点の個数を$|V|$、辺の個数を$|E|$と表わすとします。これらは、それぞれ単に$V$、$E$と表わしている文献も存在します。ある頂点に接続されている辺の個数を、頂点の次数(Degree)**といいます。
グラフ$G = (V, E)$の例はWikipediaを参照してください。
有向グラフ、無向グラフ
グラフ$G$各辺の向きを区別する場合、このグラフを**有向グラフ(Directed Graph)といいます。一方、各辺の向きを区別しない場合は無向グラフ(Undirected Graph)**といいます。
本記事では、無向グラフのみ扱います。
完全グラフ
あるグラフにおいて、すべての2つの頂点同士に辺が結ばれている場合、そのグラフを完全グラフ(Complete Graph)といいます。
路、閉路、ハミルトン閉路
グラフ内の2つの頂点において、複数の辺を1本の線で辿ることができる場合、この線を路(Path)といいます。
路のうち、スタート地点の頂点とゴール地点の頂点が一致する場合は、この路を閉路(Cycle)といいます。
閉路のうち、辿った頂点の重複がない場合、すなわち、すべての頂点を1度だけ通過する閉路をハミルトン閉路(Hamiltonian Cycle)といいます。
連結グラフ、非連結グラフ
あるグラフの任意の2つの頂点間の路が存在する場合は**連結(Connected)であるといい、そのグラフを連結グラフ(Connected Graph)といいます。一方、連結でないグラフを連結グラフ(Disconnected Graph)**といいます。
オイラーグラフ、オイラー路
すべての辺を辿る路が存在するグラフ、すなわち、一筆書きできるグラフを**オイラーグラフ(Eulerian Graph)**といい、その路をオイラー路(Eulerian Path)といいます。
木、最小全域木
閉路を持たない連結グラフを木(Tree)といいます。
あるグラフ$G = (V, E)$において、すべての頂点$V$と辺$E$の一部で構成された木を全域木(Spanning Tree)といいます。
このグラフの辺$E$のそれぞれに重みが存在する場合、全域木の辺に存在する重みの総和が最小となる全域木を最小全域木(Minumum Spanning Tree)といいます。
マッチング、完全マッチング
グラフの辺$E$の部分集合$M \subseteq E$において、各頂点が$M$に属した辺1つだけ結ばれている場合、$M$をマッチング(Matching)といいます。特にマッチング$M$が、グラフのすべての頂点を結んでいる場合、$M$を**完全マッチング(Perfect Matching)**といいます。
巡回セールスマン問題
ここでは、巡回セールスマン問題についての説明と、巡回セールスマン問題の特別なケースを考えます。
定義、モチベーション
数学的に、巡回セールスマン問題は以下のように定義されます。
$|V|$個の頂点から構成される完全無向グラフ$G = (V, E)$において、各辺$(i, j) \in E$に対しコスト$c_{ij}$が与えられる。ここで、任意の辺$(i, j) \in E$に対し、$c_{ij} \geq 0$、$c_{ij} = c_{ji}$をみたすとする。
このとき、同じ頂点には2度通らずに、すべての頂点を1回だけ巡回するハミルトン閉路において、すべての辺に対する合計コストの値を最小にするものを求めよ。
具体的に先程のさわやかのシチュエーションに合わせて考えてみましょう。頂点集合$V$をさわやかの店舗の集合、コスト$c_{ij}$をさわやかの店舗$i$からさわやかの店舗$j$までの移動時間とすると、さわやかの全店舗を巡回する際の合計移動時間を最小にしなさい、という意味になります。
$|V|$個の頂点のある完全グラフのうち、すべての頂点を1度だけ通って巡回するルートの場合の数は、$\frac{(|V| - 1)!}{2}$通り存在します。これらすべての場合の巡回ルートの合計移動時間を計算し、それらの最小となる巡回ルートを求めれば良い…のですが、このような総当たりで解こうとする方法はあまりにも時間がかかりすぎてしまい、現実的ではありません。さわやかの店舗は2019/10/25現在で33店舗存在しますが、これらの店舗を巡回するルートの場合の数は$( 32 \times 31 \times \dots 2 \times 1) / 2 \simeq 1.32 \times 10^{35}$通りあり、これらをプログラムで個別で合計移動時間を計算するのは現実的ではありません。学術上では、巡回セールスマン問題は**NP困難(NP Hard)**な問題と言われます。
そこで、厳密に合計移動時間を最小にする巡回ルートを求めようするのではなく、厳密な合計移動時間の最小値よりも多少大きくなって良いので、それよりもずっと速く合計移動時間の最小値っぽい近似値を求めることを考える、というモチベーションとなります。
メトリック巡回セールスマン問題
**メトリック巡回セールスマン問題(Metric Traveling Salesman Problem)**とは、巡回セールスマン問題の中での特殊な問題です。巡回セールスマン問題におけるコスト$c_{ij}$に対し、以下の性質をさらにみたすように導入します。
任意の2辺$(i, j) , (j, k), (i, k) \in E$に対し、$c_{ik} \leq c_{ij} + c_{jk}$(三角不等式)が成立する。
つまり、コスト$c_{ij}$を2点$i$、$j$における距離関数として、巡回セールスマン問題を定義したものがメトリック巡回セールスマン問題です(位相幾何学をご存知ではない方は、この1文を無視して構いません)。
これで巡回セールスマン問題の難しさが解消される…と思いきや、残念ながら三角不等式の仮定を導入してもなお、メトリック巡回セールスマン問題はNP困難な問題のままです。しかし、三角不等式の性質を抜かしてしまうと、近似アルゴリズムを考えることすら非常に難しくなってしまうため、以降すべてのコスト$c_{ij}$が上記の三角不等式をみたすという前提で進めます。なお、専門書によっては、メトリック巡回セールスマン問題のことを、単に巡回セールスマン問題として記述している場合もあります。本記事でも、「メトリック巡回セールスマン問題」のことを、単に「巡回セールスマン問題」として記述していきます。
ユークリッド巡回セールスマン問題
**ユークリッド巡回セールスマン問題(Euclidean Traveling Salesman Problem)**とは、上記で述べたメトリック巡回セールスマン問題の中での特殊な問題です。名前から想像できますが、メトリック巡回セールスマン問題のコスト$c_{ij}$における距離関数にユークリッド距離としたものがユークリッド巡回セールスマン問題です。要するに、2頂点間のコストをそれらの直線距離として考えた問題に相当します。
しかし、本記事におけるコストは、さわやか2店舗間の直線距離ではなくさわやか2店舗間の移動時間として考えているため、ユークリッド巡回セールスマン問題ではありません。つまり、本記事で取り扱うお題目は、メトリック巡回セールスマン問題ではあるがユークリッド巡回セールスマン問題ではない、ということです。
ユークリッド巡回セールスマン問題は、後に出現するAroraのアルゴリズムが適用できる、というメリットがあるため、あくまで本記事におけるオマケとして考えておいてください。
巡回セールスマン問題を解く近似アルゴリズム
ここでは、巡回セールスマン問題を解く近似アルゴリズムの代表的なものの中から、一部を紹介します。
なぜ近似アルゴリズムを使うのか?
**近似アルゴリズム(Approximation Algorithm)**とは、ある最小化問題における厳密な最適解を近似した近似解を得るためのアルゴリズムです。厳密な最適解を求めるのが難しいNP困難な問題を解く場合、近似アルゴリズムを使用することが多いです。巡回セールスマン問題で置き換えると、厳密な最適解とは最も合計コストが小さくなる最適な巡回ルートであり、その近似ルートが近似解に相当します。しかし、そもそもなぜ近似アルゴリズムが存在するのでしょうか?
