はじめに
Chainerを使ってみたい。でもよくわからない。
そうだ、多層パーセプトロンによるXORの学習から初めてみよう。
※Chainerを使える環境が整っている前提で本記事は書かれています。
本記事で使用するコード
環境
- python 2.7系
- chainer 1.6.2.1
学習データ
# Prepare dataset
source = [[0, 0], [1, 0], [0, 1], [1, 1]]
target = [[0], [1], [1], [0]]
dataset = {}
dataset['source'] = np.array(source, dtype=np.float32)
dataset['target'] = np.array(target, dtype=np.float32)
モデルの定義
今回利用するモデルは、2入力、1出力です。
N = len(source) # train data size
in_units = 2 # 入力層のユニット数
n_units = 2 # 隠れ層のユニット数
out_units = 1 # 出力層のユニット数
# モデルの定義
model = chainer.Chain(l1=L.Linear(in_units, n_units),
l2=L.Linear(n_units , out_units))
順伝搬
def forward(x, t):
h1 = F.sigmoid(model.l1(x))
return model.l2(h1)
学習
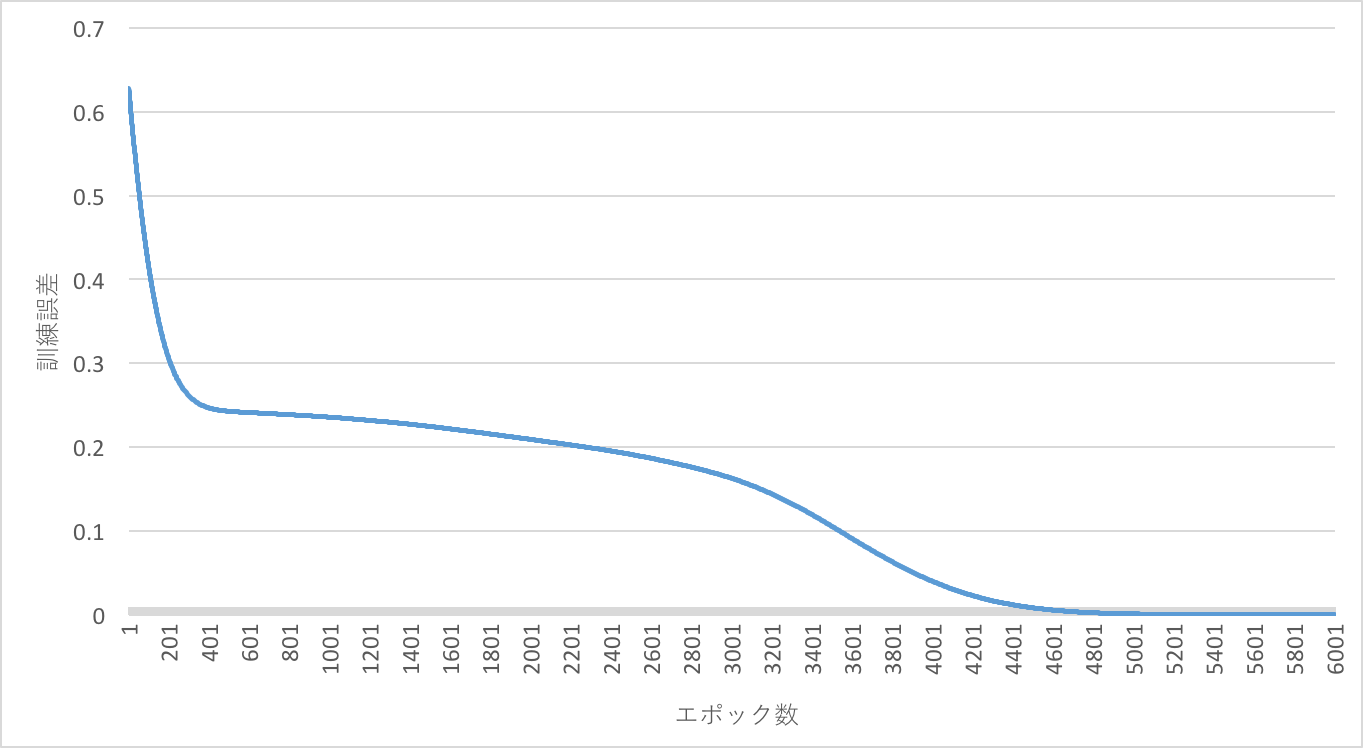
訓練誤差が0.00001未満、または、epochがn_epoch以上になるまで繰り返します。
# Setup optimizer
optimizer = optimizers.Adam()
optimizer.setup(model)
# Learning loop
loss_val = 100
epoch = 0
while loss_val > 1e-5:
# training
x = chainer.Variable(xp.asarray(dataset['source'])) #source
t = chainer.Variable(xp.asarray(dataset['target'])) #target
model.zerograds() # 勾配をゼロ初期化
y = forward(x, t) # 順伝搬
loss = F.mean_squared_error(y, t) #平均二乗誤差
loss.backward() # 誤差逆伝播
optimizer.update() # 最適化
# 途中結果を表示
if epoch % 1000 == 0:
#誤差と正解率を計算
loss_val = loss.data
print 'epoch:', epoch
print 'x:\n', x.data
print 't:\n', t.data
print 'y:\n', y.data
