read.table() でファイルをデータフレームに読み込むとき、ヘッダーに R の変数として使用できない文字があると . に自動的に変換されます。
例えば、下記のようなデータがあったとき、
| Name | Value(1hours) | Value(2hours) | Value(3hours) | #ofCount |
|---|---|---|---|---|
| Yamada | 4.2 | 5.3 | 6.4 | 3 |
| Tanaka | 4.5 | 2.3 | 4.3 | 4 |
| Sato | 2.3 | 5.6 | 4.2 | 2 |
次のようなコードでデータフレームに読み込むと、
data <- read.table(filepath, header=TRUE, comment.char="")
print(data)
結果は下記のようになります。
Name Value.1hours. Value.2hours. Value.3hours. X.ofCount
1 Yamada 4.2 5.3 6.4 3
2 Tanaka 4.5 2.3 4.3 4
3 Sato 2.3 5.6 4.2 2
ヘッダーに注目して下さい。
( および ) は . に変換されます。#ofCount は X.ofCount というわけのわからないものになっています。これは R の変数が数字や記号から始まることができないためです。
これの何が問題かというと、このデータをそのまま作図関数に渡してしまうと、X.ofCount などがそのままグラフに描画されてしまいます。
pairs(data[-1])
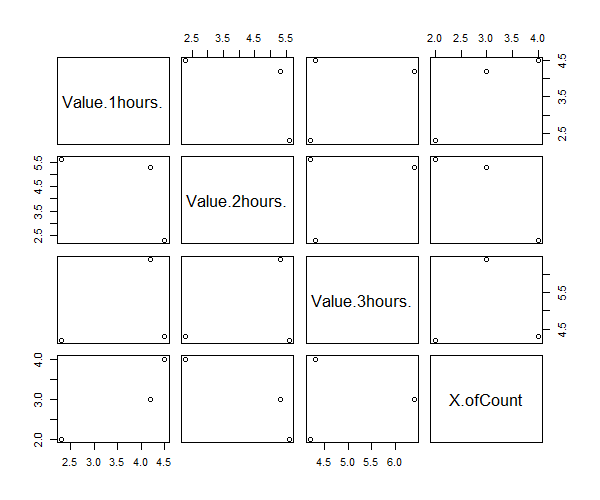
これを防ぐために read.table() には check.names という便利なパラメータがあります。
規定値は TRUE ですが、これを FALSE にすると、ヘッダーに対する変換を行わないようになります。
data <- read.table(filepath, header=TRUE, comment.char="", check.names=FALSE)
print(data)
Name Value(1hours) Value(2hours) Value(3hours) #ofCount
1 Yamada 4.2 5.3 6.4 3
2 Tanaka 4.5 2.3 4.3 4
3 Sato 2.3 5.6 4.2 2
pairs(data[-1])
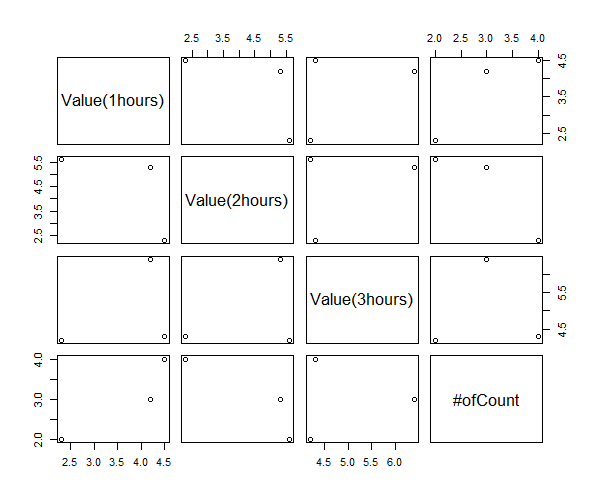
おー、便利だ。
ただし、check.names=FALSE にすると、データフレームの便利な記法 $ が使えなくなります。
print(data$Value(1hours)) # Error!
エラー: 予想外の シンボル です ( "print(data$Value(1hours" の)
これは R の構文に違反しているためであり、まさにこのエラーが出ないように check.names=TRUE がデフォルトになっているのです。
しかし、これを回避する方法があります。
バッククオートで変数を囲むのです。
print(data$`Value(1hours)`) # OK
[1] 4.2 4.5 2.3
モデル式についても、同様に記述できます。
lm(`Value(3hours)` ~ `Value(1hours)` + `Value(2hours)`, data=data)
Call:
lm(formula = `Value(3hours)` ~ `Value(1hours)` + `Value(2hours)`,
data = data)
Coefficients:
(Intercept) `Value(1hours)` `Value(2hours)`
-3.4059 1.2888 0.8289
使ってみると意外に便利です。
以上です。