以前述べた通り、巡回セールスマン問題の厳密な最適解は、$\frac{(|V| - 1)!}{2}$通りの場合の巡回ルートを総当たりで考えれば良いが、それだと現実的ではないからですね。このことは、巡回セールスマン問題の厳密な最適解を解く反復計算回数は$O(|V|!)$、すなわち、入力サイズ$|V|$の階乗時間で表わされる反復計算回数となってしまうから、という意味です。階乗時間である反復計算回数$O(|V|!)$は、頂点数$|V|$が増加すると超爆発的に増加していってしまいます。一般的に$|V| \geq 20$となると現実的な時間で解くのは非常に厳しいと言われています。
一応、Held–Karpのアルゴリズムを使うと厳密な最適解を求められるのですが、コイツの反復計算回数は階乗時間の$O(|V|!)$よりマシになった$O(|V|^2 2^{|V|})$です。しかし、Held–Karpのアルゴリズムも指数時間である$O(2^{|V|})$のせいで爆発的に増加していってしまい、現実的な時間で解くのは依然として厳しいです。そのため、$O(|V|!)$や$O(2^{|V|})$よりはるかに小さい$O(|V|)$、$O(|V|^2)$、$O(|V|^3)$といった、多項式時間での反復計算回数で求めていく近似アルゴリズムを用いて、現実的な時間で近似解を解められる近似アルゴリズムを考えていきましょう。
参考までに、ある値の$n$での$n^2$、$n^3$、$2^n$、$n!$の値を以下に載せますが、$n!$の爆発力が目に見えてわかります。
| $n$ | $n^2$ | $n^3$ | $2^n$ | $n!$ |
|---|---|---|---|---|
| $n = 5$ | 25 | 125 | 32 | 120 |
| $n = 10$ | 100 | 1000 | 1024 | 3628800 |
| $n = 32$ | 1024 | 32768 | 4294967296 | 2.6×10^35 |
| $n = 50$ | 2500 | 125000 | 1.1×10^15 | 3.0×10^64 |
| $n = 75$ | 5625 | 421875 | 3.8×10^22 | 2.5×10^109 |
| $n = 100$ | 10000 | 1000000 | 1.3×10^30 | 9.3×10^157 |
なお、近似アルゴリズム以外のアルゴリズムとして、メトリック巡回セールスマン問題でなかったとしても、入力サイズの多項式時間で解けるかどうか関係なしに、近似解や厳密解を求める**メタヒューリスティクス(Meta-heuristic)**も存在します。巡回セールスマン問題におけるメタヒューリスティクスの有名な例を、以下にざっと挙げます(もっとあるかもしれません)。
- 焼きなまし法(Simulated Annealing)
- ニューラルネットワーク(Neural Network)
- 遺伝的アルゴリズム(Genetic Algorithm)
本記事では、理論的に精度保証された近似アルゴリズムのみ取り扱い、メタヒューリスティクスは取り扱いません。そちらの方を期待して当記事をご覧になった方は、申し訳ございません。
精度保証付き近似アルゴリズム
近似アルゴリズムには様々な種類があるのですが、その中でも厳密な最適解になるべく近い近似解を出力するような近似アルゴリズムが性能が良いというのは、直感的にも納得がいきます。そこで、それぞれの近似アルゴリズムの性能を格付けするため、どれくらい厳密な最適解に近づけることができるのかという精度保証付きの近似アルゴリズムの考え方を導入します。この考え方は、巡回セールスマン問題以外にも、様々な組合せ最適化問題の近似アルゴリズムを考えるにあたって重要となるものです。
ポイントは、近似度(Approximation Ratio)です。ある近似アルゴリズム$A$の近似度が$\alpha$であるならば、$A$にどんな値を入力しても、$A$の近似解によって得られる近似値は最適値の$\alpha$倍以下である 、というのが近似度の定義です。すなわち、以下の不等式をみたすように、$\alpha$を定義します。
$(Aの近似値) \leq \alpha \cdot (Aの最適値)$
巡回セールスマン問題で置き換えると、最適値とは最適な巡回ルートでの合計移動時間であり、近似解とは近似アルゴリズムによって求められた近似巡回ルート、近似値とは近似巡回ルートの合計移動時間に相当します。近似度が$\alpha$である近似アルゴリズムのことを、$\alpha$-近似アルゴリズムといいます。この定義より、巡回セールスマン問題では、近似度が1に近ければ近いほど、より性能が良いアルゴリズムであるとわかります。
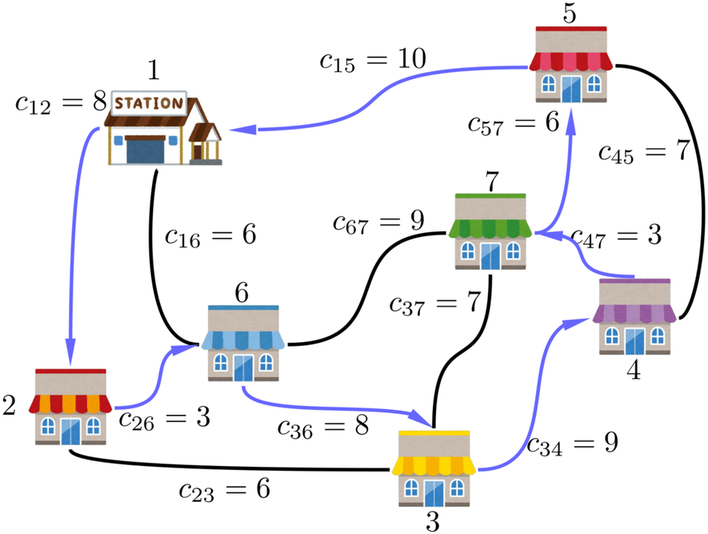
例えば、以下の例を扱いましょう。
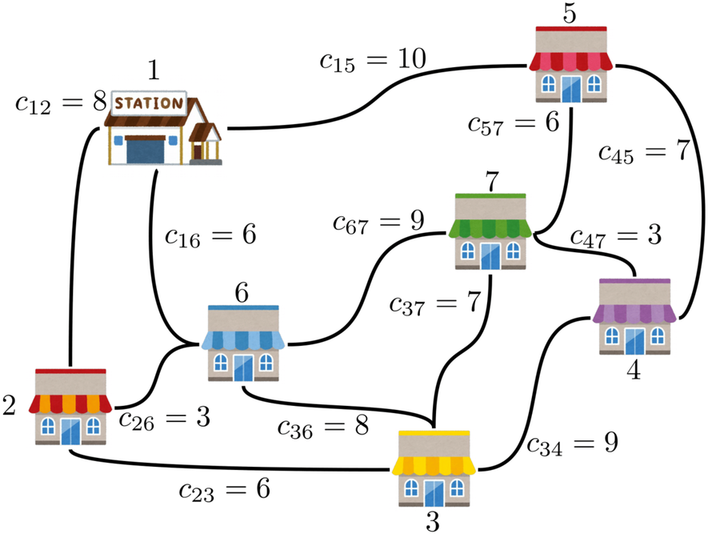
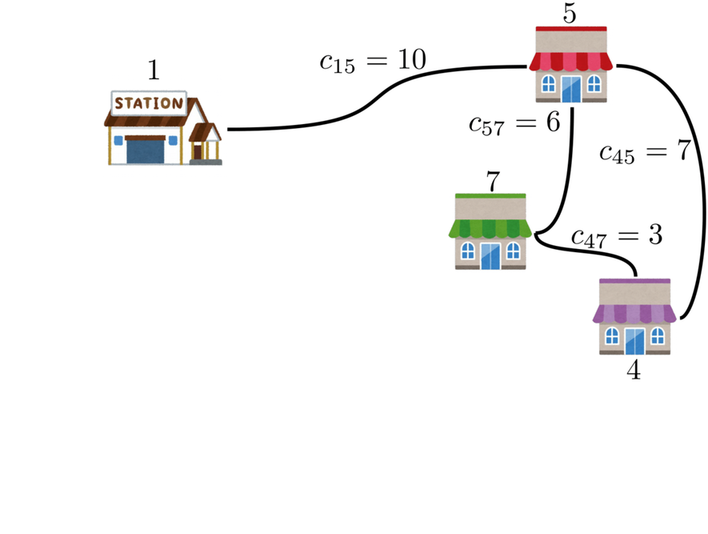
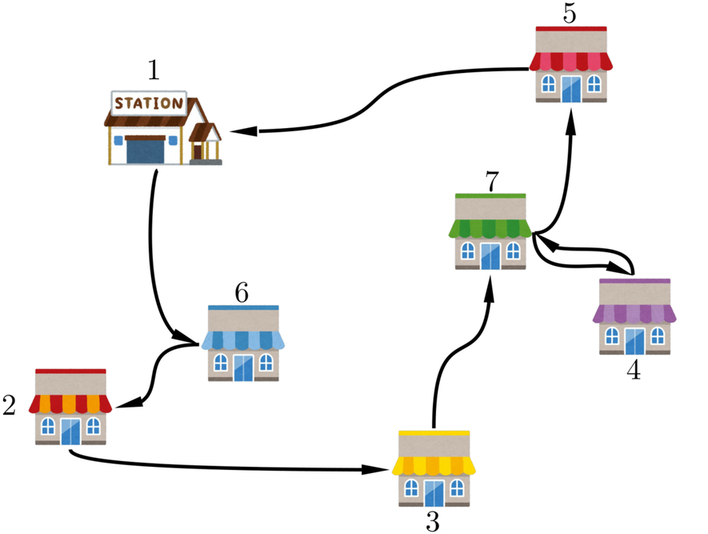
スタート地点の駅である頂点1から、各頂点2〜7を巡回するルートを求める図となります。各頂点同士は黒実線で描かれた辺で接続され、その辺のコストを$c_{ij}$としています。
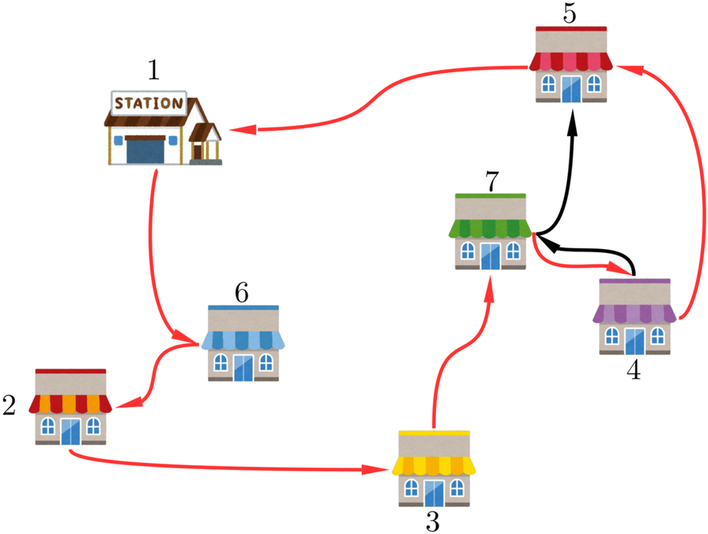
先にネタばらしをしちゃいますが、この図における最適ルートは以下の赤色の矢印の通りです。
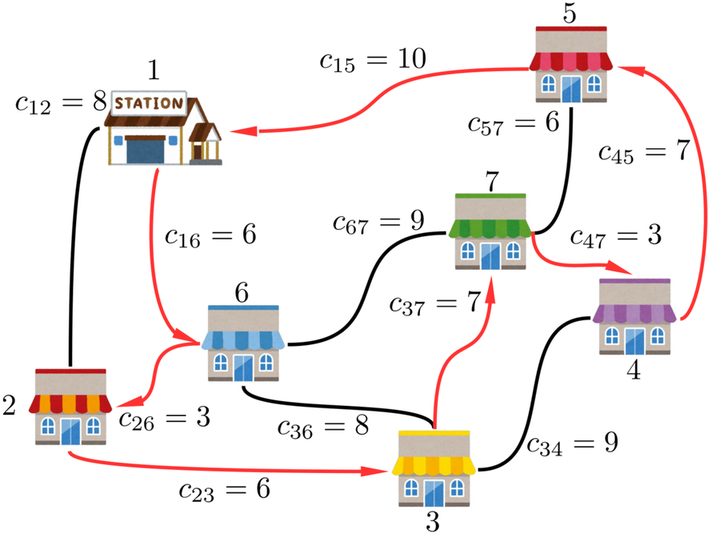
この最適ルートを通るときの合計コストは6+3+6+7+3+7+10=42となります。
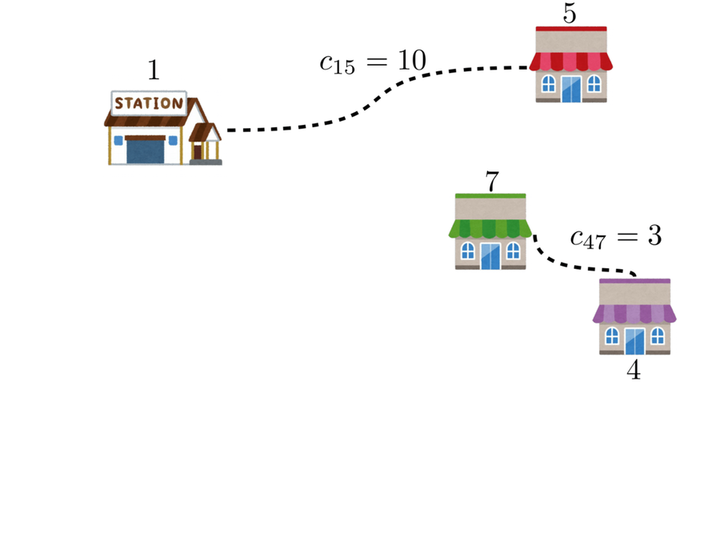
しかし、この図によって考えるグラフは、よく見ると完全グラフではなく、7つの頂点のうち辺が存在しないものが何個もあります。例えば、頂点1と頂点2はコスト8として接続されていますが、頂点1と頂点3は接続されていません。
このままでは、巡回セールスマン問題のモデルに適用できません。そこで、ちょっと強引に頂点1と頂点3を接続してみましょう。その代償として、本来接続するべきではない頂点同士を接続するため、コスト$c_{13}$の値を非常に大きくして貰います。…しかし、すべてのコストは三角不等式をみたす前提があるのでした。例えば、三角不等式$c_{13} \leq c_{12} + c_{23}$に当てはめて考えると、$c_{12} = 8$、$c_{23} = 6$のため、$c_{13}$の上界は14と与えられてしまいます。同様に$c_{13} \leq c_{14} + c_{43}$、$c_{13} \leq c_{15} + c_{53}$…と考えると、$c_{13}$は$c_{14}$、$c_{15}$より大きくできません。そのため、接続されていない辺のコストを定める際は、三角不等式に違反しないように、できるだけギリギリ大きくしていって考えることにより、完全グラフではないグラフでも完全グラフっぽく考えることができます。
以上のように、他の接続されていない辺のコストを考えることで、以下のようなコスト行列を得ることができます。なお、接続されていない辺のコストを斜体表記にしています。
| $c_{ij}$ | $j = 1$ | $j = 2$ | $j = 3$ | $j = 4$ | $j = 5$ | $j = 6$ | $j = 7$ |
|---|---|---|---|---|---|---|---|