print('train mean loss={}'.format(loss_val)) # 訓練誤差, 正解率
print ' - - - - - - - - - '
# n_epoch以上になると終了
if epoch >= n_epoch:
break
epoch += 1
# modelとoptimizerを保存
print 'save the model'
serializers.save_npz('xor_mlp.model', model)
print 'save the optimizer'
serializers.save_npz('xor_mlp.state', optimizer)
実行結果
回帰問題として学習しています。
予測する時は、0.5以上なら1、0.5未満なら0、のように閾値を決める必要があります。
$ python train_xor.py --gpu 1
epoch: 0
x:
[[ 0. 0.]
[ 1. 0.]
[ 0. 1.]
[ 1. 1.]]
t:
[[ 0.]
[ 1.]
[ 1.]
[ 0.]]
y:
[[-0.62479508] # 0に近づいて欲しい
[-0.85900736] # 1に近づいて欲しい
[-0.4117983 ] # 1に近づいて欲しい
[-0.62129647]] # 0に近づいて欲しい
train mean loss=1.55636525154 # 訓練誤差 (小さくなってほしい)
- - - - - - - - -
epoch: 1000
x:
[[ 0. 0.]
[ 1. 0.]
[ 0. 1.]
[ 1. 1.]]
t:
[[ 0.]
[ 1.]
[ 1.]
[ 0.]]
y:
[[ 0.39130747]
[ 0.40636665]
[ 0.50217605]
[ 0.52426183]]
train mean loss=0.257050335407
- - - - - - - - -
...
- - - - - - - - -
epoch: 8000
x:
[[ 0. 0.]
[ 1. 0.]
[ 0. 1.]
[ 1. 1.]]
t:
[[ 0.]
[ 1.]
[ 1.]
[ 0.]]
y:
[[ 0.00557911]
[ 0.98262894]
[ 0.98446763]
[ 0.02371788]]
train mean loss=0.000284168170765
- - - - - - - - -
epoch: 9000
x:
[[ 0. 0.]
[ 1. 0.]
[ 0. 1.]
[ 1. 1.]]
t:
[[ 0.]
[ 1.]
[ 1.]
[ 0.]]
y:
[[ 5.99622726e-05] # 0に近づいた
[ 9.99812365e-01] # 1に近づいた
[ 9.99832511e-01] # 1に近づいた
[ 2.56299973e-04]] # 0に近づいた
train mean loss=3.31361960093e-08
- - - - - - - - -
save the model
save the optimizer