機械学習を行うために、画像から特定の物体(領域)だけ切り出して認識したり学習データを作りたい、ということがよくあると思います。
本稿では非常に多くの機能を持つOpenCVの中から、そうした機械学習のために利用する機能にフォーカスしてその利用方法を紹介していきたいと思います。具体的には、下記のモジュールを中心に扱います。

基本的な切り出しの手順は以下のようになります。以下では、このプロセスに則り解説を行っていこうと思います。
- 前処理: 物体検出が行いやすいように、画像の前処理を行います
- 物体検出: 物体の検出を行い、画像から切り出します
- 輪郭検出: 画像上の領域(輪郭)を認識することで、物体を検出します
- 物体認識: OpenCVの学習済みモデルを利用して対象の物体を認識し、検出を行います
- 機械学習の準備: 切り出した画像を用い、予測や学習を行うための準備を行います
また、OpenCVの環境構築についてはminicondaを利用しています。こちらをインストールし、以下のコマンドを打てば環境構築はもう完了です。
- conda create -n cv_env numpy jupyter matplotlib
- conda install -c https://conda.anaconda.org/menpo opencv3
- activate cv_env
(※仮想環境の名前はcv_envである必要はありません。また、Mac/Linuxだとactivateが落ちるのでちょっと対応が必要です。詳しくはこちらをご参照ください)
今回ご紹介しているコードは以下のリポジトリで公開しています。必要に応じ参照いただければと思ます。
前処理
物体の検出を行う際には、「輪郭がはっきり」していて「連続している」と都合が良いです。

このために効果的な手法が、「閾値処理」と「フィルター処理(ぼかし)」になります。このセクションではこの2つに重点を置き解説していきます。なお、画像処理を行う場合たいていは事前にグレースケール化を行うため、それについても触れておきます。
グレースケール化
画像処理においてカラー情報が必要になることはほとんどないため、事前にグレースケール化を行うことがとても多いです。ただし、最終的に機械学習で使用する際はRGB情報が必要なことが多いため、画像から切り出しを行う際はカラーの方から行わないといけない点に注意してください。
OpenCVでカラー画像をグレースケール化するのはとても簡単です。cv2.cvtColorでcv2.COLOR_BGR2GRAYを指定するだけです。
import cv2
def to_grayscale(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
return grayed
cv2.COLOR_BGR2GRAYの名前の通り、cv2.imreadで読み込まれる画像は色情報がBGR(青緑赤)の順で読み込まれています。画像を読み込んだ変数は(numpyの)行列となっていますが、そのサイズを確認すると以下のようになっています。
img = cv2.imread(IMAGE_PATH)
img.shape
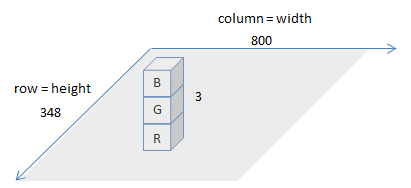
>>> (348, 800, 3)
これは、読み込んだ画像が348x800x3の行列で表現されていることを表しています。イメージ的には、下図のような感じになります。
なお、画像を表示したりするのに良く使うmatplotlibは、画像がRGBで入ってくることを期待しています。そのため、OpenCVで読み込んだ画像をそのままmatplotlibにぶっこむと以下のようになります(左が元の画像、右がOpenCVで読み込んだものをそのままmatplotlibで表示したもの)。

そのため、matplotlibで表示する際は以下のようにカラーの順番を変更する必要があります。
def to_matplotlib_format(img):
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
閾値処理
閾値処理とは、ある一定の閾値(threshold)を超えているか否かで画像処理を行うことです。例えば輝度が一定値に達していないところをすべて0にする、といったような処理です。これにより背景を落としたり輪郭を強調することができ、下図のような具合に加工することができます(左側が元の画像、右側が閾値処理を行ったもの)。

