最近「人工知能が~」というニュースが山のように出てきますが、その中にはだいぶ誇張された表現のものも少なくありません。
人工知能関連の技術に注目が集まるのは、研究資金の増加や案件の発生という面では良いことです。しかし、「仕事が奪われるぞ!」みたいな過度な不安を煽ったり、「人工知能だったら何でもできるんやろ?」といった過度な期待を煽ってしまうことで、実体とはかけ離れた議論や誤解を生んでしまうという面もあります。
本稿では、目についた中で大きな誇張があるニュースを取り上げるとともに、その実際のところはどうなのか?について紹介をしていきたいと思います。本記事が、冷静な議論と共に背景となる技術的な面への興味の喚起となれば幸いです。
日経のAI記者が始動、1日30本の決算サマリーを量産
同僚が人工知能という世界が現実のものになろうとしている。
人工知能は人の仕事を奪うことになるのか、あるいは型にはまった定常的な仕事から人を解放することになるのかは、まだ分からない。いずれにしろ、人工知能が身近な存在になりつつあるようだ。
「AI記者」というのが結構なパワーワードで、まるで人工知能が自分で考えて記事を書いているように思えますが、実際はそんなことはありません。
要約はText Summarizationと呼ばれる研究領域で、その手法としては大きく3つの手法があります(※この分類は本記事で説明を行うための便宜的なもので、公式にこうしたカテゴリがあるわけではありません)。
- 抜粋型: 要約する対象の記事から、重要と思われる文書を抜いて要約を作成する
- 編集型: 抜粋した文章を組みあせたりすることで、要約を作成する
- 生成型: 要約する文章を何らかの形で学習させ、学習結果を基に文章を「生成する」
抜粋型は、文字通り元の文章が必ず存在しますが、生成型は生成されたものは元の文章にはない、オリジナルなものになります。抜粋型は元の文をそのまま抜いてくるため読んで違和感のない文章になりますが、抜いてきた文の寄せ集めになるため若干冗長な印象になります。反面、生成型はより簡潔な要約、また文字数を指定した生成などが行いやすくなりますが、正常な文構造を維持したままでの生成はなかなか難しく、日本語として文が破綻しているようなものを生成してしまうリスクがあります。
編集型は間をとるような手法で、「[a]が[b]を発表」という定型文を用意しておいてaとbに入るものを埋める、また抜粋したものから不要な語を切り落として作成するといった、抜粋結果をベースに編集を行うタイプのものです。これにより、生成ほどのリスクを負わずに抜粋の弱点をカバーすることを狙っています。
おそらく「AI記者」としてイメージが近いのは生成型と思いますが、今回の日経の要約は抜粋/編集型と思われます。記事中のスライド資料の中に文選択というプロセスがあるほか、要約された記事が実際の決算資料からの抜粋になっていることが確認できるためです。
- 自動生成された記事の例: T&Cメディカルサイエンスの16年11月期、最終損益2億3900万円の赤字
- 実際の決算短信: 平成28年11月期 決算短信〔日本基準〕(連結) (2017.01.25)
そのため、知能があるような「AI記者」という単語でなく、「人工知能による決算短信の要約」ぐらいのほうがよかったのではないかなと思います(バズりはしないと思いますが)。
テキスト要約の研究動向については、2013年の自然言語処理研究会の西川先生のスライドがとてもよくまとまっているので、興味がある方はご覧いただければと思います。
人工知能が人工知能をプログラムする時代がやってきた
プログラムをプログラムするのは誰か? 近々、人間ではなく別の人工知能プログラムが高度な人工知能プログラムを書けるようになるという。
人工知能によって作成された人工知能プログラムの性能が人間が開発したプロダクトと同等であるか、場合によっては上回わっていたという。
すると機械学習プログラムを書けるデベロッパーでさえ失業の危険にさらされるのだろうか?
