ブルーライトに目が焼かれるよりも、ブルーオーシャンで目を癒したい。
もうすぐ2015年も終わりに近づいていますが、皆様いかがお過ごしでしょうか。年末ぐらいは自然に還りたいということで、今回はトピックモデルを利用した対話形式で旅行提案を行うアプリケーションの作成方法についてご紹介します。
本記事は、以前公開したトピックモデルを利用したアプリケーションの作成の姉妹記事になります。
当時はアプリケーションの作成が追い付いておらず、「アプリケーションの作成」と言っておきながらアプリケーションの作成に至っていなかったため、それを補完する内容になります。
トピックモデルそのものについては今回はあまり触れないので、興味がある方は前述の記事の方をご参照ください。
トピックモデルとは
詳細な解説はこちらに譲りますが、トピックモデルとは、その名前の通り文書をトピックごとに分類するための手法です。
ここでいう「トピック」とは、具体的には以下のようなイメージになります。
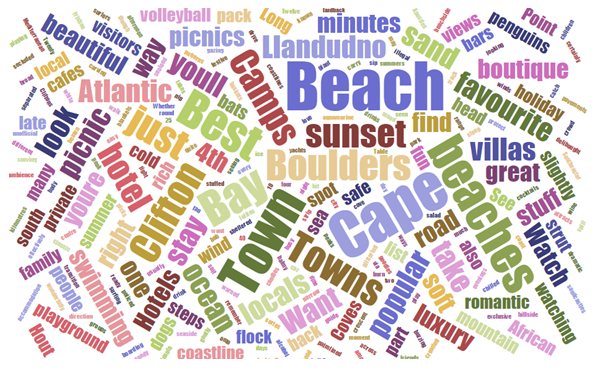
これは旅のブログから作成したワードクラウドです。「トピック」とは、このように単語で構成され、そしてその単語は頻出するものとそうでないものがあります。この「出現単語」と「出現確率」を規定する確率分布を推定することが、トピックモデルの主眼となります。
この確率分布が明らかになれば、似ている分布を持つ文書の分類が可能になり、また分布間の距離から文書間の関連度を推定することも可能になります。
対話アプリケーションへの適用
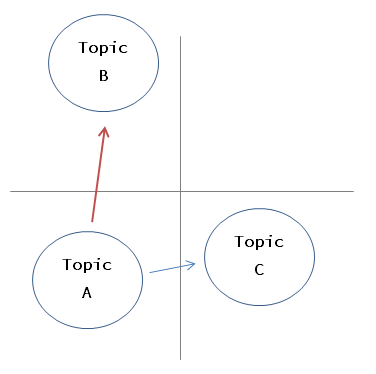
トピックは前述のように確率分布で表すことができ、そうすると分布間の距離を算出することができます(今回はKL-divergenceを使用しました)。
この距離を利用し、トピックAのスポットを提案してみて、答えがNoであれば離れたトピックの提案をする(図では最も離れているBのトピック)というようなシンプルな方針で実装をしてみます。
対話アプリケーションの実装
今回実装したアプリケーションはこちらになります。
同じトピックから3つほど候補を提案して、それは下の矢印で切り替えられるようにしています。気に入った/イメージが違う、というものがあれば、下のGood/Badボタンで評価する、というような寸法です。評価を受け、似た/離れたトピックの提案を行います。
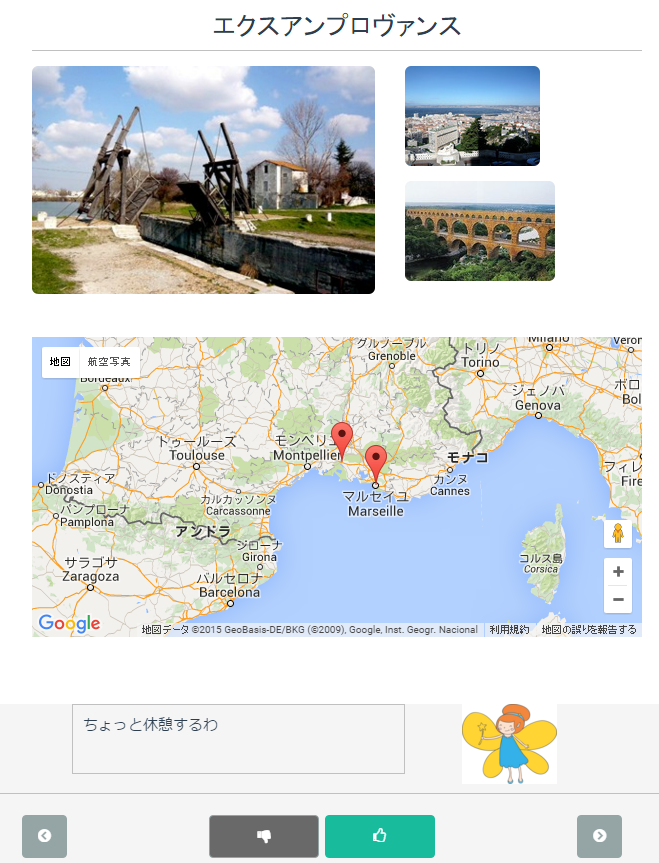
Heroku Buttonを付けているので、お手持ちのHeroku環境にデプロイ可能です。俺の作ったトピックモデルで試す!というのも十分可能です。
データとしては、AB-ROADのAPIを利用しており、こちらの利用登録が必要です。
アプリケーションの実装
アプリケーション構成は以下のようになっています。
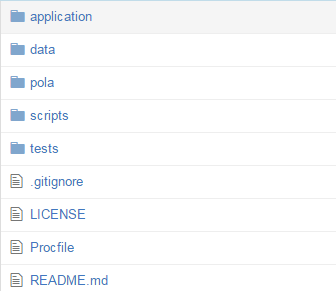
-
application: Webアプリケーションの実装 -
data: 学習したモデルのファイルを格納。データベースを使うのが手間だったので今回スポットのデータも入っていますが、本来はignoreではじきます。 -
pola: この中にトピックモデル、それを利用した対話の実装が入っています。polaは今回の「トピックモデルを利用した対話」を行うエンジンの名称です(海外旅行なので外人っぽい名前にした)。 -
scripts: データを抽出したり、整形したり、学習させたりといった各種スクリプト -
tests: テストコード
構成に当たっては、以下点に気を付けました。
-
アプリケーションの実装と機械学習の実装は分ける(
applicationとpolaの分離)
複数チームでの開発となればこれらの担当は分かれる可能性は高いでしょうし、機械学習部分のポータビリティを上げるという意味でも分けておいた方がいいと思います。 -
データの抽出・整形処理と機械学習モデルの実装とは分ける(
polaとscriptsの分離)
機械学習部分の実装は主に「データの抽出・整形」にまつわるコードと「機械学習モデル」の部分で分かれます。そして、前者は本当に扱うデータ依存になることが多く、これを「機械学習モデルの実装」に組み込んでしまうとモデル自体がデータソースと一蓮托生になってしまうので、これを分離しています。機械学習モデル部分は、「こういう形式でデータが入れば適用可能」という風にある程度抽象化しておくのが望ましいと思います。 -