| $i = 1$ | 8 | 14 | 17 | 10 | 6 | 15 | |
| $i = 2$ | 8 | 6 | 15 | 18 | 3 | 12 | |
| $i = 3$ | 14 | 6 | 9 | 13 | 8 | 7 | |
| $i = 4$ | 17 | 15 | 9 | 7 | 12 | 3 | |
| $i = 5$ | 10 | 18 | 13 | 7 | 15 | 6 | |
| $i = 6$ | 6 | 3 | 8 | 12 | 15 | 9 | |
| $i = 7$ | 15 | 12 | 7 | 3 | 6 | 9 |
さて、近似度の説明に戻りましょう。仮に、$X$という名前のアルゴリズムの近似度が1.5(=$X$は1.5-近似アルゴリズム)、$Y$という名前のアルゴリズムの近似度が2(=$Y$は2-近似アルゴリズム)、であるとします。先程の近似度の定義より、$X$によって出力される近似巡回ルートの合計コストは、高々、最適ルートの合計コストである42の1.5倍である61以下であるといえます。同様に、$Y$だと、高々、42の2倍である84以下であるといえます。
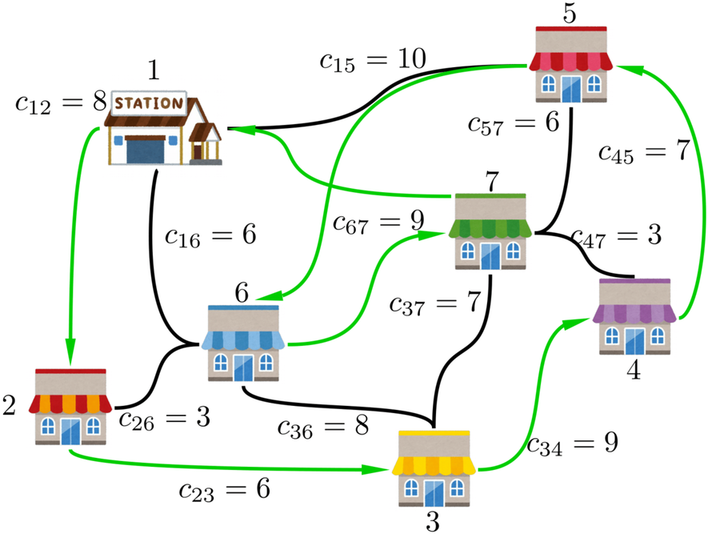
ここで、先程の赤色の最適ルートより無駄にコストがかかってしまう、上記の緑色の巡回ルートを考えてみると、合計コストは8+6+9+7+15+9+15=69となります。$X$は61以下の合計コストを持つ近似巡回ルートしか出力しないため、絶対に緑色の巡回ルートは出力しません。一方、$Y$は84以下の合計コストを持つ近似巡回ルートしか出力しないため、緑色の巡回ルートを出力されてしまう可能性があります。$Y$より$X$の方が、より性能が良い近似アルゴリズムだという意味は、これに相当します。
一方、緑色の巡回ルートよりマシになったけど、赤色の最適ルートには及ばない、上記の青色の巡回ルートを考えてみます。この合計コストは8+3+8+9+3+6+10=47です。そのため、61以下の合計コストを持つ巡回ルートしか出力しない$X$も、84以下の合計コストを持つ巡回ルートしか出力しない$Y$も、青色の近似巡回ルートを出力されてしまう可能性があります。
以上が、図を用いた近似度の説明となります。
2重木アルゴリズム
2重木アルゴリズム(Double Tree Algorithm)は、巡回セールスマン問題に対する近似アルゴリズムとして、有名なものの1つです。三角不等式の性質を用いると、2重木アルゴリズムは2-近似アルゴリズムである特徴を持ちます。
2重木アルゴリズムの具体的な流れを、以下に示します。わかりやすいように、先程の図の例を用いて、1ステップごとに説明しています。
-
以下のパラメータを入力する。
- 完全無向グラフ$G = (V, E)$
- コスト$c_{ij} \ ((i, j) \in E)$
- 巡回ルートのスタート地点の頂点
-
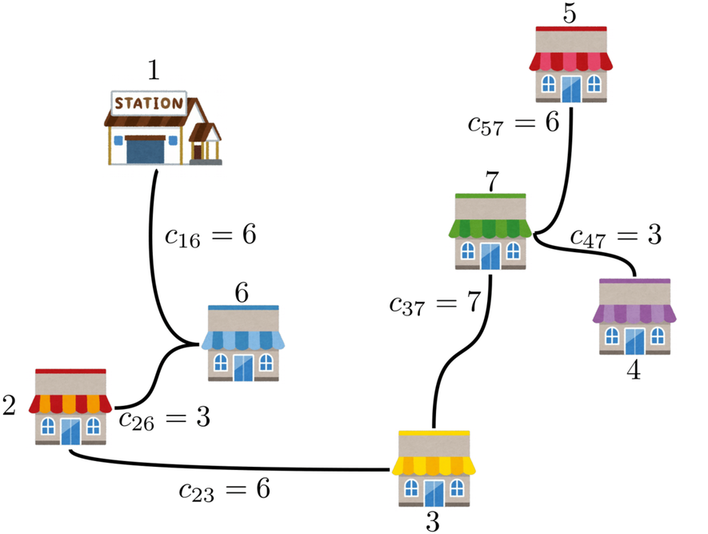
$G$の最小全域木を生成する。
- 最小全域木を生成するアルゴリズムとして、主にKruskalのアルゴリズムとPrimのアルゴリズムがあり、それぞれ$O(|E| \log |E|)$、$O(|E| + |V| \log |V|)$のように$|V|$や$|E|$の多項式時間で実行できます。そのため、$G$が完全グラフのような、辺の数$|E|$が頂点の数$|V|$と比べて非常に多くなる場合は、Primのアルゴリズムの方が少ない反復計算回数で済む可能性が高いです。なお、$O( \log |E| )$は、定数時間の$O( 1 )$よりも大きく、多項式時間の$O( |E| )$より小さい計算量として考えてください。
- 以下の図の例では一意に最小全域木が定まってしまいますが、一般的に最小全域木は一意に定まらないことに注意してください。
-
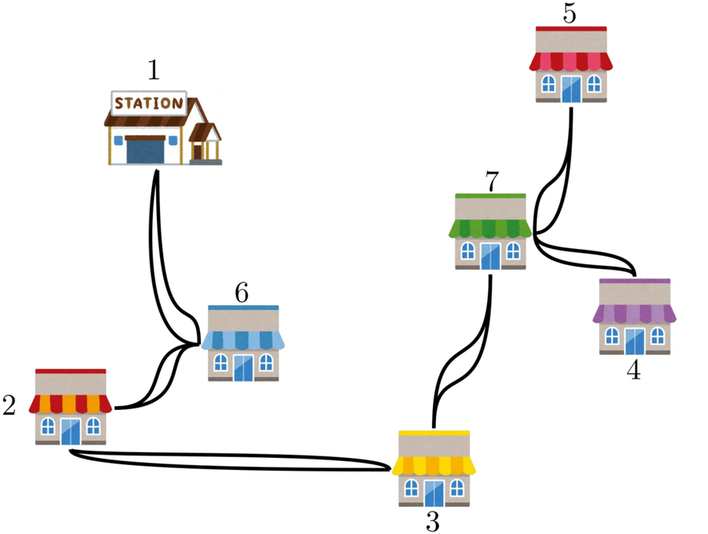
2で生成した最小全域木の各辺を2重化したグラフ(=2重木)を生成する。
- この2重木はオイラーグラフとなります。したがって、一筆書きすることができます。
-
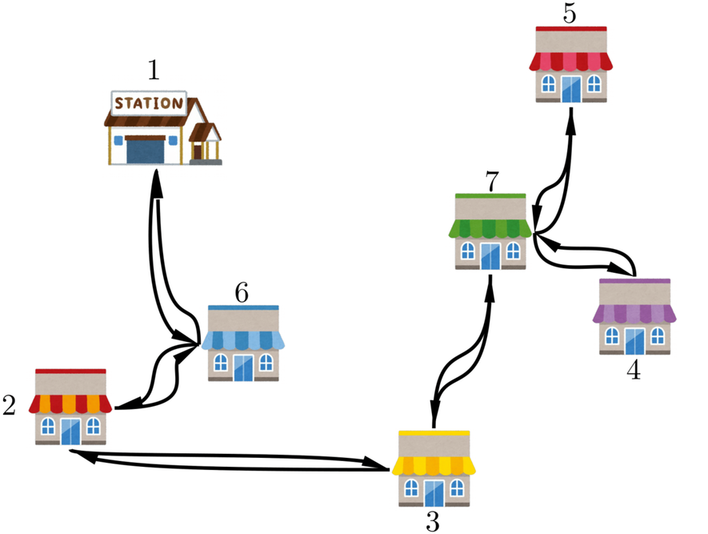
3で生成した2重木を、0で入力したスタート地点から一筆書きしたオイラー路を生成する。
- オイラーグラフから一筆書きするアルゴリズムはFleuryのアルゴリズムが有名であり、$O(|E|^2)$の多項式時間で解くことができます。なお、Fleuryのアルゴリズムについては、この記事では詳しく扱いません。
- 一般的にオイラー路は一意に定まらないことに注意してください。
- 以下の図では、頂点1→頂点6→頂点2→頂点3→頂点7→頂点4→頂点7→頂点5→頂点7→頂点3→頂点2→頂点6→頂点1の順でオイラー路を生成しています。
-
4で生成したオイラー路において、各頂点を順に辿り、2回目以降に現れた頂点を取り除いた閉路を生成する。
- この閉路はハミルトン閉路となります。
- 以下の図では、4で生成したオイラー路で頂点2、3、6が2回、頂点7が3回現れているため、それらの2回目以降を取り除いた頂点1→頂点6→頂点2→頂点3→頂点7→頂点4→頂点5→頂点1の順でハミルトン閉路を生成します。
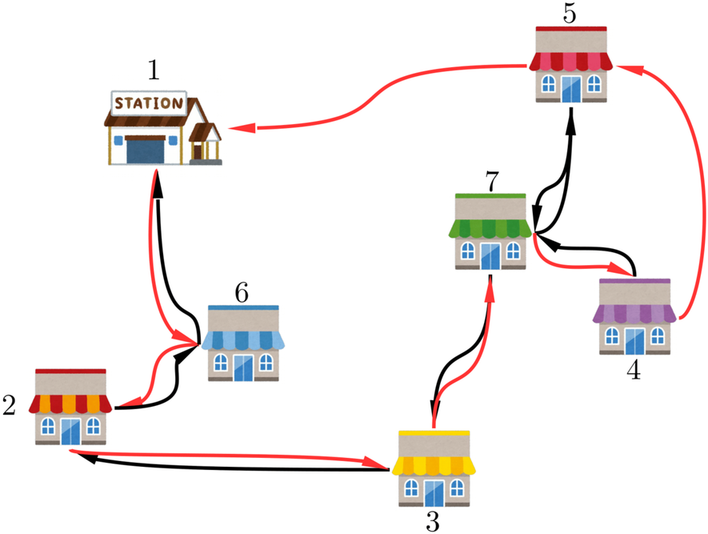
-
5で生成した閉路を出力して、終了する。
1で生成する最小全域木と3で生成するオイラー路は一意には定まらないため、これらの生成の仕方によって出力する巡回ルートが異なり、合計コストの値も異なります。
Christofidesのアルゴリズム
Christofidesのアルゴリズム(Christofides Algorithm)は、1976年にNicos Christofides氏によって提案されました。Christofidesのアルゴリズムは1.5-近似アルゴリズムであることが特徴です。2重木アルゴリズムよりも良い近似精度が期待できそうですね!
Christofidesのアルゴリズムの具体的な流れを、以下に示します。
-
以下のパラメータを入力する。
- 完全無向グラフ$G = (V, E)$
- コスト$c_{ij} \ ((i, j) \in E)$
- 巡回ルートのスタート地点の頂点
-
$G$の最小全域木を生成する。
-
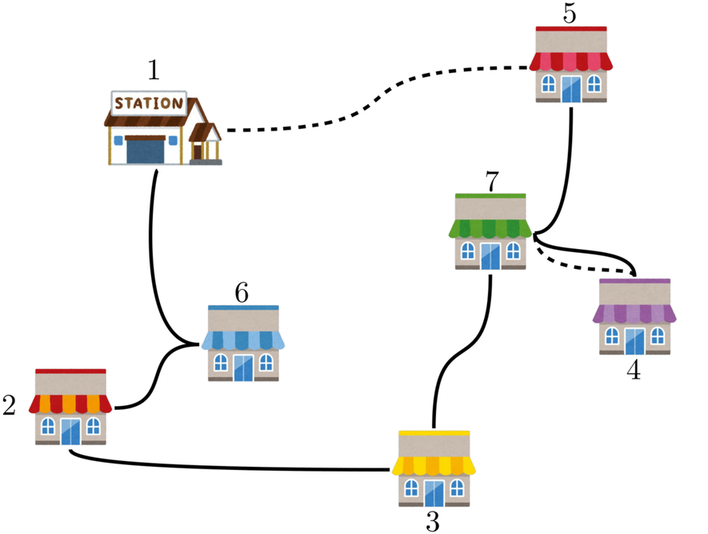
2で生成した最小全域木の各頂点のうち、次数が偶数である頂点をすべて取り除き、残った頂点だけを用いて構成した$G$の部分グラフを生成する。
- 取り除かれずに残った頂点は、握手補題より必ず偶数個存在します。
-
3で生成した$G$の部分グラフから、合計コストが最小となる完全マッチングを生成し、各マッチングの2頂点同士を連結したグラフを生成する。
- 3で生成した$G$の部分グラフの頂点数は偶数であるため、必ず完全マッチングを生成できます。
- この完全マッチングは、**最小重み完全マッチング(Min-weight Perfect Matching)**と呼ばれます。
- 最大マッチングは、Jack Edmonds氏によって提案されたブロッサムアルゴリズムを用いると、$|V|$、$|E|$の多項式時間で求められることができます。最小重み完全マッチングも、これを派生したアルゴリズムによって求めることができます。なお、ブロッサムアルゴリズムについては、この記事では詳しく扱いません。
- あるグラフの最小重み完全マッチングは一意に定まらないことに注意してください。
