WSDMという検索/データマイニングに関するカンファレンスがあります。
ここでは2015年のWSDMで発表された論文のうち、Back to the Past: Supporting Interpretations of Forgotten Stories by Time-aware Re-Contextualization
(タイトル長っ)について解説を行います。
読み物として読めるように、なるべく数式は割愛しています(数式読めるような人は原文読めると思うので)。実際に実装してみたい、という方は本論文を参照してみてください。
概要
この研究では、ニュースや広告等のテキストメディアに、時代背景を考慮した解説をつけることを試みています。
例えば以下の広告ですが・・・(昭和のトーヨーのラジオの広告です)

「ラジオは目できこう!」???と思いますが、このころのラジオは自動で周波数をチューニングしてくれず、自分でダイヤルを回して探す必要がありました。で、このラジオは周波数が合うと光って知らせてくれる・・・というわけです。
このように、昔のニュースや広告等は、当時の時代背景を意識した解説がないと理解が深まらないものが多々あります。上記の例では、単なるラジオではなく「昭和の時代の」ラジオについてでなくては理解しにくい、ということです。
この論文では、このように「時代背景を意識した」解説をつけるのに取り組んでいます。端的には以下のステップで解説を付けます。
- 解説抽出クエリの作成
ドキュメントの中から解説の対象になりうる語を抽出し(上記の広告でいえば「ラジオ」など)、それを基に解説を検索するためのクエリを作成します - クエリ結果の順位づけ
1で作成したクエリの検索結果を、本文と内容的、そして時系列的に関連する順に並び替え、最も関連が高いものを解説とします
元データとして、解説を付ける文章にはNewYork Times Archive、解説データとしてはWikipediaを利用しており、実際に実装や拡張をしてみることも比較的容易になっています。
課題設定
概要の項でも述べましたが、本研究の課題設定を改めてみておきます。
まず、文書に対する良い解説とは以下のようなものであるとしています。
- 本文に関連している
- 本文を補完する内容である(本文にはない情報を付加している)
- 時代背景が考慮されている
- 読むのに負担にならない
これに対し、従来の単純にWikipediaの内容を表示するような解説は以下のような問題があるとしています。
- 本文が書かれた背景を理解するのに役立たない
- 読む量が多い
- 本文の文脈に沿わない
以下は同じWikipediaの「ラジオ」についてのページから解説を付けたものですが、どの部分を使用するかで解説の有用度がかなり変わることがわかると思います。

本研究の目的は、良い解説と現状のギャップを埋めることにあります。そのためにどのようなアプローチを取ったのかについて、以下で解説していきます。
アプローチ
課題解決の手法として、本研究では以下のようなプロセスを提案しています。
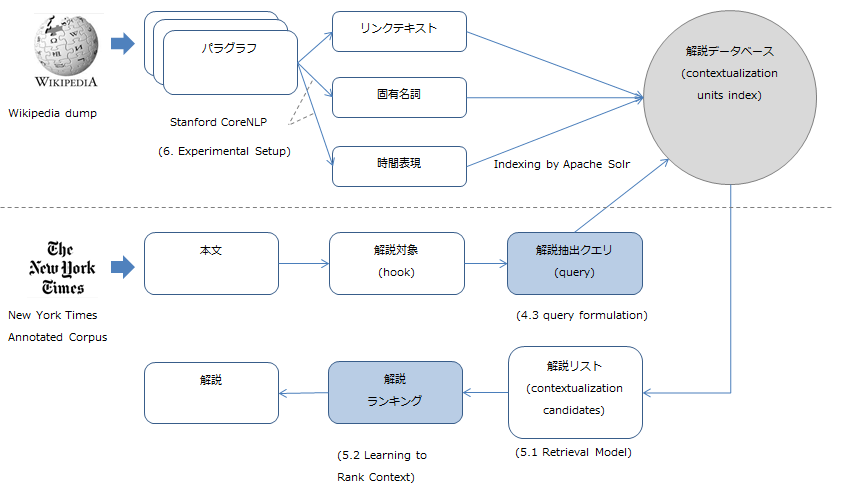
- 上段: 解説を行うためのコンテンツを用意するプロセス
- 下段: 本文と解説を結びつけるためのプロセス
- 解説抽出クエリの作成
- クエリ結果の順位づけ
図中で青色に塗っている箇所は機械学習を使用している箇所で、ここで先行研究より高精度なモデルを構築できた、という点が本研究の優位性となっています。
以下では、本研究のメインとなっている下段の2つのプロセス(解説抽出クエリの作成・クエリ結果の順位づけ)について解説していきます。