タイトルは間違っているという訳ではないのですが、本文を読むとまるで人工知能がカタカタとプログラミングして人間のプログラマーより優秀だった!みたいな印象を受けます。最後の一文に一応「しかし同時にAIの普及が人間の努力を不要にするとかあらゆる分野で失業を増やすといった不安が根拠のないものであることも明らかだ。」とは書いているのですが、その根拠は特に述べられていないため、取って付けたような感じになっています。
この背景になっているのは、機械学習による機械学習モデルの構築の話です。元となっているのはこちらの論文です。
Designing Neural Network Architectures using Reinforcement Learning
機械学習での学習を行う際は、ハイパーパラメーターのチューニングが大きな問題になります。ニューラルネットワークを題材にすると、層はいくつにするのか、ノードの数はいくらにするのか、活性関数は、学習させるときの学習率は・・・と非常に多くのパラメーターがあります。このチューニングは、職人芸ともいわれます。
それを何とか自動化できないか、ということで、強化学習によってこのチューニングを行ってみた、というのが上記の論文になります。これにより、人はパラメーターを刻んで調整するという無為な作業から解放される期待が持てますし、この作業がそもそもプログラマーの仕事かというと、違うと思います。また、強化学習のため扱うパラメーターの範囲は以下のように人が決めています。
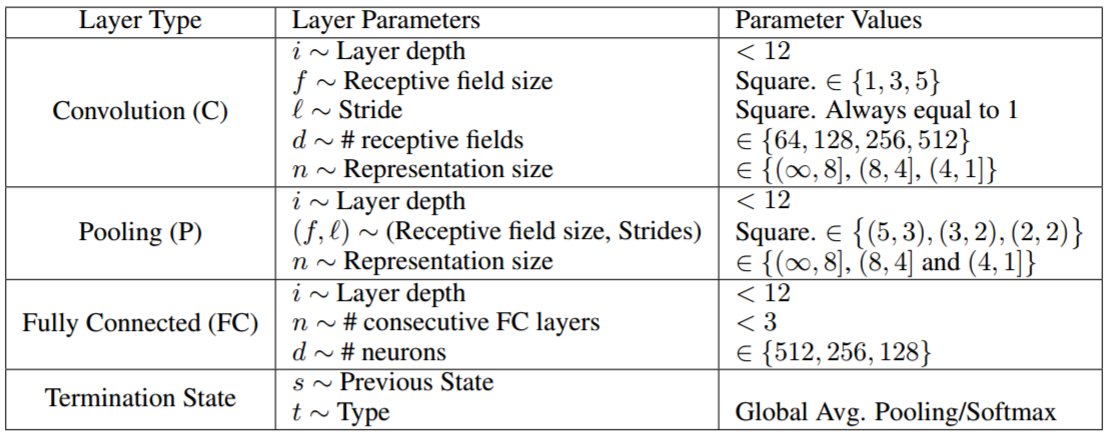
強いて言えば、学習を効率的にやってくれる優秀な助手を作ろうとする試みといえると思います。真摯なタイトルにするなら、「人工知能の開発においてボトルネックとなっていた、学習のチューニングの効率化の試み」という感じになると思います(バズりはしないと思いますが)。
この研究は、Learning to Learnというように呼ばれる研究テーマです。以下にいくつか同様の研究をピックアップしてみたので、興味がありましたら是非参照してみてください。
- Learning to learn by gradient descent by gradient descent
- Learning to reinforcement learn
- TUNING RECURRENT NEURAL NETWORKS WITH REINFORCEMENT LEARNING
Google「DeepMind」の人工知能は赤ん坊のように「触って覚える・判別する」能力を学習したとの発表
人間のような「触ってみる」という行動を通じて目の前の物体の特徴を把握することにGoogle DeepMindの人工知能(AI)が成功したことが発表されます。
これはいわば、人間が物体の性質を把握するために取る行動をロボットができるようになったことを意味しており、ロボットが人間の能力を超える「シンギュラリティ(技術的特異点)」にたどり着くためのステップをまた1つ登ったといえる出来事です。
記事の中身的には論文の内容に沿ったものになっているのですが、その研究成果を拡大して「ロボットが人間の能力を超えるシンギュラリティにたどり着くためのステップ」とするのはさすがに誇張が過ぎると思います。とりあえずシンギュラリティというパワーワードに関連させたかった感がありありと感じられます(文末でも繰り返しがある)。
この記事については、英語のNEW SCIENTISTで先行記事がありました。こちらはタイトルが「Google DeepMind’s AI learns to play with physical objects」、直訳すれば「Google DeepMindのAIが物理的な物体を使って遊ぶことを学ぶ」(by Google翻訳)で、これは落ち着いた、事実ベースのタイトルになっています。これを「赤ん坊のように」「シンギュラリティ」のような言葉で飾り立てて煽ってしまったのが、上記の記事になります。
ロボットで実験するとなると実機が必要ですが、最近は強化学習用の3次元のゲーム環境などがあったりするので、それで学習にチャレンジしてみることができます。
- ViZDoom
- 3DのシューティングゲームであるDoomの強化学習用環境です
- Microsoft/malmo
- マインクラフトの強化学習用環境です
やっぱ物理や!という方は、Amazon Picking Challenge用のデータセットや、ダイソンの研究所が出している屋内のシーンのデータセットがあるので、ぜひ活用してみてください。
- Amazon Picking Challenge Object Scans Robot Learning Lab, UC Berkeley
- SceneNet RGB-D: 5M Photorealistic Images of Synthetic Indoor Trajectories with Ground Truth
「人工知能ニュース」に対するリテラシー
ご紹介した記事は、タイトルこそセンセーショナルですが中身はわりとしっかりと書いてあります。しかし、その「タイトル」こそが誤解と煽りの温床となってしまっています。記事のビュー数(はては広告収入)を稼ぐには仕方がないこととは思いますが、それにより扱っている技術が危険にさらされてしまっては本末転倒と思います。
記者側の方に注意していただきたいのはもちろんですが、記事を読む私たち自身にも、その「実際のところ」を読み解く力が求められていると思います。