-
2の最小全域木と、4で生成したグラフを合体したグラフを生成する。
- 合体したグラフはオイラーグラフとなります。したがって、一筆書きすることができます。
-
5で生成したグラフを、0で入力したスタート地点から一筆書きしたオイラー路を生成する。
- 以下の図では、頂点1→頂点6→頂点2→頂点3→頂点7→頂点4→頂点5→頂点7→頂点1のでオイラー路を生成しています。
-
6で生成したオイラー路において、各頂点を順に辿り、2回目以降に現れた頂点を取り除いた閉路を生成する。
- この閉路はハミルトン閉路となります。
- 以下の図では、6で生成したオイラー路で頂点7が2回現れているため、その2回目を取り除いた頂点1→頂点6→頂点2→頂点3→頂点7→頂点4→頂点5→頂点1の順で閉路を生成します。
-
7で生成した閉路を出力して、終了する。
こうしてみると、2重木アルゴリズムと同じ操作をする箇所が多いですね。
Aroraのアルゴリズム
このアルゴリズムは、比較的最近の1998年になって、Sanjeev Arora氏によって提案されました。本人は2010年にゲーデル賞を受賞していますね。Aroraのアルゴリズムは複雑なため、本記事では伏せておきますが、ココに論文がありますので、興味がある方は見ると良いと思います。
Aroraのアルゴリズムの特徴は、近似度を限りなく1に近づけることができる(すなわち、任意の$c > 1$において、近似度を$1 + \frac{1}{c}$と表せられる)確率が1/2以上であることです。しかし、この特徴はユークリッド巡回セールスマン問題を仮定に入れています。コストに「店舗間の移動時間」ではなく「店舗間の直線距離」を用いればユークリッド巡回セールスマン問題となり、Aroraのアリゴリズムのメリットを享受できますが、実用上の面を考慮するとどうしてもグネグネした道路を通ることになってしまい、直線距離として考えにくいんですよね。
Aroraのアルゴリズムは、本記事のような応用面の適用というより、どちらかと言うと理論面の解析で活かされやすいアルゴリズムだと思います。本記事でのAroraのアルゴリズムの紹介は、この辺で留めておきます。
巡回セールスマン問題を解く近似アルゴリズムの実装
ここでは、巡回セールスマン問題を解く2つの近似アルゴリズムをPythonで実装し、それぞれの性能を比較します。
前提条件
完全グラフのコスト行列が手元に控えてある前提で進めます。先程の例題で具体的に示しますと、以下のようなリストが用意していると仮定します。
costMatrix = [[None, 8, 14, 17, 10, 6, 15],
[ 8, None, 6, 15, 18, 3, 12],
[ 14, 6, None, 9, 13, 8, 7],
[ 17, 15, 9, None, 7, 12, 3],
[ 10, 18, 13, 7, None, 15, 6],
[ 6, 3, 8, 12, 15, None, 9],
[ 15, 12, 7, 3, 6, 9, None]]
対角成分はNoneにしていますが、そこは何も参照しないため、何でも構いません。
2重木アルゴリズムの実行
2重木アルゴリズムをPythonで実装してみたところ、以下の通りになりました。
# coding: utf-8
import networkx as nx
def double_tree_algorithm(costMatrix: list, start: int):
"""
2重木アルゴリズムで近似巡回ルートを生成する
Parameters
----------
costMatrix : list
完全グラフのコスト行列
start : int
近似巡回ルートのスタート地点
Returns
-------
route : list
近似巡回ルート
"""
# 1. コスト行列から重み付き完全グラフを生成
graph = _create_weighted_graph(costMatrix)
# 2. Primのアルゴリズムで最小全域木を生成
spanningTree = nx.minimum_spanning_tree(graph, algorithm="prim")
# 3. 最小全域木の各辺を2重化
duplicatedSpanningTree = _duplicate_weighted_graph(spanningTree)
# 4. 2重化した最小全域木からオイラー路を生成
eulerianPath = _create_eulerian_path(duplicatedSpanningTree, start)
# 5. オイラー路からハミルトン閉路を生成
route = _create_hamiltonian_path(eulerianPath)
# 6. ハミルトン閉路を出力して終了
return route
def _create_weighted_graph(costMatrix: list):
"""
完全グラフの合計コストで重み付けした完全グラフを生成する
Parameters
----------
costMatrix : list
完全グラフのコスト行列
Returns
-------
graph : networkx.Graph
重み付き完全グラフ
"""
# 重み付き完全グラフを初期化して辺を追加
graph = nx.Graph()
for i in range(len(costMatrix)):
for j in range(i + 1, len(costMatrix[i])):
graph.add_edge(i, j, weight=costMatrix[i][j])
return graph
def _duplicate_weighted_graph(graph: nx.Graph):
"""
重み付けグラフの辺を2重化する
Parameters
----------
graph : networkx.Graph
重み付けグラフ
Returns
-------
duplicatedGraph : networkx.MultiGraph
引数の重み付けグラフの辺を2重化した重み付けグラフ
"""
# 重み付けグラフを初期化して引数のグラフの各辺を2重化
duplicatedGraph = nx.MultiGraph()
for v in graph:
for w in graph[v]:
duplicatedGraph.add_edge(v, w, weight=graph[v][w]["weight"])
return duplicatedGraph
def _create_eulerian_path(eulerianGraph: nx.MultiGraph, start: int):
"""
オイラーグラフからオイラー路を生成する
Parameters
----------
eulerianGraph : networkx.MultiGraph
オイラーグラフ
start : int
オイラー路のスタート地点
Returns
-------
eulerianPath : list
オイラー路を辿る頂点の順番のリスト
"""
# オイラー路の辺リストを生成
eulerianEdges = list(nx.eulerian_circuit(eulerianGraph, start))
# オイラー路を辿る頂点の順番のリストを生成
eulerianPath = [edge[0] for edge in eulerianEdges]
# オイラー路のスタート地点とゴール地点を一致させる
eulerianPath.append(eulerianEdges[len(eulerianEdges) - 1][1])