OpenCVにおける閾値処理は、cv2.thresholdで実行することができます。ここでの主要なパラメーターは、閾値となるthresh、値の上限であるmaxval、閾値処理の種別であるtypeになります。
下表は、閾値処置のtypeの種別と、その際に閾値(thresh)/上限(maxValue)がどう使用されるのかについてまとめたものです。
| Threshold Type | over thresh |
under thresh |
|---|---|---|
THRESH_BINARY |
maxValue | 0 |
THRESH_BINARY_INV |
0 | maxValue |
THRESH_TRUNC |
threshold | (as is) |
THRESH_TOZERO |
(as is) | 0 |
THRESH_TOZERO_INV |
0 | (as is) |
(as is)は、元の画像の値がそのまま使用されるという意味です。閾値処理について詳細を知りたい方は、下記の資料が参考になります。
OpenCV Threshold ( Python , C++ )
今回利用した鳥の画像は、背景の青色を落とす以外に、鳥の羽部分の境界(明るい)を明確にするようにしています。
- 背景を落とす->THRESH_BINARY
- 閾値より大きい箇所(=明るい=薄い=背景): maxValue(255=白=消す)
- 閾値未満: 0(黒=強調)
- 境界の明確化->THRESH_BINARY_INV
- 閾値より大きい箇所(=明るい=鳥の骨=境界): 0(黒=強調)
- 閾値未満: maxValue(255=白=消す)
そして、最後にこの2つの処理結果をマージしています。
def binary_threshold(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
under_thresh = 105
upper_thresh = 145
maxValue = 255
th, drop_back = cv2.threshold(grayed, under_thresh, maxValue, cv2.THRESH_BINARY)
th, clarify_born = cv2.threshold(grayed, upper_thresh, maxValue, cv2.THRESH_BINARY_INV)
merged = np.minimum(drop_back, clarify_born)
return merged
threshの値をどれぐらいにしたらいいかよく分からない場合は、ペイントツールなどで明るさを調べるとよいです。Windowsだと標準のペイントツールのスポイトで調べることができます。
なお、adaptiveThresholdを利用すると周辺のピクセルを見ながら適度な閾値を決めてくれるので、いったんはこれで試してみるのもいいと思います。詳細は下記のドキュメントを参照してください。
カラーによる閾値処理
cv2.inRangeを使用すれば、特定の色の部分を抜き出すことも可能です。以下では、背景の青色部分を検知してマスクをかけています。

def mask_blue(path):
img = cv2.imread(path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
blue_min = np.array([100, 170, 200], np.uint8)
blue_max = np.array([120, 180, 255], np.uint8)
blue_region = cv2.inRange(hsv, blue_min, blue_max)
white = np.full(img.shape, 255, dtype=img.dtype)
background = cv2.bitwise_and(white, white, mask=blue_region) # detected blue area becomes white
inv_mask = cv2.bitwise_not(blue_region) # make mask for not-blue area
extracted = cv2.bitwise_and(img, img, mask=inv_mask)
masked = cv2.add(extracted, background)
return masked
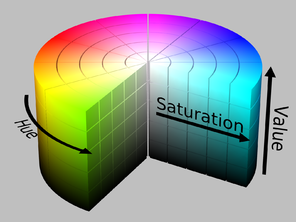
cv2.inRangeによって得られたblue_regionが指定したカラーの領域になっています。blue_regionはグレースケールで表現されており、発見された箇所ほど値が高くなっている(255=白に近い)のに注意してください。なお、cv2.inRangeを使用するに当たっては画像をHSV表現に変えておく必要があり、色の範囲の指定もそれに倣う必要があります。HSV表現とはなんぞや、というのは下図を見るとわかりやすいです。
ただ、OpenCVで指定するHSVの値には少し癖があるので、上記のようにペイントツールから値を推定するのがかなり難しいです。
| 一般的な値の範囲 | OpenCV | |
|---|---|---|
| H | 0 - 360 | 0 - 180 |
| S | 0 - 100 | 0 - 255 |
| V | 0 - 100 | 0 - 255 |
そのため、指定があまりうまくいかなようであれば実際に行列内の値を見た方が速いです。img[10:20, 10:20]という感じで所定の領域の行列値(カラー値)を切り出せるので、それで確認をするとピンポイントで指定が可能です(というか今回はペイントの値がどうにも役に立たなかったので、この手法で指定しました)。
あとは、blue_regionの領域をすべて白にするbackgroundと、blue_region以外の領域を抜き出したextractedを合算して画像を作成しています。bitwise_and/bitwise_notは、こうしたマスク処理を行うのに便利な関数になっています。
以上が、閾値処理についての解説となります。
平滑化(スムージング)
画像の輪郭がはっきりしない場合や背景が濃かったりする場合、閾値処理をかけても輪郭が取れなかったり背景が残ってしまったりします。下図の例では、足元の砂利が細かく残ってしまっていて、輪郭もギザギザしています。

