「あなたって、私の言葉の最後の方しか聞いてないのね」
実は人間だけでなくニューラルネットワークもそうだった、という結果を示しているのがこちらの論文です。
Frustratingly Short Attention Spans in Neural Language Modeling
言い訳としては「だって君の次の言葉を予測するだけならそれで十分だから」ということになるんですが、そう言うと角が立つのは人間関係においても研究においても同様のようです。
本編は、上記の論文の紹介と共に他の関連論文も交えながら、実際の所本当に最後の方しか必要ないのか、そうであればなぜそんなことになるのか、という所について見て行ければと思います。
なお、参照した論文は以下のGitHubで管理しています。日々更新されているため、研究動向が気になる方は是非Star&Watchをして頂ければと!。

Attentionとは
Attentionとは、連続したデータを扱う際に過去の重要なポイントに着目する(=Attention)ための手法です。イメージ的には質問に回答するときに、相手の質問の中の特定キーワードに注目するといった形です。この例に代表されるように、自然言語処理において広く使用されている手法になります。
以下の図は、次の隠れ層$h^*$(赤色のボックス)を予測する際に、過去5つの隠れ層($h_2-h_6$)を参照するというのを表している図です。過去の各隠れ層からの矢印に書かれている$a_1-a_5$が「Attention」になり、過去のどの点を重要視するのかという「重み」になります。
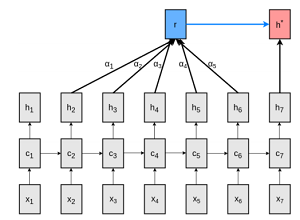
From Figure 1: Memory-augmented neural language modelling architectures.
論文における提案: 隠れ層の役割を分担しよう
さて、このAttentionの登場によりRNNにおける隠れ層が担う役割が多くなりました。
元々の「次の単語を予測する」という役割はもちろん、Attentionに役立つ、つまり「将来の予測に役立つ情報」という役割も果たす必要があります。さらにAttention自体も隠れ層から計算されるため、「将来注目すべき情報かどうか」という情報も持っておかなければなりません。
つまり、Attentionを導入したRNNにおいて隠れ層が担っている役割は以下の3つになります。
- 次の単語の予測のための情報の格納
- 将来注目すべき情報かどうかの情報の格納(Attentionの計算)
- 将来の予測に役立つ情報の格納
まさにニューラルネットワーク内におけるワンオペともいえる状況。これはちょっと仕事の分担をしてあげたほうがいいんじゃない?というのが本論文が提案しているところです。
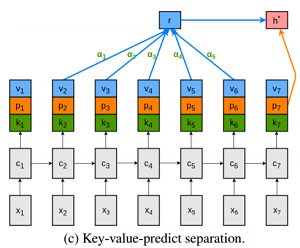
オレンジが(p)1、緑(k)が2、青(v)が3の役割をそれぞれ担っています。これらは単純にベクトルの結合になっており、元が100次元だった場合x3の300次元として実装しています。
これをWikipediaのコーパスとChildren’s Book Testという児童書のコーパスで検証したところ、概ね既存のモデルを上回る効果を出せた、と言うのが結果になるんですが、その検証中に明らかになったもう一つの事実がありました。
Attentionは直近の場所しか見ていない?
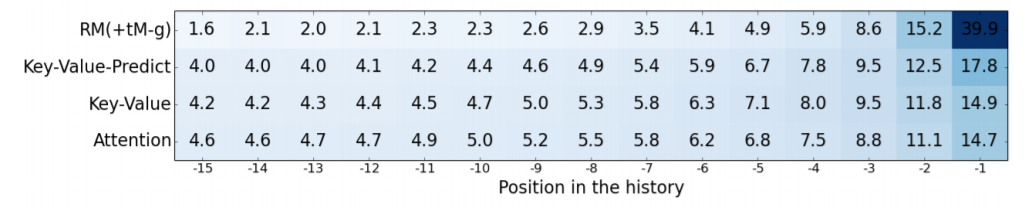
この図は、実験に使ったWikipediaのコーパスからランダムにサンプリングして、その予測の際のAttentionの重みを表したものです。右から-1~-15となっていますが、-1が一つ前で以後2つ前、3つ前、と続き色が濃いところほど重要視されています。
これを見ると、-1、つまり直近が非常に重視されており以後ほとんど参照されていないことがわかると思います。
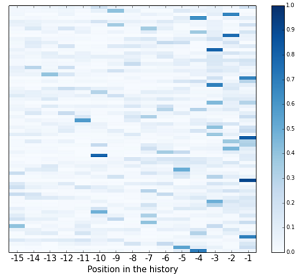
こちらはより詳細な図になりますが、重みが高い点は-1~-5くらいに集中しているのがわかるかと思います。実際、AttentionのWindow Size(どれくらい過去まで見るか)は5が最適との結果でした。
ということは・・・?
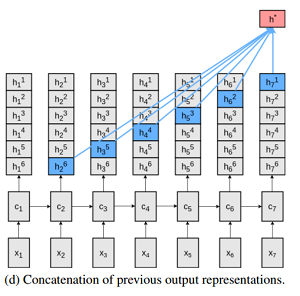
こちらは、普通のn-gram(※)を利用したRNNで、どのみち過去5くらいしかAttentionされないなら過去5つ分の隠れ層をそのまま使って予測すりゃいいという形で組んだものです。
※n-gram:複数の単語をまとまりとしてとらえる手法。a,b,c,dという系列があった場合、2-gramなら(a, b), (b, c)...、3-gramなら(a,b,c), (b,c,d)...となる。
h^*_t = tanh \left(
W^N
\begin{bmatrix}
h^1_t \\
\vdots \\
h^{N-1}_{t-N+1}
\end{bmatrix}
\right)
equation13より抜粋
その結果、凝ったRNNをしのぐ精度で、かつ本研究の提案した手法に肉薄する精度を記録したという。
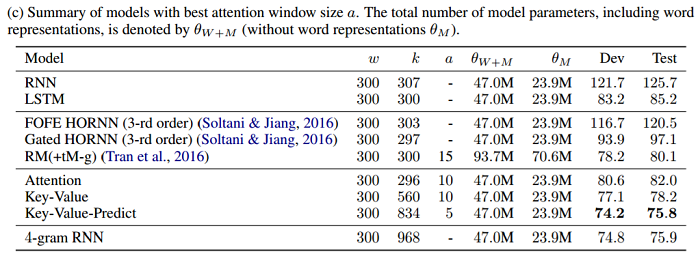
(値はperplexityで、低いほどよい。Key-Value-Predictが本研究の提案手法で、4-gramが単純に過去の隠れ層を使ったモデル)
何やねんこれは!

