「フランス」-「パリ」+「東京」=「日本」
こんな単語同士の演算ができる、と話題になったのがGoogleが発表したWord2Vecです。これは端的に言えば単語を数値で表現する技術で、これにより単語同士の「近さ」を測ったり、上記のような演算をすることが可能になります。この、単語を数値表現にしたものを分散表現と呼びます。
今回紹介するFacebookの発表したfastTextはこのWord2Vecの延長線上にあるもので、より精度が高い表現を、高速に学習できます。本稿ではその仕組みと日本語文書に対しての適用方法について解説していきます。
fastTextの仕組み
fastTextでは、Word2Vecとその類型のモデルでそれまで考慮されていなかった、「活用形」をまとめられるようなモデルになっています。具体的には、goとgoes、そしてgoing、これらは全て「go」ですが、字面的にはすべて異なるのでこれまでの手法では別々の単語として扱われてしまいます。そこで、単語を構成要素に分解したもの(イメージ的には、goesなら「go」「es」)を考慮することで、字面の近しい単語同士により意味のまとまりをもたせるという手法を提案しています(Subword model)。
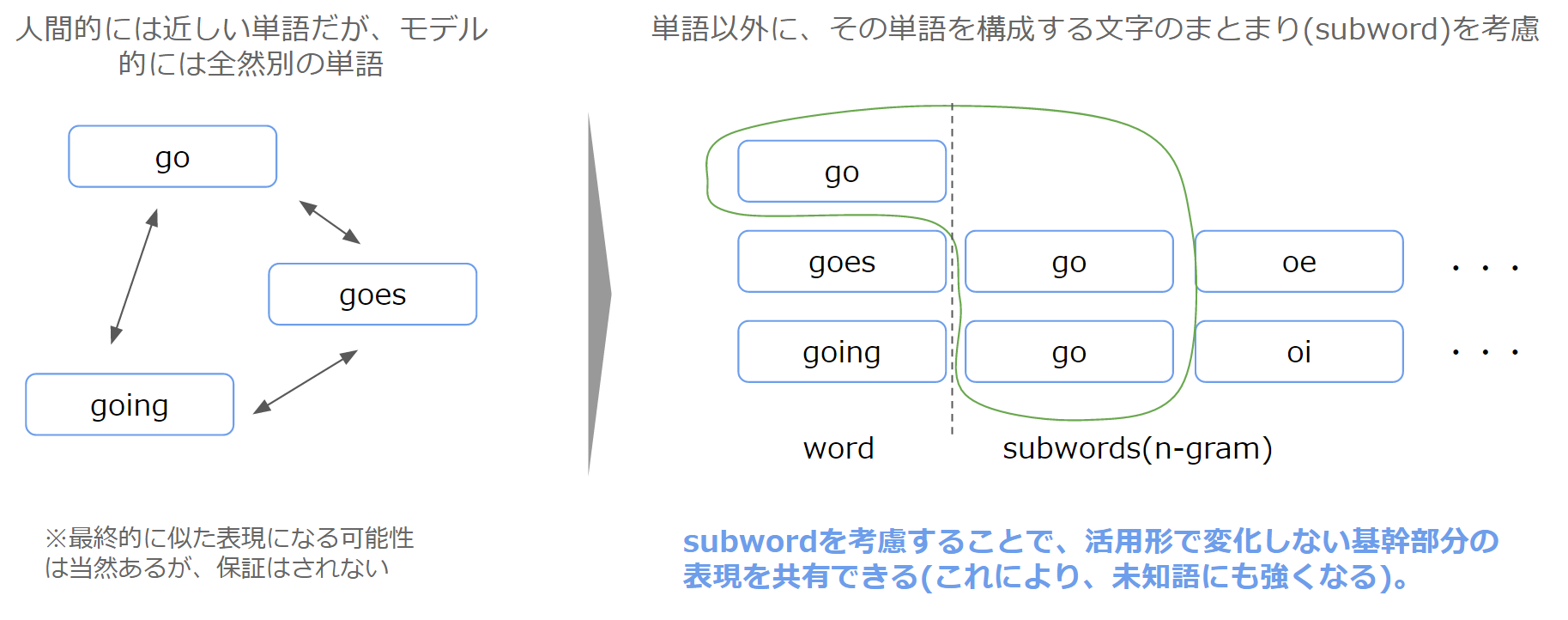
※なお、単語と構成要素は区別されるため、例えばas you等で使われる単語としての「as」と、pasteの単語の構成要素としての「as」は区別されます。
単語の構成要素については、論文中では3文字以上6文字未満のものを利用し、3文字未満のものは前置接・後置接として扱っています。利用する単語の構成要素は、多ければ多いほど組み合わせのバリエーションができるため表現力が向上しますが、その分計算に時間がかかることになります。これはトレードオフの関係になるのですが、論文中では200万に制限しています。詳細が知りたい方は、論文のほうをご参照ください。
また、fastTextではこの手法に基づく分散表現を利用した文書分類の機能も実装されています(論文は以下)。
以上が、fastTextの仕組みになります。ここからは、実際にfastTextを使うための手順を紹介していきます。
fastTextの使い方
fastTextの使い方自体は非常にシンプルです。
./fasttext skipgram -input data.txt -output model
公式ページにもある通りですが、文書データであるdata.txtを渡したらmodelができる、というこれ以上ないくらいの簡単さです。ただ、英語と異なり日本語は単語がスペースで区切られていないため、分かち書きという単語を切り出す処理をする必要があります。そのための手順を、以下で説明していきます。
今回の作業に使うためのリポジトリを以下に用意しています。こちらをcloneして手順通りに進めていけばOKなようにしていますので、ぜひご活用いただければと思います。
icoxfog417/fastTextJapaneseTutorial
(Starを頂けると励みになりますm(_ _)m)
事前準備
今回はPythonを使って処理をしていくため、Pythonの環境が必要となります。また、日本語を分かち書きするためにMeCabを使うため、MeCabのインストールが必要です。
WindowsではMeCab周りで苦労することが多いので、Windows10の場合bash on Windowsを利用しUbuntu環境で作業したほうが楽です。
1.学習に使用する文書を用意する
まず、学習に使用する文書を用意します(自然言語界隈では、これをコーパスと呼びます)。一番身近なものはWikipediaでしょう。今回は日本語Wikipediaのダンプデータを使用しました。