Piping plover chick with band at two weeks
こうした場合は、フィルターを使ったスムージングを行うとよいです。フィルター処理は端的に言えば画像をぼやかす処理になりますが、画像をぼかすことで「ぼけてもはっきり見える点」のみを検知し、逆にぼやかしたら消えてしまうような点を無視することができます。
以下は、GaussianBlurを利用しガウシアンフィルタを適用してから(左図)、閾値処理をした例になります(右図)。
def blur(img):
filtered = cv2.GaussianBlur(img, (11, 11), 0)
return filtered

画像の細かいディティールは失われていますが、特徴的な箇所はまとまって残り、背景に多くあったノイズが消えてくれているのが分かると思います。OpenCV公式の以下のドキュメントには、GaussianBlur以外のフィルタについても書かれているので参照してみてください。
これ以外に画像の平滑化に使用される手法として、モルフォロジーがあります。これは、画像の膨張・収縮処理などを利用することでノイズを除去したり輪郭を強調したりする手法です。
以下は、モルフォロジーにおける代表的な手法のイメージを表したものです。

- Dialation: 境界領域を拡張する効果がある
- Erosion: 境界領域を侵食する効果がある
- Opening: Erosionと似ていて、境界を侵食するがErosionよりゆるやか。
- Closing: Dialationと似ていて、境界を拡張し背景を収縮させるがDialationよりゆるやか
理論的な詳細はここでは割愛しますが、フィルタの一種と思っていただいて差し支えありません。OpenCVでは上記のモルフォロジー処理ができるcv2.dilate、cv2.erode、そしてOpening/Closingを連続的に適用できる便利なcv2.morphologyExがあります。今回は、cv2.morphologyExを使って平滑化処理を行ってみます。
def morph(img):
kernel = np.ones((3, 3),np.uint8)
opened = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, iterations=2)
return opened

今回は背景の色が濃いためかCLOSEで領域を太らせると大変なことになったので、OPENにより領域間の距離がなるべく空くようにする方向で処理をかけてみました。ただ、まだノイズが残っているためフィルタと併用で処理をしています。
def morph_and_blur(img):
kernel = np.ones((3, 3),np.uint8)
m = cv2.GaussianBlur(img, (3, 3), 0)
m = cv2.morphologyEx(m, cv2.MORPH_OPEN, kernel, iterations=2)
m = cv2.GaussianBlur(m, (5, 5), 0)
return m

単純にフィルタをかけるよりは情報が残っているかな・・・という感じですね。また、Openingをかけたことにより以前は繋がっていた領域がしっかり独立するようになっているのが分かると思います。
モルフォロジーの処理については以下が詳しいので、参考にしてみてください。
- Simple and effective coin segmentation using Python and OpenCV
- Image Segmentation with Watershed Algorithm
実際やってみると、背景が濃い場合グレースケールにしてしまうとそこから領域をはっきりさせるのはかなり難しいです。そのため、背景にそれとわかる色がついているなら色でマスクをかけて、その後に処理をした方がしっかりと区分できると思います。
以上が前処理についての説明になります。ここから、前処理をした後の画像からいよいよ物体の検出を行っていきたいと思います。
物体検出
輪郭検出
ここまでで、前処理により認識したい物体を明確にすることができてきたと思うので、それを利用して輪郭の検出を行います。

