概要
Elasticsearch の char_filter のひとつ,icu_normalizer の使い方メモです.
オプションの設定方法がよく分からなかったので調べてみました.
icu plugin は char_filter 以外にもいろいろ利用可能ですが,ここで扱うのは char_filter だけです.
こんなかんじ
icu_normalizer を使うと,「㌶」→「ヘクタール」など,いい感じに変換してくれます.
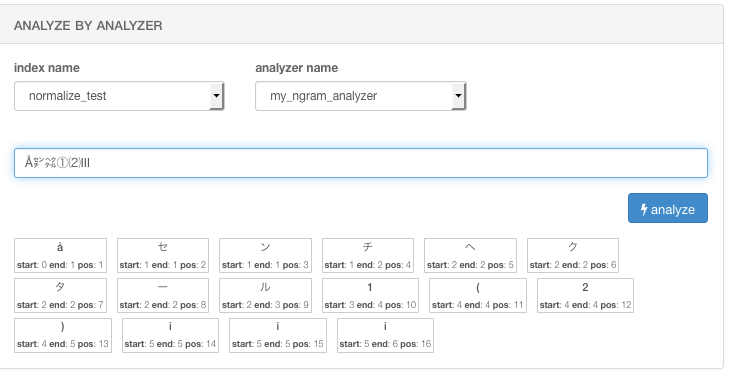
※ 下の画面は,「Å」→「å 」「㌢」→「セ」「ン」「チ」,「①」→「1」,「⑵」→「(」「2」「)」,「Ⅲ」→「i」「i」「i」となっている例です.
インストール
github: https://github.com/elasticsearch/elasticsearch-analysis-icu
バージョンごとにブランチが切られているので,それぞれのブランチの README.md を読んでください.
Elasticsearch のバージョンにあわせてプラグインのバージョンを選んでインストールします.
下記は es が1.3の場合,
% bin/plugin -install elasticsearch/elasticsearch-analysis-icu/2.3.0
オプションの設定方法
設定方法はこちら:icu analysis plugin
ドキュメントによると,name と mode が設定できると書いてあります.
| オプション名 | とりうる値 |
|---|---|
name |
nfc, nfkc, nfkc_cf
|
mode |
compose, decompose
|
{
"index" : {
"analysis" : {
"analyzer" : {
"normalize" : {
"tokenizer" : "standard",
"filter" : "my_icu_normalizer"
}
},
"filter" : {
"my_icu_normalizer" : {
"type" : "icu_normalizer",
"name" : "nfkc_cf",
"mode" : "compose"
}
}
}
}
}
デフォルトのオプション
説明には書いてない(?)みたいだったので,コードを追ってみました.
public IcuNormalizerCharFilterFactory(Index index, @IndexSettings Settings indexSettings, @Assisted String name, @Assisted Settings settings) {
super(index, indexSettings, name);
this.name = settings.get("name", "nfkc_cf");
String mode = settings.get("mode");
if (!"compose".equals(mode) && !"decompose".equals(mode)) {
mode = "compose";
}
this.normalizer = Normalizer2.getInstance(
null, this.name, "compose".equals(mode) ? Normalizer2.Mode.COMPOSE : Normalizer2.Mode.DECOMPOSE);
}
| name | mode |
|---|---|
nfkc_cf |
compose |
がデフォルトのようです.
設定による動作の違い
なんで2つのオプションの組み合わせなの?
Unicode の設定といえば NFC, NFD, NFKC, NFKD と思っていました.ちなみに,おおざっぱな意味は大体下記のような感じです.(いろいろ話が細かいので,詳細は文献をあたるなどしてください![]() ).
).
| 正規化の種類 | 意味 | 例 |
|---|---|---|
| NFC | 正規分解して合成 | 「か」+「゛」→「が」 |
| NFD | 正規分解して分解 | 「が」→「か」+「゛」 |
| NFKC | 互換分解して合成 | NFCと大体同じ.ただし,「㌢」→「センチ」のように展開 |
| NFKD | 互換分解して分解 | NFDと大体同じ.ただし,「㌢」→「センチ」のように展開 |
正規分解と互換分解は正規化用のルールが違うことを意味しています.「①」→「1」のように正規化されるのは互換分解の方です.合成か分解かは,「が」のように「か」と「゛」のサロゲートペアでも表せる文字をどちらで表現するかを合わせてくれます.
というのが,大体の理解でしたが,nfcはあるけど,nfdがないのはナンデ?
答えはICUのAPI(Normalizer2#getInstance(InputStream, String,Normalizer2.Mode))見たら分かりました.こう書いてあります.
Returns a Normalizer2 instance which uses the specified data file (an ICU data file if data=null, or else custom binary data) and which composes or decomposes text according to the specified mode. Returns an unmodifiable singleton instance.
* Use data=null for data files that are part of ICU's own data.
* Use name="nfc" and COMPOSE/DECOMPOSE for Unicode standard NFC/NFD.
* Use name="nfkc" and COMPOSE/DECOMPOSE for Unicode standard NFKC/NFKD.
* Use name="nfkc_cf" and COMPOSE for Unicode standard NFKC_CF=NFKC_Casefold.
ようするに,name と mode の組み合わせで,NFC, NFD, NFKC, NFKD を表現するという事みたいです.
| name | mode | 正規化方法 |
|---|---|---|
nfc |
compose |
NFC |
nfc |
decompose |
NFD |
nfkc |
compose |
NFKC |
nfkc |
decompose |
NFKD |
nfkc_cf とは何か
nfkc_cf は NFKC の大文字小文字統制もやってくれる版です.たとえば,「Å」なら「å 」にしてくれます.逆に言うと,nfkc では大文字小文字の統制はしない.
結論
オプションはデフォルトで使っておけば問題なさそうです! やり過ぎ感がある場合は NFC ぐらいにするのがいいのかもしれませんね.いろいろ調べてはみましたが,インデックス張るのに decompose しなきゃいけないシチュエーションも思いつかないので,確かに nfc, nfck, nfck_cf だけあればいい気がします.