上記のページ内にある「ウィキペディア日本語版のダンプ」からダンプの保管場所に行き、最新の日付のデータを取得します。いろんな種類がありますが、概要のみ(jawiki-xxxxxxxx-abstract.xml)、記事全文(jawiki-xxxxxxxx-pages-articles.xml.bz2)などが有用です。
もちろん、新聞記事やブログ記事など、ほかの文書でも構いません。分散表現の用途に合わせたコーパスを用意したほうがよいでしょう。Wikipediaはあくまで辞書的な内容なので、例えば「ディズニーランド」の項目を見てもその歴史などが事細かに書いてあり、決して「楽しい」といったキーワードやアトラクションの名前などは出てきません。分散表現は、周辺に出現する単語によってその性質が決まるため、「ディズニーランド」といったときに楽しい・有名といった要素が含まれていたほうがいいのか、ロサンゼルス・1950年代といった要素が含まれていたほうがいいのかによって、学習に利用すべきコーパスは違ってきます。
2.テキストを抽出する
Wikipediaを利用する場合、そのダンプデータはXMLとなっているのでここから純粋なテキストデータを抽出する必要があります。これを行ってくれるツールは様々なものがありますが、今回はPython製のWikipedia Extractorを使用しました。
以下のような感じで実行可能です。-bオプションで500Mごとにファイルを区切っています。
python wikiextractor/WikiExtractor.py -b 500M -o (出力先フォルダ) jawiki-xxxxxxxx-pages-articles-multistream.xml.bz2
なお、Wikipedia Extractorはファイル形式がbz2であるファイルを想定しており、またabstractのファイルには対応していません。abstractのファイルで試してみたい方は、リポジトリ内のparser.pyで処理できるようにしているため、そちらを利用してください。
最終的には、抽出されたテキストデータを1つのテキストファイルにまとめます。これでテキストの抽出は完了です。
3.テキストを単語に分ける(分かち書きする)
さて、ここからが本題です。日本語は英語のようにスペースで単語が区切れていないため、分かち書きという処理をして単語ごとに切り出して行く必要があります。
この作業に、MeCabを利用します。今回は単純に分かち書きをするだけで形態素の情報は必要ないので、以下のコマンドで処理します。
mecab (対象テキストファイル) -O wakati -o (出力先ファイル)
これで単語をスペースで区切ったファイルができました。
なお、MeCabは分かち書きをするために単語の辞書を持っています。この辞書の語彙が増えるほど分かち書きの精度を上げることができ、mecab-neologdを利用するとより現代的な単語も認識して分かち書きすることできるので、必要に応じ活用してください。
※英単語ではgoとgoneは同じ1単語ですが、日本語では「行く」と「行った」は、「行く」は動詞、「行った」は「行っ(動詞)」+「た(助詞)」になり、単語が分かれることになります。fastTextの性質を考慮するとこのような動詞+助詞が分かれるケースは結合したほうがいい可能性がありますが、処理が煩雑になるため今回は普通に分けてしまっています。
4.fastTextで学習する
こうして英語と同様に単語ごとに区切られたファイルが手に入ったため、あとはfastTextを実行するだけです。fastTextのリポジトリをcloneしてきて、ドキュメントにある通りmakeによりビルドしてください。
※Windows上でのビルドは結構難ありっぽいので、事前準備の通りbash on Windowsを使うか、そうでない場合はmingwなどを使って頑張る必要があります。