解説抽出クエリの作成
ここでは、本文に対する良い解説を抽出するためのクエリ(検索キーワード)を取得するのが目的です(論文中ではquery formulationと呼ばれています)。全体図としては以下のようになります。
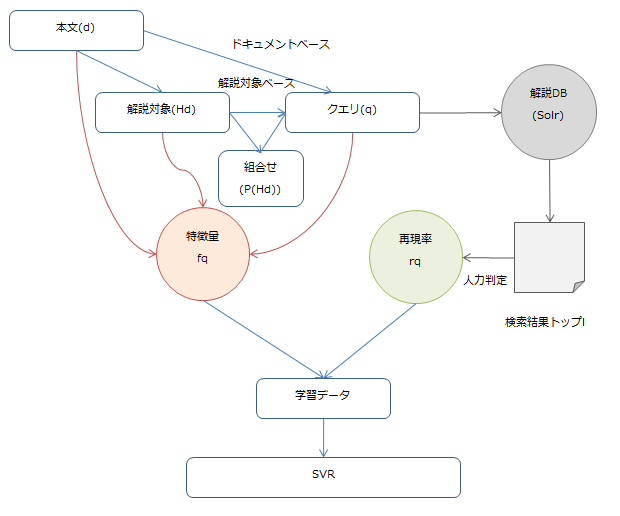
クエリを作成する基本的な手法としては、以下2つのアプローチを提案しています。
- ドキュメントベース: 本文のタイトル、冒頭部分、またその組み合わせから単語の抽出を行う
- 解説対象ベース: 手動で取り付けた解説対象(
hook)を使う(※)。全て使う(all_hook)のと、特定の情報ごとに分けたもの?(each_hook)の2種類で検証
※文章から解説をつけるべき対象を抜くのは人力で行ったようで(3. APPROACH OVERVIEW参照)、ここでは特に特別な手法は使われていません。自動でないのか、という気もしますが、解説対象はanchorリンクからとってもいいし、あるいは「わからないところをマーカーすると解説が表示される」というシステムにするという手もあると思うので、ここはまあよしとします。
この解説対象ベースを一歩進めたものがメインの手法になります。
ざっくり言うと、解説対象の組み合わせでクエリを作成するところまでは同じなのですが、クエリの精度を予測するモデルを作り、予測精度の高い順に採用するという手法です。
そんなモデルが作れるのか、という気がしますが、以下でそのモデルに使用する特徴量、そして予測すべき検索結果の再現率について詳しく見ていきます。
特徴量
クエリ$q$の特徴量としては、以下の項目が使われています。
クエリを構成する単語に関する特徴量だけでなく、母体となる本文/解説対象についての特徴量も加味しています(結果的にはこれが結構重要な要素だった)。
- 言語的特徴量
長さ、名詞、動詞、固有名詞、解説対象、重複文言の数などの特性を、本文とクエリ、双方について算出したもの - 解説対象の出現頻度
全体のコーパス(今回の場合、解説データベース)のうち解説対象が含まれているコーパスの割合、つまり解説対象としてマークされた語が現れる頻度を算出します。解説対象は一文書につき複数存在するため、各解説対象の出現頻度の統計量(最大値、最小値、平均etc)を使用します - 時系列で制限した解説対象の出現頻度
単語の出現頻度は時間によって変わってくるはずなので、それを考慮できるようにします。母数としてコーパス全体でなく、本文と関連する時系列上のものに限定します。アプローチの図にある通りWikipediaの各パラグラフからは時間を表す表現を抽出しており、これにより何かしらの年代に属するようになっています。本文からは作成年代がわかるため、作成年代のプラスマイナス$w$年に収まる範囲のものを母数にします(この$w$としては、本研究では2年が使用されています) - クエリの出現頻度
クエリ$q$を構成する単語が含まれる割合。タイトル、解説対象、コーパス全体、それぞれについての割合を算出します - 時系列で制限したクエリの出現頻度
上記の時系列を考慮した出現頻度と同様、本文のプラスマイナス2年の範囲における割合を算出します。 - クエリと解説の関連度
後のCONTEXT RANKINGでクエリと解説の関連度を算出するモデルを説明しますが、それを利用し関連度の高い解説トップ100の統計値を特徴量として使用します。 - 時系列の関連度