return eulerianPath
def _create_hamiltonian_path(eulerianPath: list):
"""
オイラー路からハミルトン閉路を生成する
Parameters
----------
eulerian_path : list
オイラー路を辿る頂点の順番のリスト
Returns
-------
hamiltonianPath : list
ハミルトン閉路を辿る頂点の順番のリスト
"""
# ハミルトン閉路を辿る頂点の順番のリストを初期化
hamiltonianPath = []
# 既出の頂点集合を初期化
existedVertice = set()
# オイラー路を辿る各頂点を辿り、2回目以降に現れた頂点は無視する
for vertex in eulerianPath:
if vertex not in existedVertice:
hamiltonianPath.append(vertex)
existedVertice.add(vertex)
# ハミルトン閉路のスタート地点とゴール地点を一致させる
hamiltonianPath.append(eulerianPath[0])
return hamiltonianPath
一番上のdouble_tree_algorithm()によって2重木アルゴリズムを実行し、その近似巡回ルートを出力します。引数は、前述のコスト行列とスタート地点を示す頂点の番号です。出力値は、2重木アルゴリズムで生成した近似巡回ルートを辿る頂点の順番を表わしたリストです。double_tree_algorithm()の各ステップごとに実行している関数を、順に説明します。
-
NetworkXのライブラリ
networkxに定義されてあるnetworkx.Graphクラスを用いて、各辺をコストで重み付けられたグラフインスタンスを生成する_create_weighted_graph()を実行します。 - 最小全域木を生成する
networkx.minimum_spanning_tree()を実行します。ただし、algorithm引数に何も指定しないとKruskalのアルゴリズムを実行してしまうため、完全グラフでより計算量の少なくなるPrimのアルゴリズムを実行するように、algorithm="Prim"と指定しました。なお、最小全域木を作る際に選ぶ出す頂点が複数通り存在するため、最小全域木は一意に定まりませんが、どうやらnetworkx.minimum_spanning_tree()の中身のソースを見てみると、頂点をランダムに選ばずに静的に選んでいるように見えました。そのため、同じ頂点番号を持つグラフインスタンスでこの関数を何度も実行しても、同じ形の最小全域木を出力されちゃいます。 - 最小全域木の各辺を2重化する
_duplicate_weighted_graph()を実行します。2頂点を接続するグラフの辺が現れるため、networkx.Graphクラスではなくnetworkx.MultiGraphクラスのインスタンスを生成する必要があります。 - オイラー路を生成する
_create_eulerian_path()を実行します。この関数の内部で、オイラー路を構成する頂点のイテレーターを出力するnetworkx.eulerian_circuit()を実行していますが、ゴール地点の頂点がスタート地点の頂点と一致しておらず、ゴール地点1歩手前の頂点でイテレーターが終わっていますので、リストの最後の要素にスタート地点の頂点をそのままコピーしています。なお、オイラー路は一意に定まりませんが、networkx.eulerian_circuit()も例のごとく頂点をランダムに選ばずに静的に選んでいるため、同じ頂点番号を持つグラフインスタンスでこの関数を何度も実行しても、同じ形のオイラー路が出力されちゃいます。 - ハミルトン閉路を生成する
_create_hamiltonian_path()を実行します。2回目以降に現れた頂点をexistedVertice変数に格納し、その要素を無視するようにハミルトン閉路を生成していきます。
先程の図の例に従って近似巡回ルートを2重木アルゴリズムによって出力する場合は、double_tree_algorithm()を以下のように実行します。
>>> from tsr import double_tree_algorithm
>>> costMatrix = [[None, 8, 14, 17, 10, 6, 15],
... [ 8, None, 6, 15, 18, 3, 12],
... [ 14, 6, None, 9, 13, 8, 7],
... [ 17, 15, 9, None, 7, 12, 3],
... [ 10, 18, 13, 7, None, 15, 6],
... [ 6, 3, 8, 12, 15, None, 9],
... [ 15, 12, 7, 3, 6, 9, None]]
>>> route = double_tree_algorithm(costMatrix, 0)
>>> print(route)
[0, 5, 1, 2, 6, 4, 3, 0]
頂点1→頂点6→頂点2→頂点3→頂点7→頂点5→頂点4→頂点1の近似巡回ルート(合計コストは52)が出力されました。なお、図の例ではインデックスが1から始まるのに対し、2重木アルゴリズムで出力された近似巡回ルートではインデックスが0から始まっている点に注意してください。
costMatrixのインデックスを交換するように変形してdouble_tree_algorithm()を実行すると、出力する近似巡回ルートが変化します。
Christofidesのアルゴリズムの実行
ChristofidesのアルゴリズムもPythonで実装してみたところ、以下の通りになりました。2重木アルゴリズムと、Christofidesのアルゴリズムで同じステップの処理がありましたので、以前の関数を一部使いまわしています。
def christofides_algorithm(costMatrix: list, start: int):
"""
Christofidesのアルゴリズムで近似巡回ルートを生成する
Parameters
----------
costMatrix : list
完全グラフのコスト行列
start : int
近似巡回ルートのスタート地点
Returns
-------
route : list
近似巡回ルート
"""
# 1. コスト行列から重み付き完全グラフを生成
graph = _create_weighted_graph(costMatrix)
# 2. Primのアルゴリズムで最小全域木を生成
spanningTree = nx.minimum_spanning_tree(graph, algorithm="prim")
# 3. 最小全域木から偶数次数の頂点を除去
removedGraph = _remove_even_degree_vertices(graph, spanningTree)
# 4. 除去された最小全域木から最小コストの完全マッチングによるグラフを生成
matchingGraph = _match_minimal_weight(removedGraph)
# 5. 最小全域木と完全マッチングによるグラフを合体
mergedGraph = _merge_two_graphs(spanningTree, matchingGraph)
