Multiresolution Recurrent Neural Networks: An Application to Dialogue Response Generationの内容のサマリ。
どんなもの?
RNNはLSTMとかの構造をいじるのが主流になっているけれど、入力を工夫した方がいいんじゃない?ということで、入力列を通常の文字列とそこから「粗い(Coarse)」情報を抽出したものとを並列で入力するモデルを提案している(=multi resolution)。
先行研究と比べてどこがすごい?
通常のRNNは当然扱える系列は1つだけれども、本研究はこれを複数・パラレルにするという所に意義がある。
技術や手法のキモはどこ?
encoder-context-decoderというモデルを、通常文用と粗いもの用と2つ用意し、それを組み合わせている。
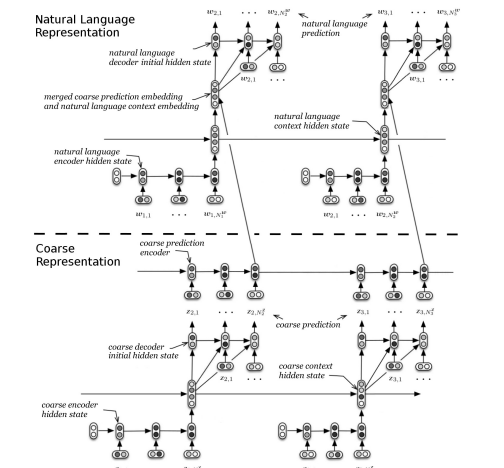
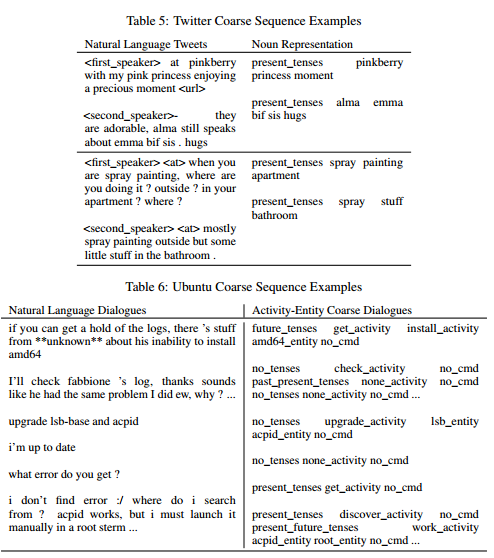
「粗い」情報を作る方法として、名詞のみ抽出やActivity-Entity(dialog actと質問カテゴリのようなもの)を使用する方法が提案されている。Ubuntuテクニカルサポートの対話データとTwitterの対話(タスク指向&非タスク指向)双方で実験しており、それぞれにあったCoarseを使っている。
どうやって有効だと検証した?
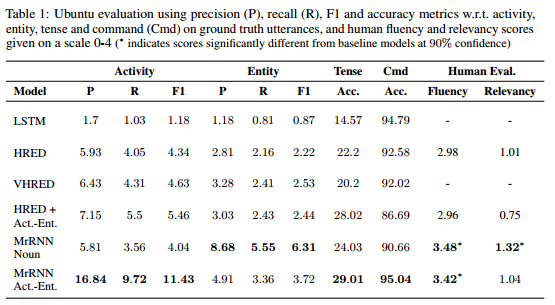
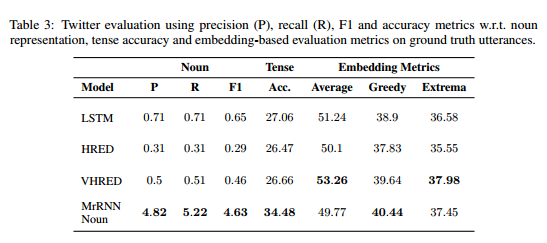
ベースラインのモデルとして以下を用意して、precision、recall、f1、そして主観評価を比較。
- Seq2Seq+LSTM(RNNLM(RNN Language Model) + LSTM)
- HRED+LSTM (HRED = Hierarchical Encoder Decoder)
結果としてUbuntuのテクニカルサポートというタスク指向型対話、Twitterの非タスク指向型双方で既存のモデルを上回るという最強感のあるものとなっている。
議論はある?
入力文字列に対する適切な抽象化を行うこと(fine-grained abstraction)は、対話中のコンテキストなどのより高次な抽象的な情報を抽出するのに有用な可能性が示された。このモデルは詩や論証といったものや、他の分野では音楽などといったものの生成にも使えると考えている
次に読むべき論文は?
この論文中に実装の方法などがかなりきめ細やかに書かれているので、まずはこれらを読み込むとよいと思う。