Image Classsificationの重要論文の一つ。特に、2015年以降は、ResNetをベースとして改良されている論文が多く、重要性が高いと思います。
論文・参考サイトへのリンク
-
論文リンク
-
論文の参考サイト
-
Deep Residual Learning(Microsoft Researchによる解説スライド)
- 正直、この記事よりこのスライドを見た方が良いと思います :)
- ResNet論文を読んだメモ
- Residual Network(ResNet)の理解とチューニングのベストプラクティス
-
Deep Residual Learning(Microsoft Researchによる解説スライド)
-
実装についての参考サイト
以下、Microsoft Researchの事を一般的な略語のMSRAと書きます。また、補足と書いてある部分は、論文には書いておらず、私が補足した点になります。
機械学習を絶賛勉強中なので、訂正、指摘、疑問、質問等あれば、どしどしお願いします。
始めに
-
2015年のImageNetCompetitionで、以下の結果 (MSRAのスライドより)
- ImageNet Detection: 1位 (16% better than 2nd)
- ImageNet Localization: 1位 (27% better than 2nd)
- COCO Detection: 1位 (11% better than 2nd)
- COCO Segmentation: 1位 (12% better than 2nd)
-
大幅なレイヤー数増加とエラー率低減を実現(図はMSRAのスライドP3より引用)

以下、論文の流れに沿って書きます。以下特に明記しない限り、論文からの引用です。
※ 正直、MSRAのスライドの方が分かりやすいです。
Abstract
-
深いニューラルネットワークは訓練することは困難
- この論文では、これまで使用されていたよりもはるかに深いネットワークのトレーニングを容易にするために、Residential Learning Frameworkを提示する。
-
非参照関数を学習するのではなく、層入力を参照してResidual functionを学習するように、レイヤーを再構成する
- 補足:非参照関数(Unreferenced function)が何の事か分からないが、その後の文章の意味としては、そのレイヤで最適な出力を学習のではなく、層の入力を参照する残差関数を学習するようにする。$\mathcal{H}(x)$が学習して欲しい関数だとすると、$\mathcal{H}(x) = \mathcal{F}(x) + x$になるように学習させる。
-

-
この論文では、これらのResidual Networkが最適化しやすく、かなり深い深いレイヤーでも精度を得ることができる、包括的な実験結果を提供する
-
ImageNetデータセットでは、VGGネットより8倍深い152レイヤーの深さの残差ネットを評価するが、依然として複雑さ(パラメーター数)は低い
-
これらの残差ネットは、ImageNetテストセットで3.57%のエラーを達成
- この結果は、ILSVRC 2015分類作業の第1位を獲得
-
我々はまた、100および1000層のCIFAR-10に関する分析を提示する
-
表現の深さは、多くの視覚的認識課題にとって重要である。
- 私たちの非常に深い表現のせいで、私たちはCOCOオブジェクト検出データセットで28%の相対的な改善を得ている
-
ImageNet Detection、ImageNet Localization、COCO Detection、およびCOCO Segmentation の第1位を獲得
1. Introduction
-
深い畳み込みニューラルネットワークは、画像分類のための一連のブレークスルーを導いた。
- 最近の研究で、ネットワークの深さは、クリティカルに重要である事が分かっている
- ResNet以前の、ImageNetの先端的な結果では、「とても深い」モデルでは、16〜30レイヤである
-
そのため「より多くのレイヤーを積み重ねても、簡単にネットワークを学習できるのか」というのが疑問となる
-
この疑問の最初の障害は、悪名高い、勾配消失・勾配爆発である
- 補足:勾配消失についてはこちらが分かりやすい
- この問題自体は、Normalized initialization、Intermediate normalization layers及び、SGD(確率的勾配降下法)である解決が図られている
- 補足:一般的には、Batch normalization、ReLU、Dropoutなども貢献していると言われている。
-
しかし、レイヤー深くすると、それでも degration problem が発生する
- 下のFigure 1 のように、深いネットワークでは、エラー率高い。また、Accuracyが飽和(Training error が台地を迎える)していることが分かる
Figure 1.
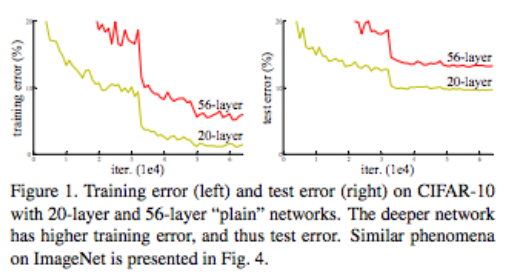
左はトレーニングエラー。右は、テストエラー。
共に、CIFAR-10 のデータを使い、20レイヤーと30レイヤーの plain network(後述)での結果。深いネットワークでは、エラー率高い事が分かる。Fig.4 にImageNetの結果があるが、類似した挙動を示している。
-
この結果は、overfitting によるものではない。
- 補足:結局、勾配消失・勾配爆発が起こっているということ?論文中には書かれていない
-
従来は、"construction"という方法で、解決していた。これは、より浅いModelで学習したものを、深いModelにコピーする方法
- 補足:コピーされず、深いModelで新しくする登場するレイヤーは、"Identity"と呼ばれるらしい。「個性」という意味で使われているような印象。