OpenCVでは、cv2.findContoursを利用することで簡単に輪郭を検出することができます。
def detect_contour(path, min_size):
contoured = cv2.imread(path)
forcrop = cv2.imread(path)
# make binary image
birds = binary_threshold_for_birds(path)
birds = cv2.bitwise_not(birds)
# detect contour
im2, contours, hierarchy = cv2.findContours(birds, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
crops = []
# draw contour
for c in contours:
if cv2.contourArea(c) < min_size:
continue
# rectangle area
x, y, w, h = cv2.boundingRect(c)
x, y, w, h = padding_position(x, y, w, h, 5)
# crop the image
cropped = forcrop[y:(y + h), x:(x + w)]
cropped = resize_image(cropped, (210, 210))
crops.append(cropped)
# draw contour
cv2.drawContours(contoured, c, -1, (0, 0, 255), 3) # contour
cv2.rectangle(contoured, (x, y), (x + w, y + h), (0, 255, 0), 3) #rectangle contour
return contoured, crops
def padding_position(x, y, w, h, p):
return x - p, y - p, w + p * 2, h + p * 2
binary_threshold_for_birdsは、今回利用している鳥の画像を閾値処理するための関数です(=前処理)。これで出力されるのは先ほど紹介した背景白の画像なので、これを反転して領域検知に使います。わかりにくいですが、白黒の場合「白」の方が値が高いため(255)、輪郭検出を行う場合輪郭が白で描画されている画像を入力として与える必要があります。
※白黒のかなりはっきりした画像でないと輪郭が検出されないので注意してください
あとは、cv2.findContoursを実行するだけです。これで検出された輪郭は、cv2.drawContoursで簡単に画像上に描画することができます。また、cv2.boundingRectを利用することで輪郭が収まる矩形の座標を取得することができます。ただ、これはギリギリの接戦になっているので今回はpadding_positionでちょっと周りに余裕を持たせています。
cv2.findContoursについては、公式ドキュメントについても記載があるためご参照ください。
なお、自動でなくユーザーがかこってくる場合、グラフカットという手法を用いて囲われた領域の中の物体を検出することができます。詳細は触れませんが、アノテーション用のツールなどを作る場合は有用だと思うので、興味がある方は以下を参照してみてください。
Interactive Foreground Extraction using GrabCut Algorithm
輪郭の近似
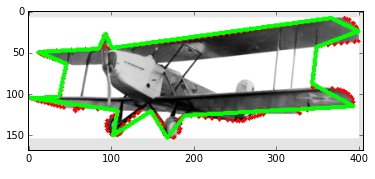
OpenCVには、検出した輪郭を近似する関数がいくつか用意されています。例えばapproxPolyDPは検出した輪郭を直線近似してくれるもので、輪郭が直線的な場合はこちらを使って切り出しを行うと良いです。以下は赤の点線が検出した輪郭で、緑線が直線近似したものになります。
def various_contours(path):
color = cv2.imread(path)
grayed = cv2.cvtColor(color, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(grayed, 218, 255, cv2.THRESH_BINARY)
inv = cv2.bitwise_not(binary)
_, contours, _ = cv2.findContours(inv, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) < 90:
continue
epsilon = 0.01 * cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, epsilon, True)
cv2.drawContours(color, c, -1, (0, 0, 255), 3)
cv2.drawContours(color, [approx], -1, (0, 255, 0), 3)
plt.imshow(cv2.cvtColor(color, cv2.COLOR_BGR2RGB))
various_contours(IMG_FOR_CONTOUR)
cv2.arcLengthは輪郭の長さで、これを使いepsilon、最低限の直線の長さを計算しています。これでどれだけ細かい直線でくくるのかを調整できます。
この他の関数についても、下記のチュートリアルに使い方と説明が記載されているので参考にしてみてください。
検出領域の切り出し
さて領域はわかりましたが、これを機械学習モデルへ適用するにはモデルが想定している所定のサイズに切り出す必要があります。これを行うため、今回resize_imageという関数を作成しました。
def resize_image(img, size):
# size is enough to img
img_size = img.shape[:2]
if img_size[0] > size[1] or img_size[1] > size[0]:
raise Exception("img is larger than size")
# centering
row = (size[1] - img_size[0]) // 2
col = (size[0] - img_size[1]) // 2
resized = np.zeros(list(size) + [img.shape[2]], dtype=np.uint8)
resized[row:(row + img.shape[0]), col:(col + img.shape[1])] = img
# filling
mask = np.full(size, 255, dtype=np.uint8)
mask[row:(row + img.shape[0]), col:(col + img.shape[1])] = 0
filled = cv2.inpaint(resized, mask, 3, cv2.INPAINT_TELEA)
return filled
この関数は、以下のステップで形成されています。
- resize: 所定のサイズのキャンバス(
resized)を用意(学習データの画像のサイズか、後から切り取るためちょっと大きめにする) - centering: 用意したキャンバスの中心に、切り出した画像をセット
- filling: セットした画像の周辺領域を、元の画像の情報を利用し埋める
OpenCVにもresize関数がありますが、これを使うと切り出した画像を無理やり所定のサイズに合わせるため、画像が歪んでしまいます。そのため今回は切り出した画像が収まるサイズのキャンバスを用意してその中心に切り出した画像を置き、周りを埋めるという手法を取っています。穴埋めに使っているcv2.inpaintは本来画像内の欠損を復元するための関数なのですが、今回は周りを埋めるのに使っています。
実際に切り出した画像は以下のようになっています。概ねきっちり補完ができていると思いますが、2枚目はくちばしの色がちょっと伸びてしまっています。こうした場合、paddingを調整し背景色だけで穴埋めされるよう、調整する必要があります。
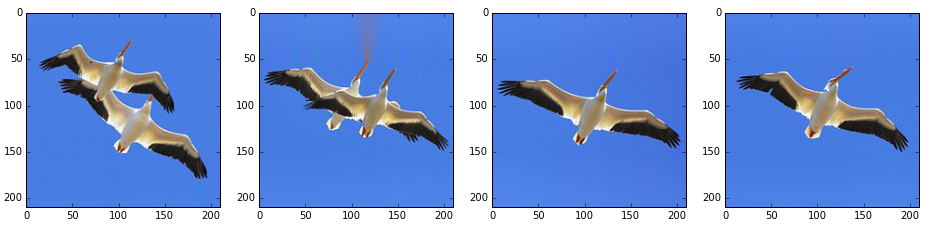
画像の位置揃え
画像上のどの位置に物体が移っているのかは、認識の際に重要なポイントとなります。最近利用されているCNNでは畳み込みにより多少ずれていてもしっかりやってくれますが、補正をしておくと精度がぐっと上がります。そのため、ここでは切り出した後の画像の位置補正について説明します。
下図は、画像の位置揃えを行ってみた例です。一段目がベースの画像で、二段目以降が一段目の画像に位置を合わせるための補正をかけたものです(左側が補正前、右側が補正後)。

