演算の並列実行でCPUコアを使い切るかどうかを測定 を投稿した時に、tatsuya6502 さん に、
まず、Range from..to-1 は、プログラムの簡潔さに大きく貢献してますが、その分、Enum 内部の処理が複雑になっていると思います(ポイント1)。
というコメントを頂きました。実際どのぐらい差があるのか気になったので、簡単に比較してみました。ソースコードの差異は Enum.map/2 に渡すリストを Range と :lists.seq/2 にしただけです。
Enum.map(1 .. 1_000_000, fn(i) -> i end)
Enum.map(:lists.seq(1, 1_000_000), fn(i) -> i end)
| 数 | 時間(Range) | 時間(:lists.seq) |
|---|---|---|
| 1,000,000 | 0.84 | 0.87 |
| 10,000,000 | 3.1 | 2.6 |
| 20,000,000 | 6.1 | 4.4 |
| 30,000,000 | 7.6 | 9.2 |
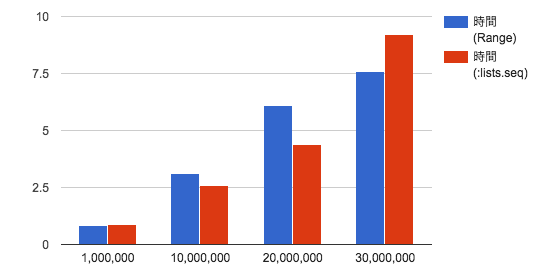
30,000,000 まで来ると、:lists.seq/2 の方はメモリを使いきって swap が出るようになってしまいました。Range の方も、35,000,000 あたりでメモリを使いきりました。
Slogan: eheap_alloc: Cannot allocate 1581921408 bytes of memory (of type "heap").
System version: Erlang/OTP 18 [erts-7.2.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
およそ3GBの空き容量を30,000,000で割ると100bytesなので、まぁ使い果たしてもおかしくありません。
ここで Range がどのように実装されているのか気になったので、Elixir 1.1.1 の Range の実装を見てみました。
@moduledoc に明記されていますが、struct として実装されているんですね。なので、生成(foo = 1..100 とか)は struct を作るだけなのでコストはまったく無いに等しい一方で、Enum.map/2 とかに渡した場合は内部的には reduce() で再帰処理するため、少しコスト高になってしまうと。
ただ、(ソースを見たわけじゃありませんが)Erlangの方の :lists.seq/2 は呼ばれた時点でメモリ確保をするため、一度に大量に確保するとメモリを使いきるという動作は納得できますが、Range の reduce() はアキュムレータを指定して再帰処理しているのに、なぜメモリを使い切るんでしょうか?
・・・ Enum.map の実装を見て謎が解けました。わかってしまえば単純で、map 自体が再帰処理して Range.reduce() を呼びまくるからですね。そりゃそうだ。
def map(enumerable, fun)
def map([], _fun) do
[]
end
def map([head | tail], fun) do
[fun.(head) | map(tail, fun)]
end
def map(collection, fun) do
reduce(collection, [], R.map(fun)) |> :lists.reverse
end
Stream 版
せっかくなので Stream.map/2 でも試してみました。
ソースコード
f = fn (i) -> i end
Enum.map(1 .. 10_000_000, fn(i) -> i end)
|> f.()
f = fn (i) -> i end
Stream.map(1 .. 10_000_000, fn(i) -> i end)
|> f.()
| 数 | 時間(Enum) | 時間(Stream) |
|---|---|---|
| 1,000,000 | 0.9 | 0.84 |
| 10,000,000 | 2.9 | 0.7 |
| 20,000,000 | 6.1 | 0.69 |
| 30,000,000 | 8.3 | 0.6 |
| 100,000,000 | 56.0 | 0.6 |
| 1,000,000,000 | - | 0.5 |
| 10,000,000,000 | - | 0.6 |
| 10,000,000,000 | - | 0.7 |
| 100,000,000,000 | - | 0.6 |
Stream.map/2 の速度がO(1)なのは、何の演算もしてないからなんでしょうね。ちなみに 100000000000000000000000000000000000000000000000000000000000 を指定しても、0.7秒でした。