上記の関連度と同様、関連度の高いトップ100との間の時系列の類似度です。関連度は$TSU(t_1,t_2)=\alpha^{\lambda \frac{|t1-t2|}{\mu}}$($0 < \alpha < 1$, $\lambda > 0$, $\mu$ は時間の単位)で表現します。$t_1$には本文の作成年代、$t_2$には解説の推定年代が入り、これで類似度を算出します。
関連度は若干反則気味な気もしますが、何はともあれこれらをモデルの特徴量として使用します。
予測値(再現率)
クエリ$q$の性能を、本研究では再現率で評価しています。
アプローチの項にある図の通り、本研究ではWikipediaから取得したデータをApache Solrに入れています。このSolrにクエリ$q$、要は検索キーワードを投げると検索結果が出力されます。そのトップ$l$を使用して再現率を算出します($l$は検索結果のうち何件を使用するかで、この値をどうするかについては後述します)。
検索における適合率/再現率についてはこちらに詳しく書かれていますが、通常検索精度の評価には適合率が使われるのが一般的です。
適合率が高い場合は「ヒット数は少ないかもしれないが、なるべく厳選されている」状態で、これは検索結果がほぼ1~2ページ目しか見られないことを考えると妥当な指標です。
今回再現率に注目しているのは、この後に得られた検索結果の再評価を行うCONTEXT RANKINGのステップがあるので、精度よりはなるべく取りもらしがないようにすることに重点を置いているためです(再現率が高い場合は、「検索結果のヒット漏れは少ないが、あまり厳選されていない」状態になります)。
この計算に当たっては、当然得られた検索結果が元の本文と関連するものであるかを判定する必要があります。
本研究では幅広い分野・年代から51の記事をピックアップし、それとどの解説(具体的にはWikipediaのパラグラフ)が合うかあらかじめ人力でひもつけておいたそうです。最終的には9,464の記事/解説のペアを作成しています(6人がかりで)。
このデータから、検索結果が元の本文と関係があるのかどうかわかるので、再現率を計算することができます。
モデル
特徴量・予測値がそろったため、モデルの学習を行います。
今回は再現率という連続値を予測するモデルになるため、RegressionのモデルであるSVR(Support Vector Regression)を使用します。実装はLibSVMを使用し、n-SVR/Gaussian Kernelで10-foldのcross validationで学習させます。
このモデルを使用して各クエリ$q$の予測精度を算出し、精度の高いトップ$m$個を使用して解説の抽出を行います。
クエリ結果の順位づけ
ここでは、クエリ$q$を使用して取得した解説の評価を行います。
クエリは前述の通り精度の高いトップ$m$個が使用されるので、まず各クエリで得られた結果を関連度の高い順に統合します。その後に、さらに内容・時間的に関連のあるものを順位づけして選択します。
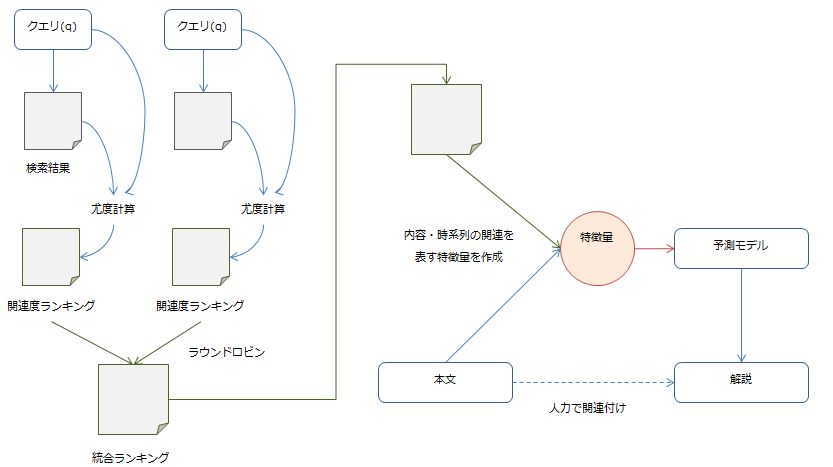
クエリ結果の統合
クエリ$q$を使用した時に解説$c$が得られる確率(尤度)を計算します。これが関連度の基準となります。
クエリで得られた結果に対しこの計算を行うことで、得られた結果を関連度の高い順に順位付けすることができます。クエリは全部で$m$個を使っているので、$m$個の順位づけられたリストが得られます。
各順位表の上位から順に解説をピックアップしていくことで、統合した順位表を作成します(ラウンドロビン方式)。
これでクエリで得られた結果を、一つの順位表に統合することができました。
解説の順位づけ
この順位表に、さらに内容、そして本研究の肝である時系列の関連を加味していきます。