# 6. 合体したグラフからオイラー路を生成
eulerianPath = _create_eulerian_path(mergedGraph, start)
# 7. オイラー路からハミルトン閉路を生成
route = _create_hamiltonian_path(eulerianPath)
# 8. ハミルトン閉路を出力して終了
return route
def _remove_even_degree_vertices(graph: nx.Graph, spanningTree: nx.Graph):
"""
全域木から偶数次数の頂点をグラフから取り除いた部分ブラフを生成する
Parameters
----------
graph : networkx.Graph
グラフ
spanningTree : networkx.Graph
全域木
Returns
-------
removedGraph : networkx.Graph
頂点を取り除いた部分グラフ
"""
# 引数のグラフからコピーして初期化し、全域木の偶数次数の頂点を削除
removedGraph = nx.Graph(graph)
for v in spanningTree:
if spanningTree.degree[v] % 2 == 0:
removedGraph.remove_node(v)
return removedGraph
def _match_minimal_weight(graph: nx.Graph):
"""
グラフの最小コストの完全マッチングを生成する
Parameters
----------
graph : networkx.Graph
グラフ
Returns
-------
matchingGraph : set
マッチングを構成する辺(2要素のみ持つタプル)のみ持つグラフ
"""
# グラフの全コストの大小関係を反転させるため、コストの符号を逆にして初期化
tmpGraph = nx.Graph()
for edgeData in graph.edges.data():
tmpGraph.add_edge(edgeData[0], edgeData[1], weight=-edgeData[2]["weight"])
# ブロッサムアルゴリズムで最大重み最大マッチングを生成
matching = nx.max_weight_matching(tmpGraph, maxcardinality=True)
# マッチングを構成するのみ持つグラフの生成
matchingGraph = nx.Graph()
for edge in matching:
matchingGraph.add_edge(edge[0], edge[1], weight=graph[edge[0]][edge[1]]["weight"])
return matchingGraph
def _merge_two_graphs(graph1: nx.Graph, graph2: nx.Graph):
"""
辺が2重化されていない2つのグラフを合体する
Parameters
----------
graph1 : networkx.Graph
1つ目のグラフ
graph2 : networkx.Graph
2つ目のグラフ
Returns
-------
mergedGraph : networkx.MultiGraph
合体したグラフ
"""
# 合体したグラフを1つ目のグラフからコピーして初期化し、2つ目のグラフの各辺を追加
mergedGraph = nx.MultiGraph(graph1)
for edgeData in graph2.edges.data():
mergedGraph.add_edge(edgeData[0], edgeData[1], weight=edgeData[2]["weight"])
return mergedGraph
一番上のchristofides_algorithm()によってChristofidesのアルゴリズムを実行し、その近似巡回ルートを出力します。引数と出力値は、2重木アルゴリズムのdouble_tree_algorithm()と同様です。各ステップごとに実行している関数を順に説明します。
-
2重木アルゴリズムと同様に、
_create_weighted_graph()を実行します。 -
2重木アルゴリズムと同様に、最小全域木を生成する
networkx.minimum_spanning_tree()を実行します。 -
最小全域木の偶数次数の頂点を除去する
_remove_even_degree_vertices()を実行します。networkx.Graphクラスのコンストラクタの引数に自身のインスタンスを指定すると、引数のデータをディープコピーしたインスタンスを生成します。 -
最小重み完全マッチングのグラフを生成する
_match_minimal_weight()を実行します。NetworkXには、重み付けられたグラフのマッチングを求める関数として、networkx.max_weight_matching()のみ用意されていますが、これは最小重み完全マッチングではなく、最大重みのマッチングを求める関数であり、2で出力したグラフを指定すると真逆のマッチングを生成してしまいます。そこで、networkx.max_weight_matching()の実行において、以下を考慮に入れます。-
networkx.max_weight_matching()のmaxcardinality引数をTrueに指定します。これによって、マッチングではなく最大マッチングを生成するようにアルゴリズムが切り替わります。さらに。2のグラフ -
networkx.max_weight_matching()を実行する前処理として、2で出力したグラフのすべての重み(=コスト)について、正負の符号を逆にします。これにより、すべての重みの大小関係が逆になります。符号を逆にした重みの最大重みのマッチングを求めることは、最小重みのマッチングを求めることと同値になるからです。
特に大事な考慮は後者です!最大重みのマッチングを求める関数のみならず、入力データに対して適切に前処理や後処理を入れてから、組合せ最適化問題を解くライブラリの関数実行することはよくあることです。
-
-
1の最小全域木と、3のグラフを合体する
_merge_two_graphs()を実行します。第1引数のグラフでグラフインスタンスを初期化し、第2引数のグラフの辺をそれに追加することで、2つの引数で指定した2つのグラフを合体したグラフインスタンスを出力しています。 -
2重木アルゴリズムと同様に、オイラー路を生成する
_create_eulerian_path()を実行します。 -
2重木アルゴリズムと同様に、ハミルトン閉路を生成する
_create_hamiltonian_path()を実行します。
先程の図の例に従って近似巡回ルートをChristofidesのアルゴリズムによって出力する場合は、christofides_algorithm()を以下のように実行します。
>>> from tsr import christofides_algorithm
>>> costMatrix = [[None, 8, 14, 17, 10, 6, 15],
... [ 8, None, 6, 15, 18, 3, 12],
... [ 14, 6, None, 9, 13, 8, 7],
... [ 17, 15, 9, None, 7, 12, 3],
... [ 10, 18, 13, 7, None, 15, 6],
