最近公開されたGitHubのAPIは、GraphQLという形式に対応しました。今後はこちらが主流になっていくようで、既存のREST APIからGraphQLへのマイグレーションガイドも提供されています。
今回は、このGraphQLについて、実際にGitHubのAPIを叩きながらその仕組みを解説していきたいと思います。
GraphQLとは
歴史
GraphQLは、Facebookの中で2012年ごろから使われ始めたそうです。その後2015年のReact.js Confで紹介されたところ話題となり、同年"technical preview"のステータスでオープンソースとして公開されました。その後仕様が詰められ、2016年9月に晴れて"preview"を脱し公式実装として公開されました。これと同じタイミングで、GitHubからGraphQLバージョンのAPIが公開されています。
このあたりの経緯については、以下のブログに詳しいです
GraphQLのメリット
GraphQLのメリットは、以下3点です(公式より)。
- 必要なデータだけリクエストし、受け取れる
- 例えばIssueのタイトルだけが欲しい場合、REST APIだとIssueのAPIを叩いたらIssueの情報がドバッと返ってきます。GraphQLは必要なデータ構造とフィールドをリクエストで送ることができ、その情報だけを受け取れることができます。一言で言うとエコです。
- 関連するオブジェクトを1クエリで処理できる
- 例えば「Issueを投稿したユーザーの画像」を取ろうとした場合、REST APIだとIssueをまず取ってきてその中の投稿ユーザーのIDを使って今度はユーザーのAPIを叩いて・・・とやらなくてはなりません。GraphQLではデータ構造を記述する際関連オブジェクトの構造もネストすることができるため、1クエリで関連に基づくデータを一度に取得することができます。一言でいうと省エネです。
- クエリの検証が容易
- 上記で述べた通り、GraphQLではデータ構造をクエリとして送ることから始まります。このデータ構造は当然事前に定義が可能なため、クエリとして送られた構造のチェックは容易ですし、クライアント側はどんな型のデータが返ってくるか事前に想定することができます。一言でいうと型ってます。
百聞は一見にしかずと言うことで、実際に上記のメリットを体感してみましょう。GitHubでは、GraphQLを実際に叩いて試すためのインタフェースを提供しています。こちらで実際にGraphQLを実行してみましょう。
必要なデータだけリクエストし、受け取れる
では、早速GraphQLで「必要なデータだけリクエストし、受け取って」みます。先日作成したtypoを検知するリポジトリの情報をGraphQLで受け取ってみたいと思います。
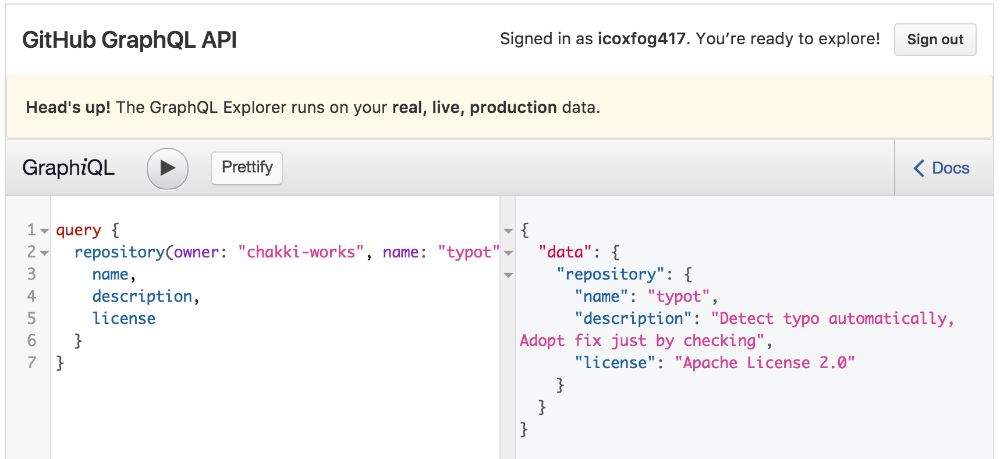
左側のクエリは以下のようになっています。
query {
repository(owner: "chakki-works", name: "typot") {
name,
description,
license
}
}
GraphQLは、operationの宣言から始まります。具体的には、データの取得(query)か更新か(mutation)の宣言となります。今回は情報の取得なのでqueryです。
次いで、queryを行う対象(Field)を宣言します。Fieldには条件(arguments)を渡すことができ、ここではownerとnameで条件を指定しています。どんなFieldがあり、どんな条件が渡せるかはドキュメントに記載がされています。