こちらでも先程の手動で本文と解説を紐つけた教師データを使用し、機械学習を行います。特徴量には本文と解説の間の関係を表す以下のものを使用し、これで解説を予測するモデルを構築します。
- トピックの距離: トピックモデルとして代表的なLDAを使用し、本文と解説の間のトピックの距離を算出します(トピック数は100を使用)
- 単語の新規性: 本文にない内容が解説に含まれるかの指標として、本文にない単語が解説に出現する確率を算出し、これを使用します
- 固有名詞の新規性: 単語の新規性と同様のことを、固有名詞で行います
- リンクテキストの新規性: 単語の新規性と同様のことを、リンクテキストで行います
- 単語の確率分布の類似性: 最尤法を使用し本文/解説の単語の確率分布を推定し、その差を使用します
- 単語間の距離: 本文/解説に現れる単語間の距離をCosine距離で計算します
- 関連度: 「クエリ結果の統合」で述べた尤度値を使用します
- 時系列の距離: 前項で述べた「時系列の関連度」を使用します
モデルとしては、Random forests・RankBoost・AdaRankの3つを候補とし、最も精度が高いものを使用します(実装にはRankLibを使用)。また、トピックモデルの構築に際してはトピックの数を100とし、実装としてはMalletを使用しています。
そして、学習は5-fold cross validationで行っています。
結果
解説抽出クエリの作成については、機械学習を使用したものが一番精度が良かった、となっています。最も効いていた特徴量は以下のようです。
- 言語的特徴量: 本文中にある解説対象の数
- 解説対象の出現頻度: 本文中に現れる解説対象の頻度の最小値
- 時系列で制限した解説対象の出現頻度: 本文中に現れる解説対象の頻度の最大値
- クエリの出現頻度: 本文中に現れるクエリの頻度
- 時系列で制限した出現頻度: 時系列で制限したタイトルの頻度
- クエリと解説の関連度: 関連度の最大値/関連度の標準偏差
- 時系列の関連度: 時系列の関連度の平均
そして、検索に使うクエリの数($m$)は2つが良いようです。
クエリ結果の順位づけについては、モデルの候補3つの中でRandom forestsが一番精度が高かったそうです。
今後の展開
今回の研究で、内容及び時間軸を考慮した解説の付与が可能になりました。今後は解説を個人ごとにカスタマイズしていくことについても研究していく予定だそうです。
感想
誰かに情報を届ける、という機能を考える時、重要な点は2つあると思います。
- 適切さ: 相手にとって適切な情報を届けているか
- わかりやすさ: 届けた情報は相手にとってわかりやすいか
届ける情報の適切さ(要はレコメンド)についてはいろいろなアプリで実装されていますが、わかりやすさに着目した機能はまだあまりないのではないかと思います。
要約機能などはちらほらと見かけますが、単に概要をつかむだけでなく「情報についてより深く理解したい」というニーズもまたあると思うので、そういう意味では新しい付加価値につなげられそうな内容だなと感じました。
海外の小説を読んだりするときはその国の流行言葉とかも出てきたりするので(映画の名台詞のもじりとか)、読書をサポートする機能としても面白いと思います。
・・・なんだかさらっとまとめたように見えなくもないかもしれませんが、読むだけでもやっとこさの英語論文のさらに解説を書くというのは思いのほか大変で、途中集中力をなくし無為にWebサーフィンしてしまった時間も含めると結構な時間を費やしてしまいました。この辺はもっと読解力を上げていきたいところです。