... [ 6, 3, 8, 12, 15, None, 9],
... [ 15, 12, 7, 3, 6, 9, None]]
>>> route = christofides_algorithm(costMatrix, 0)
>>> print(route)
[0, 4, 6, 3, 2, 1, 5, 0]
これより、頂点1→頂点5→頂点7→頂点4→頂点3→頂点2→頂点6→頂点1の近似巡回ルート(合計コストは43)が生成されました。
これも、costMatrixのインデックスを交換するように変形してchristofides_algorithm()を実行すると、出力する近似巡回ルートが変化します。
近似アルゴリズムの検証
2-近似アルゴリズムである2重木アルゴリズム、1.5-近似アルゴリズムであるChristofidesのアルゴリズムが、果たして近似度の定義を満たしているのかどうか、実際に検証してみましょう。
以下の観点で数値実験してみました。
- スタート地点は頂点0固定だが、最小全域木、オイラー路、マッチングの取り方をランダムに変えるべく、以下の
_shuffle_cost_matrix()を実行して、コスト行列のインデックスをシャッフルする。
# coding: utf-8
from random import sample
def _shuffle_cost_matrix(costMatrix: list):
"""
コスト行列の行と列のインデックスをシャッフルする
Parameters
----------
costMatrix : list
完全グラフのコスト行列
Returns
-------
shuffledCostMatrix : list
シャッフルした完全グラフのコスト行列
shuffledStart : int
シャッフルしたインデックス
"""
# 元のインデックスリストを生成
indices = range(len(costMatrix))
# 元のインデックスリストをシャッフルして生成
shuffledIndices = sample(indices, len(indices))
# シャッフルした完全グラフのコスト行列を初期化し、1行ずつ格納
shuffledCostMatrix = []
for i in indices:
tmpShuffledCostMatrix = []
for j in indices:
tmpShuffledCostMatrix.append(costMatrix[shuffledIndices[i]][shuffledIndices[j]])
shuffledCostMatrix.append(tmpShuffledCostMatrix)
return shuffledCostMatrix, shuffledIndices
- インデックスがシャッフルされたコスト行列を用いるため、スタート地点も頂点0から巻き添えでシャッフルされる。
- インデックスが交換されたコスト行列、スタート地点のもとで、2つのアルゴリズムを実行する動作を1000回繰り返す。
- 以下のアルゴリズムによって出力される近似巡回ルートの合計コストが、合計コストの最小値である42を下回らず、以下の値を上回らないかどうか検証する。
- 2重木アルゴリズム : 84(= 42 * 2)
- Christofidesのアルゴリズム : 63(= 42 * 1.5)
結果、以下のヒストグラムの通りになりました。
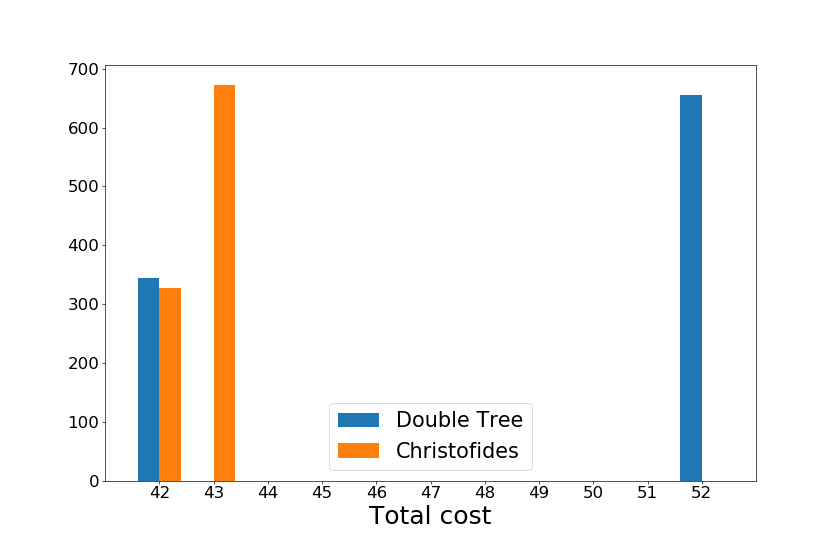
横軸は出力された近似巡回ルートの合計コスト、縦軸は度数です。確かに、2重木アルゴリズム、Christofidesのアルゴリズムともに、近似アルゴリズムとしての定義をみたしていることがわかりますね。
また、2つのアルゴリズムのCPU実行時間を計測してみたところ、Christofidesのアルゴリズムは2重木アルゴリズムより約1.75倍時間がかかっていました。2つのアルゴリズムの内部処理の最大の違いは、Christofidesのアルゴリズムの内部処理で、ブロッサムアルゴリズムによって最大重み最大マッチングを求めているところです。最大重み最大マッチングを求めてより精度を良くできる代償として、CPU実行時間を多く要してしまうトレードオフが発生していることがわかりました。
さわやかの全店舗の近似巡回ルートの実装
ここでは、今までの2つのアルゴリズムを用いて、さわやかの全店舗を巡回するルートを出力し、考察してみます。本コラムでは、このURLのSawayakaクラスを取り扱います。
さわやか各店舗の住所とインデックス
ここまで、さわやかの内容がほとんど出てきておらず、ずっと数学の話をしてきたため、そろそろ本題に戻りましょう。
まず、さわやか各店舗の住所とインデックスを、静的定数Sawayaka._ADDRESSESとして定義します。
# 各店舗の住所
_ADDRESSES = [
"〒412-0026 静岡県御殿場市東田中984−1", # 御殿場インター店
"〒419-0122 静岡県田方郡函南町上沢130−1", # 函南店
"〒411-0942 静岡県駿東郡長泉町中土狩340−5", # 長泉店
"〒410-0042 静岡県沼津市神田町6番26号", # 沼津学園通り店
"〒417-0045 静岡県富士市錦町1丁目11-16", # 富士錦店
"〒419-0202 静岡県富士市久沢847-11", # 富士鷹岡店
"〒420-0913 静岡県静岡市葵区瀬名川2丁目39番37号", # 静岡瀬名川店
"〒420-8508 静岡県静岡市葵区鷹匠一丁目1番1号", # 新静岡セノバ店
"〒422-8005 静岡県静岡市駿河区池田634-1", # 静岡池田店
"〒422-8051 静岡県静岡市駿河区中野新田387-1", # 静岡インター店
"〒425-0035 静岡県焼津市東小川7-17-12", # 焼津店
"〒426-0031 静岡県藤枝市築地520-1", # 藤枝築地店
"〒427-0058 静岡県島田市祇園町8912-2", # 島田店
"〒421-0301 静岡県榛原郡吉田町住吉696-1", # 吉田店
"〒439-0031 静岡県菊川市加茂6088", # 菊川本店
"〒436-0020 静岡県掛川市矢崎町3-15", # 掛川インター店
"〒436-0043 静岡県掛川市大池3001-1", # 掛川本店
"〒437-0064 静岡県袋井市川井70-1", # 袋井本店
"〒438-0071 静岡県磐田市今之浦4丁目4-6", # 磐田本店
"〒438-0834 静岡県磐田市森下1002-3", # 豊田店
"〒435-0042 静岡県浜松市東区篠ケ瀬町1232", # 浜松篠ヶ瀬店
"〒435-0057 静岡県浜松市東区中田町126-1", # 浜松中田店
"〒431-3122 静岡県浜松市東区有玉南町547-1", # 浜松有玉店
"〒434-0041 静岡県浜松市浜北区平口2926-1", # 浜北店
"〒431-1304 静岡県浜松市北区細江町中川5443-1", # 細江本店
"〒433-8125 静岡県浜松市中区和合町193-14", # 浜松和合店
"〒433-8118 静岡県浜松市中区高丘西3丁目46-12", # 浜松高丘店
"〒432-8002 静岡県浜松市中区富塚町439-1", # 浜松富塚店
"〒432-8023 静岡県浜松市中区鴨江3-10-1", # 浜松鴨江店
"〒430-8588 静岡県浜松市中区砂山町320-2", # 浜松遠鉄店
"〒430-0846 静岡県浜松市南区白羽町636-1", # 浜松白羽店