-
しかし、より深くすると、この方法ではうまくいかない。
-
本論文では、Deep Residual Learning Framework でこれを解決する
-
$\mathcal{H}(x)$が学習して欲しい関数だとする。2レイヤーのPlain なネットワークを考える。
- この2レイヤーは、$\mathcal{H}(x)$ にフィットするように学習される

- 対して、Residual networkでは、$\mathcal{H}(x) = \mathcal{F}(x) + x$に対して学習させる。
- これは、2レイヤは、$\mathcal{F}(x) = \mathcal{H}(x) - x$ に学習させることになる。これがResidual 残差の意味
- つまり、x (identity)が、最適の場合、weight は 0 になる
- これにより、x と $\mathcal{H}(x)$が近い場合でも、微少な差$\mathcal{F}(x)$を学習しやすくなる
- Fig.2 の $\mathcal{F}(x) + x$は、"shortcut connection"付きのfeedforward neural network
- これは、パラメータは増えないないし、計算も複雑では無い
2. Related work
すいません、飛ばします。MSRAのスライドのP19に簡単に解説があります
3. Deep Residual Learning
3.1. Residual Learning
先ほどの説明と同じ
3.2. Identity Mapping by Shortcuts
- Fig. 2. の2つのレイヤのブロックを、この論文では、式1:$y = \mathcal{F}(x, \{W_i\}) + x$ と定義する
- x が入力で、yが出力
- $\mathcal{F}(x, \{W_i\})$ が学習されるべき関数を示している
- Fig. 2 は2レイヤーなので、$\mathcal{F} = W_2\sigma(W_1x)$となる
- $\sigma$は、ReLUを示す
- Fig. 2 は2レイヤーなので、$\mathcal{F} = W_2\sigma(W_1x)$となる
- ReLUが、$\mathcal{F} + x$の後にある
- 補足:なぜか式1には書いて無いが。。
- 式1において、$x$と$\mathcal{F}$の次元が同じである必要が有る
3.3. Network Architectures
Figure 3.

ImageNet用のネットワークアーキテクチャの例。左:VGG-19のモデル。計算量は19.6 GFlops (参考、中央:34レイヤーのResidual networkなしのPlainなネットワーク。計算量は3.6 GFlops、右:Residual network付きの34レイヤ。計算量は、3.6GFlops
点線は、Dimentonが増えていて、式2を使う必要が有る事を示す。
詳細は、Table 1 を参照。
- できるだけシンプルにしている
- VGG16にインスパイヤされたネットワーク
- できるだけ、3x3 の Convolutional network になっている
- その他の特徴。主にVGG16との違い。以下全てVGG16にはあった。(MSRAのスライドより)
- max pooling が無い
- hidden fc が無い
- dropoutが無い
Table 1.

Imagenet向けのアーキテクチャ。 Bulidng blockは、Fig.5 で示されるもの。
- 補足: [3x3, 64; 3x3, 64] 等は Fig.2 で示されたものと同じ。もう一つの [1x1, 64; 3x3, 64; 1x1, 256]等は、"bottleneck"というもの。Fig.3 は、このTable 1の 34 layers に対応している。例えば、Fig.3 のpool,/2 の後の6つのレイヤー(3つのBulidng block)が、[3x3, 64; 3x3, 64] $\times 3$ に対応している。
3.4 Implementation
特別なところは無いです。
- Data augmentation は、以下の通り
- [256, 480] の範囲で、Scale augmentation
- 224x224 にランダムCrop
- ランダム横方向反転
- Per-pixel Mean Subtraction(チャンネル毎の平均値を引く)
- Batch normalizationを全てのConvolution networkの直後、ReLUの直前に入れる
- pretraining は無く、Scratchから学習
- dropoutは使わない
- ハイパーパラメータ
- SDG mini-batch size: 256
- learning rate 0.1 からスタート。error 率の低下が台地を迎えたら、10 で割る
- $60 \times 10^4$ イテレーションまでトレーニング
- weight decay : 0.0001
- momentum: 0.9
- ハイパーパラメータ
4. Experiments
4.1. ImageNet Classification
Figure 4.

ImageNet での結果。 細い線は、Training Error。太い線は、Validation error(Cropは中央に固定)。
左: Plaing network
右: ResNet
このグラフでは、ResNetとPlainネットワークで、Parameter数は同じ。にもかかわらず、Error率が下がっていることが分かる。
Table 2.

- Fig.4 を見ると、重要な点として、Plain-34はPlai-18よりも悪い。これは、degration problem が起こっている事を示している。が、ResNet-34は、ResNet-18よりも良く、degration problemを回避できていることが分かる。
- Table 2を見ると、top-1エラーが、ResNetとPlainネットワークで比べると、3.5%良化している。これにより、Residual learningが深いネットワークで有効なことが示せた
- Table 2を見ると、18レイヤは、ResNetとPlainネットワークでそんなに変わらない。が、収束が速いことが、Fig. 4で分かる。SGDは、18レイヤーの浅いネットワークぐらいでは、良い答えを導ける。その場合でも、ResNetの方が収束が速いことが分かる。
- 補足:水色の18-レイヤの線を比べる。中央の台地を見た時、右のほうが低い
Iedntity vs. Projection Shortcuts.
- 式2を使うの手法を評価
Table 3.