from シャドウハーツ2
という形で幕は閉じます。
Attentionの耐えられない短さを生む、2つの問題点
まず、こんな結末になったのは2つの問題点が考えられます。
- 問題設定の問題
- 学習の問題
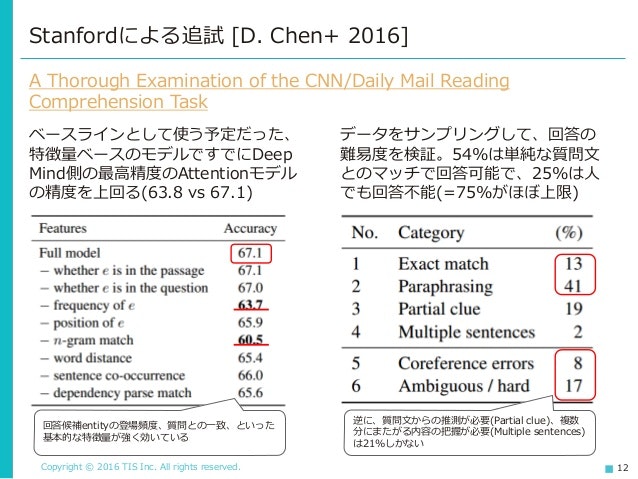
問題設定の問題、とは、そもそも長い依存を必要としないタスクだったため、このような結果になったという点です。これは、以前Deep MindがやらかしてStanfordに指摘された研究でも同様なことがありました。
文章を読み、理解する機能の獲得に向けて-Machine Comprehensionの研究動向-より。

Deep MindがCNNのニュースから機械的に学習用データセットを作成することに成功した、と言う話なんですが、このデータを検証したところ・・・

簡単なモデルでニューラルネットを圧倒できた、という話です。調べてみると長い依存や文脈の理解が必要な問題がそもそも少なく、単純なモデルでも十分な精度が記録できました。
つまり、今回のケースでも同様に単純なモデルでも十分解答が可能なタスクだったから単純なモデルでも高精度が記録でき、かつAttentionが短い範囲に収まったのではないか、と考えられるわけです。
この点への対応として、最近は高度な理解が求められるデータセットの整備が進められています。StanfordのSQuAD、またSalesforceのWikiTextなど、昨年だけでもかなりのデータセットが公開されました(日本語のデータはないかって・・・?)。
もう一点は、やはり長い依存関係を上手く捉えられていないのでは、という点です。これは上記の通りそうした依存を必要とするデータがないことも一因と考えられますが、ネットワークの構成などの面からも検討の余地がありそうです。
最近はやはり外部にメモリを持つのがトレンドです。
また、構造を変えることでより長期の依存を把握できるようにする試みも行われています。
こちらは音声の研究で、音声の場合はデータの密度がかなり高いです(通常の音楽だと1秒4万近くのデータがある)。そのため、長期の依存をとらえる必要性がより高まります。そういう意味では、長期の依存をとらえるのに適した構造は音声の方から先に出てくるかもしれません。
(この論文では冒頭に「WaveNetとかもあるがCNNではやはり長期の依存はとらえられないと考えている」というような一文があり、熱いものを感じます)
提案しているネットワークは、イメージ的にはピラミッド状にRNNを積み、上の方ほど長い依存を担当するという役回りになっています。担当する依存関係の長さで役割分担するというイメージですね。
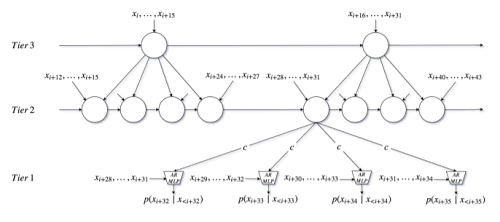
ちなみに、このモデルを利用した音声合成も提案されています。
RNNで良く使用されるLSTMに代わるセル構造を探索する試みもされていますが、実際の所LSTM、その簡略版であるGRUはかなり良くできており、それを超えるのは簡単でないという研究結果も示されています。
そのため、メモリの外部化も含めた、ネットワーク構成全体での工夫の方が筋としてはいいのかなという印象があります。
このように、様々な点から現在も研究が進められています。この結末の先の展開も、どんどん更新されていくでしょう。