このドキュメントから、queryによってrepositoryというFieldにアクセスでき、その引数(Argument)としてownerとnameが要求されていることがわかります。これらの型がStringで、かつ必須(!がついているのは必須引数)ということもわかります。
そして、repositoryのFieldから得られるのはRepositoryオブジェクトということがわかります(括弧で囲われているので一瞬こいつが引数でないかと錯覚しますが、これが返り値です。GraphQLはネストした構造になるので、それを意識しているのだと思います。ドキュメントの()を{}に脳内置換してみればわかりやすいです)。
では、Repositoryオブジェクトに含まれる属性はどんなものがあるかというと、こちらもリンク先のドキュメントで確認できます。
今回はここからname、description、licenseだけ取得します。これが「必要なデータだけ」のリクエストです。その実行結果は、以下のようになっています。
{
"data": {
"repository": {
"name": "typot",
"description": "Detect typo automatically, Adopt fix just by checking",
"license": "Apache License 2.0"
}
}
}
要求した分だけのデータが返ってきているのがわかるかと思います!エコですね。
関連するオブジェクトを1クエリで処理できる
関連するオブジェクトを1クエリで処理できるのもGraphQLの魅力です。先ほどのクエリを編集し、「リポジトリのIssue」を取得してみましょう。
query {
repository(owner: "chakki-works", name: "typot") {
name,
description,
license,
issues(first: 10, states: OPEN){
totalCount,
edges{
node {
title
}
}
}
}
}
新しくissuesというConnectionを加えています。Connectionは関連を表すもので、issuesによりRepositoryからIssueへの関連であるIssueConnectionを取得することができます。
GraphQL API v4/IssueConnection

issuesによって得られるのはIssueConnection、つまり各Issueへの接続なのでedgesを渡ることでIssueの情報にアクセスできます(実はnodesで直接いけるけれど)。ここでは、Issueのtitleを表示しています。これで以下のようなレスポンスを得ることができます。
{
"data": {
"repository": {
"name": "typot",
"description": "Detect typo automatically, Adopt fix just by checking",
"license": "Apache License 2.0",
"issues": {
"totalCount": 3,
"edges": [
{
"node": {
"title": "Support comments in source code"
}
},
{
"node": {
"title": "Exclude word list (white list) for repository"
}
},
{
"node": {
"title": "False positives reported"
}
}
]
}
}
}
}
このように、Connectionを含むデータ構造に対してリクエストを発行することで、関連データを1クエリで取得することができます。これはGraphQLの強力な機能の一つとなっています。
なお、nodeがなんかObject型みたいでキモいという場合、型の指定を書くことができます。
query {
repository(owner: "chakki-works", name: "typot") {
name,
description,
license,
issues(first: 10, states: OPEN){
totalCount,
edges{
node {
... on Issue {
title
}
}
}
}
}
}
... on Issueで、nodeの型がIssueの時にtitleを出すようにしています。型の記法については、GraphQLの公式ドキュメントに詳しいです。
クエリの検証が容易
実際にExplorerを試してみるとわかりますが、結構賢い補完とエラーメッセージを出してくれます。

これは、データ型がまず定義されており、クエリにおいてもレスポンスにおいてもそれを中心に動作するという仕様の賜物です。
なお、このGitHubで提供されているExplorerはオープンソースで提供されているgraphiqlをベースにしています。
つまり、APIの実装にあたり定義した型(Schema)のファイルさえあれば、このツールにその定義を取り込むことでAPIの実行環境をユーザーに提供できるということです(exampleで実行方法を確認でできます)。GraphQLでのAPI定義を行うことで、型による検証に加え試行環境まで提供できるのは採用にあたっての大きなメリットになると思います。
上記で紹介した点以外にも、GraphQLには様々な機能があります。ぜひ、GitHub APIをきっかけに試してみていただければと思います。