画像出典: image 1, image 2, image 3
補正をかけた後は、鳥の位置がほぼそろっていると思います。これは、下記サイトを参考にfindTransformECCを利用して補正を行っています。
Image Alignment (ECC) in OpenCV ( C++ / Python )
def align(base_img, target_img, warp_mode=cv2.MOTION_TRANSLATION, number_of_iterations=5000, termination_eps=1e-10):
base_gray = cv2.cvtColor(base_img, cv2.COLOR_BGR2GRAY)
target_gray = cv2.cvtColor(target_img, cv2.COLOR_BGR2GRAY)
# prepare transformation matrix
if warp_mode == cv2.MOTION_HOMOGRAPHY:
warp_matrix = np.eye(3, 3, dtype=np.float32)
else :
warp_matrix = np.eye(2, 3, dtype=np.float32)
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, number_of_iterations, termination_eps)
sz = base_img.shape
# estimate transformation
try:
(cc, warp_matrix) = cv2.findTransformECC(base_gray, target_gray, warp_matrix, warp_mode, criteria)
# execute transform
if warp_mode == cv2.MOTION_HOMOGRAPHY :
# Use warpPerspective for Homography
aligned = cv2.warpPerspective(target_img, warp_matrix, (sz[1], sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
else :
# Use warpAffine for Translation, Euclidean and Affine
aligned = cv2.warpAffine(target_img, warp_matrix, (sz[1],sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
return aligned
except Exception as ex:
print("can not align the image")
return target_img
findTransformECCは、端的に言えば2つの画像の似ている点を探して、どんな移動が行われたのかの推定結果をwarp_matrixに入れてくれる関数です。元は動画などの連続するフレーム上で、どのような動きがあったか解析するためのものなのでかなり同じ画像でないと位置がそろわなかったりします。上記も何気なく揃っているように見えますが、相関がとれる写真を選ぶのが大変でした(相関がない場合、収束しない旨の例外が出る)。。。
顔など全ての画像に共通する特徴点(目・鼻・口etc)が存在する場合は、各特徴点の位置を元に変換をかけることもできます。estimateRigidTransformは、このために使えます。
def face_align(base, base_position, target, target_position):
sz = base.shape
fsize = min(len(base_position), len(target_position)) # adjust feature size
tform = cv2.estimateRigidTransform(target_position[:fsize], base_position[:fsize], False)
aligned = cv2.warpAffine(target, tform, (sz[1], sz[0]))
return aligned
写真によっては目が検出できない、といったケースがあるため上記では検出特徴量が小さい方に合わせて変換を行っています(ただし、この場合特徴量を入れる順番をそろえないといけない点に注意して下さい)。