Image Net でValidationした結果。10-crop testing をしている(補足:10-crop testing については末尾参照)
ResNet-50/101/152 は、Bを使った結果
- A > B > C でCが一番良いが、大きく違わない
- 今後の評価では、Cを使わない(明示しない限り、基本的にBを使う)
Deeper Bottleneck Architectures.
- ImageNet向けの、より深いモデルに"bottleneck" building block を導入する
Figure 5.

左: Fig. 3 でResNet-34に使われていた bulidng block
右:ResNet-50/101/152 に使う "bottleneck" bulidng block
- Figure 5 の左右のComplexityは似通っている
- 同じような計算量でレイヤを増やせるので、深いレイヤで有用
- 50レイヤResNet(ResNet-50)
- ResNet-34を、bottleneck blockに置き換えたもの。Option BのProject shortcutsを使う
- 101レイヤ、152レイヤ(ResNet-101、ResNet-152)
- レイヤは大幅に増えたが、それでも、VGG-16/19より計算量が少ない
- VGG-16 15.3 GFlops
- VGG-19 19.6 GFlops
- レイヤは大幅に増えたが、それでも、VGG-16/19より計算量が少ない
- Table 3 および、Table 4 を見ると、Depthを増やす毎に、Errorが減っており、degression problemは発生していないことが分かる

Table 4.

ImageNet validation setの single-model での、Error rates。(補足1:Table 3と結果が違うのは、10-crop testing をしているかどうかの差だと思う)(補足2:single-modelについては本ページ末尾参照)
Table 5.

Ensembles(補足:本ページ末尾参照)をしたときのError rates。これは、ImageNetのコンペで使われるテストサーバーから提供されたtest setと、Error rate の値。
- Table 4
- ResNet-34 でも他手法と比べて、十分、優位である
- ResNet-152 は、top-5 validation error で、4.49 である
- Table 5
- 異なる深さの6モデルをEnsembles をしている
- top-5 error が、3.57% で1位を獲得した

4.2 CIFAR-10 and Analysis
- CIFAR-10 を使って、さらに深いネットワークでの挙動を検証する
Table 6.

CIFAR-10のClasasification error。全ての手法は、data augumentationをしている。ResNet-110だけ、5回実行し、分散を計測している。
Figure 6.

CIFAR-10の結果。破線は、training error、太線はtesting error
左: Plain networks。Plain-110のError rateはとても60%以上で表示されていない
中央: ResNet
右: ResNet-110とResNet-1202。(補足:3未満のIterationは省略されている)
- ResNet-110 は、一番良い結果になっている。収束も早い
- かつ、他の深いレイヤーの手法よりも、パラメータ数が少ない(FitNetやHighwayに比べ)
- 1000以上のレイヤの場合
- ResNet-1202の結果もそれほど悪くない
- しかし、ResNet-110より結果が悪く、これほど深いモデルには、以前問題があることが分かる
- これは、Overfittingだと思われる。強い正規化を行う事で、改善する可能性があるが、これは将来の課題である
- また、ResNet-1202は、不必要にパラメータ数が多い
Figure 7.

CIFAR-10を学習させたときの、レイヤー毎の標準偏差。(横軸が標準偏差)
それぞれの 3x3 layerで、Batch normalizationの後、ReLU/加算の前の偏差を表している。
上:レイヤーは、そのままの順番
下:レイヤーを、偏差の高い順に並べている
- これは、他手法に比べて、偏差が0に近いことを示している。(これは、Residual functionの元々のモチベーションである)
- また、ネットワークが深いほど、偏差が少ない
4.3 Object Detection on PASCAL and MS COCO
Table 7.

PASCAL VOC2007/2012 test set の Object detction mAP(%)の結果。Apeendix のTable 10、11も参照。
Table 8.

COCO validation set の Object detection mAP(%)の結果。Appendix の Table 9も参照
- 他のタスクにも有効である事を示す
補足
- top-5 error: Predictionの結果で、Accuracyがトップ5のクラスの中に正解が含まれていない確率。ImageNetの評価でよく使われる。なぜ、top-5 を見る必要があるかというと、画像の中に複数のオブジェクトが含まれている場合に、そのどれが、正解のクラスか分からない為。例えば、男性がドラムを叩いている場合、正解クラスが、男性なのか、ドラムなのか、不明。
- 10-crop testing: テスト画像1つから、data augumentation のような手法で10個の画像を切り出し、それに対する予測結果を平均して答えを出す。1-crop testing に比べて、エラー率が減少する 参考
- Ensembles: ネットワーク構造の違う複数のモデル、あるいはネットワーク構造は同じだが入力の異なる複数モデルを使って、出した結果を平均して結果をだす
- single-model/single-model result: Ensembleではなく、一つのモデルだけの結果。多くの場合、一番良い結果のでたモデルを用いる。