設定パラメーターは各種ありますが、論文を参考にすると、扱うデータセットにより単語の数値表現のサイズ(ベクトルの次元)は以下のようになっています(※tokenが何の単位なのかは言及がなかったのですが、おそらく単語カウントと思われます)。
- small(50M tokens): 100
- mediam(200M tokens) :200
- full:300
要は、小さいデータセットなら小さい次元、ということです。Wikipedia全件のような場合はfullの300次元に相当するため、以下のように処理します。
./fasttext skipgram -input (分かち書きしたファイル) -output model -dim 300
Word2Vecの学習と同等のパラメーターで行う場合は、以下のようになります(パラメーター設定などは、こちらに詳しいです)。
./fasttext skipgram -input (分かち書きしたファイル) -output model -dim 200 -neg 25 -ws 8
(Issueにも上がっていますが、パラメーターで結構変わるらしいです。epoch、mincountなど。。。)
学習が完了すると、-outputで指定したファイル名について、.binと.vecの二種類のファイルが作成されます。これらが学習された分散表現を収めたファイルになります。
特に.vecの方は、単語と分散表現がペアになった単純なテキストファイルなので、Python以外の言語でもこれを読み取って利用することができると思います。
ただ、Wikipeida全件のような場合はデータサイズが大きすぎてmodelのファイルを読み込もうとするとMemoryErrorで飛ぶこともままあるほか、エンコードの問題が発生するケースがあります(というか発生したのですが)。そのような場合は、一旦単語の辞書を作り(「朝」->11など、単語をIDに変換する辞書を作る)、テキストファイルを単語IDの列に変換するなどして対応します。
5.fastTextを活用する
では、実際にfastTextを利用してみましょう。一応Pythonのインタフェースはあるのですが、上述の通りファイル構成が単純なので使うまでもないです。リポジトリの中にeval.pyを用意しているので、そちらを使うことで、似ている単語を検索できます。
python eval.py EXILE
結果は・・・
EXILE, 0.9999999999999999
エグザイル, 0.8503456049215405
ATSUSHI, 0.8344220054003253
なるほど、似ているものがきちんととれています(数値は、コサイン類似度を示しています。1に近いほど似ていて、0に近いほど似ていないことになります)。
逆に、似ていない単語も見てみます。
python eval.py EXILE --negative
結果は・・・・
主権, 0.011989817895453175
偉大, 0.03867233333573319
Hospital, 0.10808885165592982
圧, 0.11396957694584102
電子掲示板, 0.12102514551120924
シーア派, 0.13388425615685776
フィリピン語, 0.134102069272474
つながる, 0.13871080016061785
カンヌ, 0.1560228702600865
井関, 0.16740051927385632
SaaS, 0.1938341440200136
開星中学校・高等学校, 0.19798593808666984
博物画, 0.23079469060502433
蝶, 0.23615273153248512
P5, 0.2795962625371914
AH, 0.2919494095090802
EXILEとシーア派は全く似ていない。確かにその通りですね(???)。
このような感じで、簡単に活用することができます。ぜひ皆さんも試してみてください。