学習済みモデルのファイルと機械学習実装の分離(
polaとdata)
機械学習モデル本体の修正(アルゴリズムの修正etc)と学習結果である学習済みモデルの更新は話としては別なはずなので、今回はこの二つを明示的に分けています。もちろん、学習済みモデル込で管理するという考えもありだと思います。
あとは、アプリケーション同様、機械学習モデルについてもきっちりテストコードを書く、機械学習モデルについてはiPython notebookでドキュメントを付属させる、といったところでしょうか。
今回構築したトピックモデルの構築仮定とその検証は、以下のiPython notebookから参照可能です。
enigma_abroad/pola/machine/topic_model_evaluation.ipynb
トピックモデルの構築
提案を行うに際しては、当然アプリケーションの頭脳であるトピックモデルの構築が欠かせません。
今回は、例の姉妹記事であるピックモデルを利用したアプリケーションの作成と同様に、gensimを使って構築を行いました(一応pymcも使ってみたところ、学習でメモリ落ちしたので封印)。そして悲しいことに、同様に精度は出ませんでした・・・が、ここは一旦このまま進みます。
なお、やはり実際にアプリケーションで機械学習を使う、という場合になるとチュートリアルのように「精度99%や!」なんてことはまずなく、あったとしてもそれは過学習による幻覚か、自ら生んだバグの何れかであることが多いです。
これを克服するには、地道なデータ収集と地道なデータの前処理が必要になります。あ・・・ありのまま起こったことを話すと、おれは機械学習を使ってクールなことをやろうとしていたんだが、いつの間にか一つ一つ丹念にコーパスから除外する単語を設定していたんだ・・・。
トピックモデルのようなコンテンツベースの推薦は、推薦によく使われる協調フィルタリングに比べてユーザーの評価データがたまらない状態でも推薦が可能という強みがありますが、やはりコンテンツの分量、そしてその整形をきちんとしないとうまくは働いてくれません(文書の件数もありますが、文書単体のボリュームも結構ないといけない印象です)。
考察
アプリケーション化はできたものの、肝心のトピックモデルがなかなかうまく構築できていません。前回はヘアサロン、今回は旅行プランと異なったデータを扱いましたが、何れもうまくトピックが分類できないという悲しい結果に終わっています。
この原因としては、やはりデータの問題が大きいかなと思ます。
- 一文書あたりの単語数: それなりに長くないとキーワードとなる単語でも数件しか登場せず、他の単語とそれほど差異が出ない。結果、どのトピックのなのか判別しづらくなり、また全体の語意数にも影響する。
- 明確なトピック差: 何れも、「ヘアサロン」「旅行プラン」と、既にあるカテゴリの中の文書になっているため、登場する単語にそれほど差異が出なくなっている。
端的にはいろいろなバリエーションの文書があり、かつそれぞれがそれなりに長いという状況での適用が望ましいのだと思います。同じカテゴリ内の分類をより細かく行いたいというケースには、どうにかして事前知識を構築しておく必要があるのではないかと思います。
- 事前知識トピックモデルの構築: Wikipediaなどからあらかじめ単語のクラスタを構築しておき(「海」「ビーチ」は同じクラスタ、など)、単語そのもでなく、単語のクラスタをベースにトピックモデルを構築する。こうすることで、表記ゆれや同意単語をまとめることができ、文書量が少なくてもトピックを発見しやすくなる。
- 単語の意味表現の学習: 人間なら、「海」「ビーチ」という単語があれば、その頻度が仮にそれぞれ一回であっても海についての話と認識できます。用は、単語の出現頻度でなくその意味と関連単語でトピックを考察していると言えます。ちょうどword2vec等を利用することでこれらの特徴量をベクトル化することができるので、事前に学習させたモデルを基に各文書のベクトル量を算出し、それを基に分類を行う。
他にもいろいろなアイデアがあると思うので、ぜひ自分なりのモデルを作ってブルーオーシャンに連れて行ってくれるアプリケーションを構築してみてください。