"〒432-8065 静岡県浜松市南区高塚町4888-11", # 浜松高塚店
"〒431-0301 静岡県湖西市新居町中之郷4007-1" # 新居湖西店
]
0番目から順に、東から西へとさわやかの住所を設定しています。この住所の情報は、さわやか2店舗間の移動時間などの取得時に使用します。
さわやか33店舗分の移動時間の取得
2つの近似アルゴリズムを実行するのに必要なコスト行列を取得するべく、(32+31+…+2+1)個のさわやか2店舗間の移動時間をすべて取得する必要があります。さわやか2店舗間の移動時間はGoogle Maps APIを用いて実装できます。さわやか2店舗間の移動時間を実際に取得している箇所は、Sawayakaクラスのコンストラクタにある、以下のgooglemaps.Client.directions()です。
result = client.directions(
origin=Sawayaka._ADDRESSES[i],
destination=Sawayaka._ADDRESSES[j],
mode="driving",
alternatives=False
)
originで指定した出発地から、destinationで指定した到着地まで、車で移動(mode引数に"driving"を指定)するパラメータでDirections APIを実行しています。なお、2店舗間のルートは1つだけ取得できれば十分なので、alternativesはFalseとして指定しています。ただし、このメソッドを実行だけでは、移動時間以外にも2店舗間のルートのうち、曲がり角の緯度・経度といった、様々な情報を取得できてしまうため、それらの中から移動時間だけピンポイントで取得するためには、
result[0]['legs'][0]['duration']['value']
とすれば良いです。移動時間の単位は秒です。この取得処理は、Sawayaka.get_cost_matrix()で行っています。
移動時間以外の情報は後に別の目的で利用するため、Sawayaka._directionsメンバーにresult[0]['legs'][0]まで保持しています。
近似巡回ルートの出力
Sawayaka.get_cost_matrix()で出力したコスト行列とスタート地点の頂点を、前述のdouble_tree_algorithm()、christofides_algorithm()に指定して、近似巡回ルートを取得します。
地図上への近似巡回ルートの図示
ただ近似巡回ルートを求めただけではつまらないので、せっかくなので、foliumで地図上に近似巡回ルートをそれっぽく図示することも考えました。これを実現したのがSawayaka.draw_map()です。
さわやかの33店舗をマーカーを描画し、さわやか2店舗間のルート内における各曲がり角を直線でつなぐ…という実装内容です。また、線の色が一色だと少しわかりにくいので、さわやか2店舗間のルートごとに7色の虹で表現することにしました。しかし残念ながら、曲がり角だけを直線で繋いでいるため、一本道のカーブで曲線が描けず、正確に図示することはできませんでした…
実行結果
2重木アルゴリズム、Christofidesのアルゴリズムを用いて、以下の観点で数値実験してみました。最適巡回ルートが既知であり、近似度の定義の確認だった前回の検証とは違い、今回は性能検証です。
- スタート地点は関東から最も車で行きやすい、0番目の御殿場インター店(=
Sawayaka._ADDRESSES[0])に固定するが、前回の数値実験と同様にコスト行列とスタート地点がシャッフルされる。 - インデックスが交換されたコスト行列、スタート地点のもとで、2つのアルゴリズムを実行する動作を1000回繰り返す。
- 以下のアルゴリズムのどちらが最小合計コストが小さいのか(最も短い時間で巡回できるのか)どうか検証する。
- 2重木アルゴリズム
- Christofidesのアルゴリズム
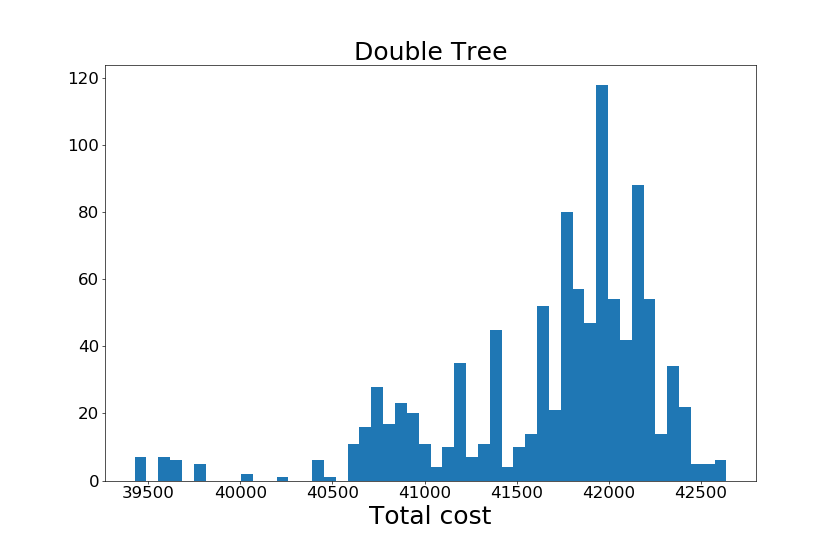
実行結果を前述のヒストグラムとして図示してみましょう。なお、ヒストグラムの表示の都合上、アルゴリズムごとにバラバラにグラフを図示しています。2重木アルゴリズムは以下のヒストグラムの通りになりました。
一方、Christofidesのアルゴリズムは以下のヒストグラムの通りになりました。
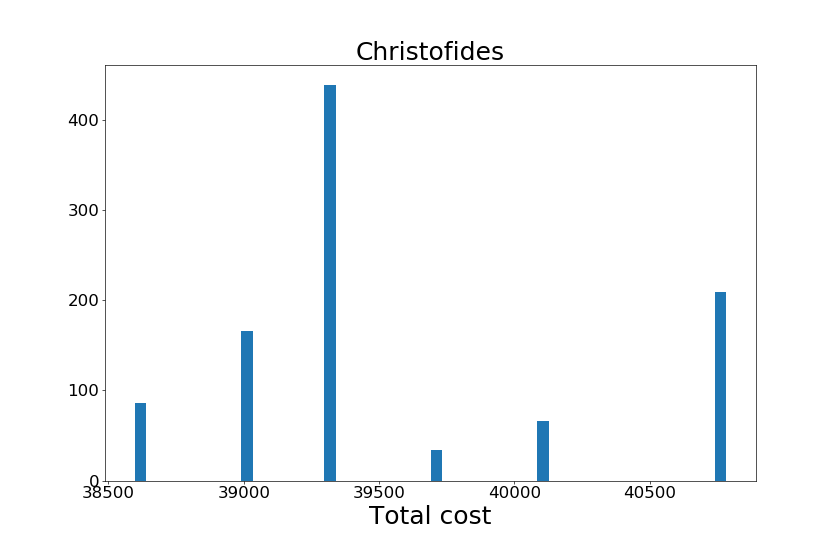
グラフの縦軸と横軸は前回と同様です。これより、以下の点がわかります。
- Christofidesのアルゴリズムの出力した近似巡回ルートの最小合計コストは、2重木アルゴリズムのものよりも小さかった。これより、Christofidesのアルゴリズムの方は最適な巡回ルートに近い近似巡回ルートを出力できる可能性が高い。
- 2重木アルゴリズムは、出力する近似巡回ルートは合計コストがまだらであり、実行の都度合計コストが変わってしまうように見えた。一方、Christofidesのアルゴリズムは、合計コストが6通り(※)しか存在せず、より安定した合計コストを持つ近似巡回ルートを出力してくれるように見えた。
- (※)さわやか浜松遠鉄店がオープンする前の32店舗だったときにChristofidesのアルゴリズムを実行したところ、もっと少なく、4通りしか存在しませんでした。これより、頂点の数によってChristofidesのアルゴリズムの安定性が変化することが判明したため、非常に興味深いです。
- 上記より、Christofidesのアルゴリズムは合計移動時間がより少ない近似巡回ルートを安定して出力してくれていた。しかし、CPU実行時間を計測してみたところ、Christofidesのアルゴリズムは2重木アルゴリズムより約5倍時間がかかっていたため、$|V|$、$|E|$が前回の検証より多くなった今回の数値実験では、前述のトレードオフが顕著に現れることが確認できた。
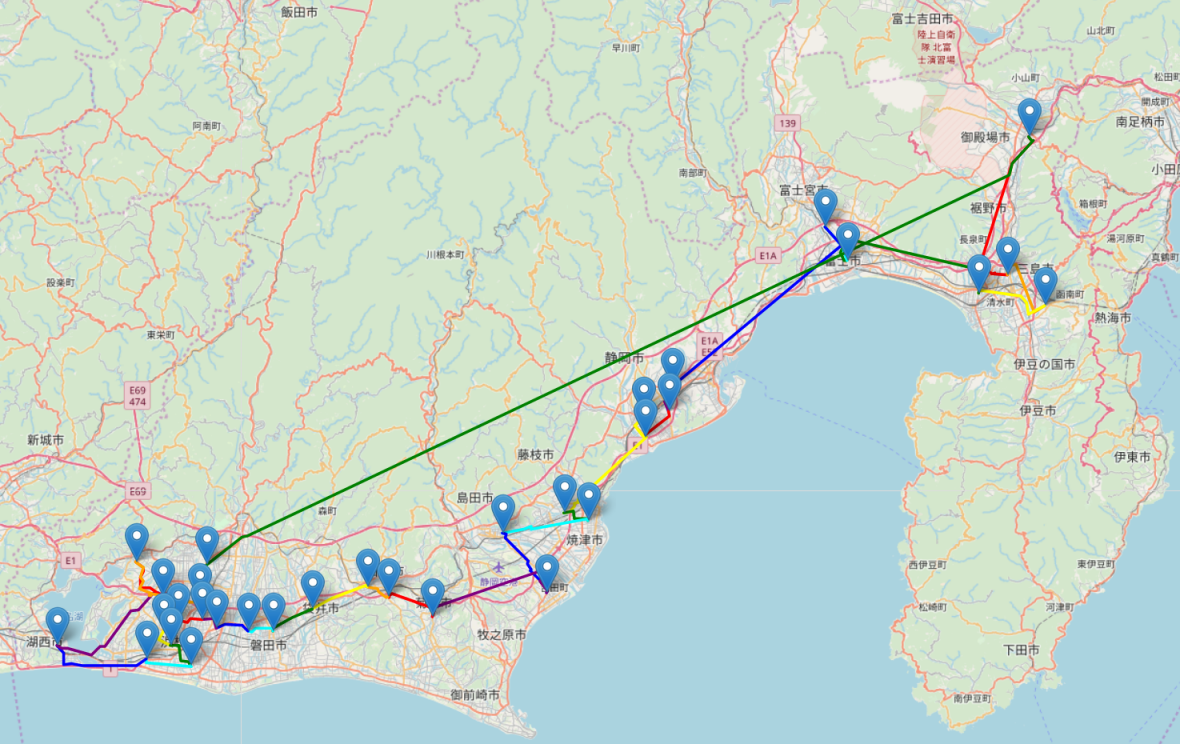
合計コストが最小になるときの近似巡回ルートを地図上で図示してみましょう。まずは2重木アルゴリズムからです。
一方、Christofidesのアルゴリズムは、以下の通りになりました。
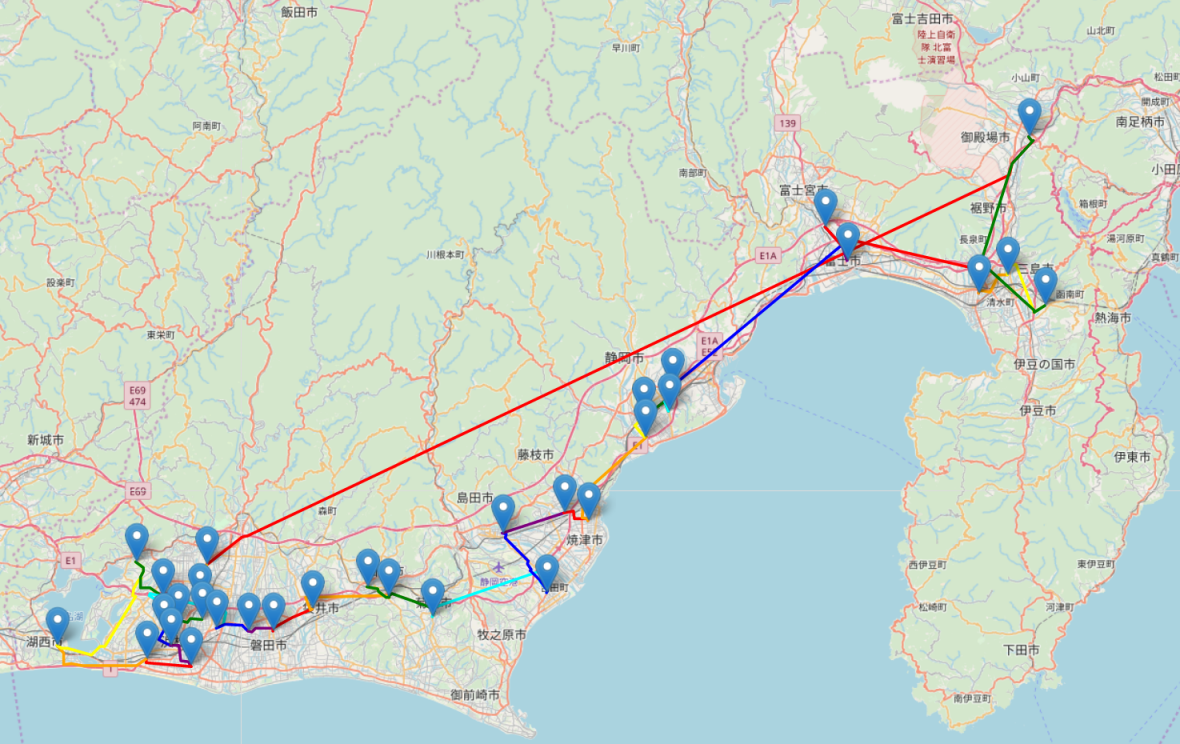
よく見ると、複数店舗が密集している地点でのさわやか2店舗間の細かいルートが少し違うだけで、店舗の密集地点ごとの大まかな移動に関しては、どちらも差異が無いように見えます。両方に共通するポイントは、浜北店から御殿場インター店まで新東名高速道路を利用して移動している点です。これによって距離が遠い2店舗感を一般道でチマチマと移動するより短い移動時間で移動しています。なお、オマケですが合計コストが逆に最大になるときの2重木アルゴリズム近似巡回ルートは以下の通りになりました。
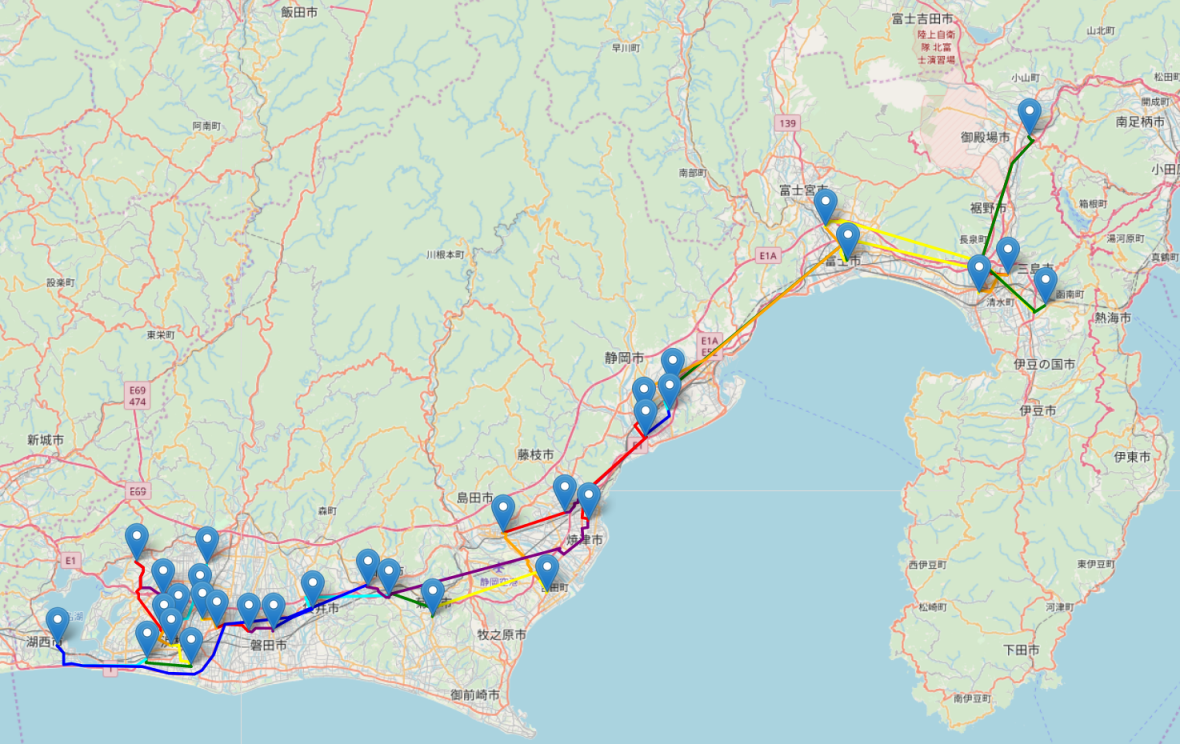
さっきのような、浜北店から御殿場インター店まで新東名高速道路を利用して移動するような、距離の遠い2店舗間を高速道路で移動する箇所が存在していないように見えますね。ほとんど、一般道でチマチマと移動しているように見えるため、合計移動時間(=合計コスト)が大きくなってしまうことがわかります。
おまけ
本記事におけるPythonのスクリプトと検証結果は、GitHubで公開しています。
ここまで記事が執筆できたのも、炭焼きレストランさわやかの看板商品である、げんこつハンバーグのおかげです!げんこつハンバーグ最高!