変換後は、顔の位置がしっかりそろっているのが分かると思います。以下にも顔の位置揃えについて詳細な紹介があるので、参考にしてみてください。
Average Face : OpenCV ( C++ / Python ) Tutorial
物体認識
上記では輪郭の検出を自力で行いましたが、OpenCVには顔や体などよく検出を行う物体について学習済みモデルが用意されており、これを利用することで物体認識が行えます。この学習済みのモデルファイルをCascade Classifierといい、自前で作成することも可能です。公開されているものもいくつかあるので、興味がある方は下記でまとめてくださっているので参考にしてみてください。
Cascade Classifierについては、pipでインストールした場合(virtual environment folder)\Library\etc\haarcascadesの中に入ってます(Windows/minicondaの場合。環境によって差異があると思います)。目的に合いそうなものがあるか、いろいろ試してみるとよいでしょう。今回は、以下の公式のチュートリアルに倣い顔の検知を行ってみたいと思います。
Face Detection using Haar Cascades
実際に検出を行ってみた結果が以下になります。髪で隠れてしまっているせいか、右目の検知に失敗していますが。。。

コードはほぼチュートリアル通りとなります。Cascade Fileの場所は上述の通り環境によって異なるため注意してください(上手くパスが通っていないと、error: (-215) !empty() in functionといったエラーが出ます)。
def face_detection(path):
face_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_eye.xml")
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(grayed, 1.3, 5)
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = grayed[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(roi_color, (ex,ey), (ex + ew, ey + eh), (0, 255, 0), 2)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
face_detection(IMG_FACE)
cv2.CascadeClassifierでファイルを読み込んでClassifierを作成し、detectMultiScaleで検出を行う、というのが基本の流れになります。今回はグレースケール化しかしていませんが、上述の閾値処理などをおこなうことでよりしっかりとした検出ができると思います。また、検出した箇所の切り出しについては前項の「検出領域の切り出し」を参考にしてください。
なお、顔が傾いていたりするとうまく検出されません。これについては、目/口を先に検出して傾きを割り出すアプローチか、単純に画像を徐々に回転させて検知を試みるかの2つの方法があります。前者の方が計算量が少ないが面倒、後者の方が簡単だが計算量が多い、とトレードオフになります。下記は画像を回転させながら検知する手法について詳細に書かれているので、参考にしてみてください。
学習の準備
ここまでで、画像から目的の物体が写った画像を切り出すことができました。あとは、集めた画像を機械学習モデルに投入するだけです。
ただ、学習モデルに画像を投入する際にはいろいろな前処理が必要です。この点については、以下にまとめてあります。
Convolutional Neural Networkを実装する/データの前処理
ポイントを抜粋すると、以下のような処理が必要です。
- 行列変換: 学習モデルが想定している行列形式(大抵はK(深さ=色) x H(高さ) x W(幅))に変換する
- 深さの調整: 学習モデルが想定しているカラーチャネルに変換する(グレースケールなのか、RGBなのか)
- 画像データの正規化: 全画像を平均した平均画像を作っておき、画像を正規化する
- スケーリング: 0~255の値幅を、0~1に変換
説明は以上となります。上手くOpenCVを利用して、色々な学習をさせてみてください。