どんなもの?
対話管理部には強化学習を利用したモデルが良く利用される(POMDPなど)。この学習にはやはり実際のユーザーからのフィードバックを使いたいが、問題がいくつかある。
- ユーザーの目的に合致しているかを使う場合: ユーザーの目的は当然事前にはわからないので、合っているかそもそもわからない
- ユーザーの主観評価を使う場合: PARADISEなどの評価フレームワークがあるが、値は揺らぎがでかい。特にお金で雇ったユーザーは本当に対話したいわけではないので、なおさら。
もしユーザーが感じている評価を予測するモデルがあったら、実際のユーザーとの対話からその評価を予測し、学習させることができるだろう。というわけで、ユーザーの主観評価を予測するモデルをつくろう!という話。
先行研究と比べてどこがすごい?
これができれば、ユーザーについての事前知識(目的が何かなど)がなくても強化学習を行うことができる。
※ただ、実際本当のユーザーとの対話はそれほど数が取れないので、学習させる際はユーザーの行動を模したユーザーシミュレーターを作成してそれを使って学習することが多い。ただ、本論文では「Real Users」からの学習にこだわりをもっている。
技術や手法のキモはどこ?
ユーザーのDialog Act、信念状態、システムAct、ターン数(1/限界ターン)を結合してベクトル化し(21,575,20,1=617次元)、それをRNNに突っ込んでユーザーの目的に合致している確率を算出する(CNNも検証しているが、精度が悪いので忘れていい)。
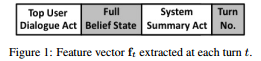
学習データは、アジェンダベースの対話をエミュレートするユーザーシミュレーターを作成して作成(この場合、ユーザーの目的は明らかなのでアノテーションも楽)。
どうやって有効だと検証した?
RNNを使った報酬予測モデルで学習させたものと、これまで通りユーザーからのフィードバックを利用して学習させたものとの間の精度を比較した。結果、精度はほぼ同程度だった。
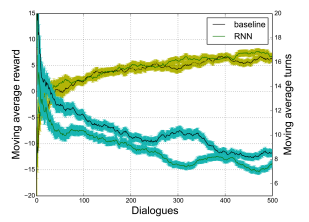
報酬と必要なターン数とが、baselineのモデルと同程度に遷移していることがわかる。
ユーザーからのフィードバックで学習させる場合は、850くらいの対話が必要でしかも揺らぎ(目的達成の評価と主観評価がずれているもの)のないものを厳選する必要があるので、この手間がなくなるのは大きい。
議論はある?
今回はドメインを限定した対話で行ったので、学習したモデルの他ドメインへの転移(transfer learning)などが今後の課題として挙げられる
次に読むべき論文は?
これはこれとして、Usersimulatorの作り方は見ておいた方がよいかも。下記はPOMDPのとてもよいまとめで、この5章にユーザーシミュレーターについての解説がある。