DeepLearningや深層学習など、CUDAやGPGPUなどの需要が
急激に高まっている。
一方でnVidiaやATI(AMD)は元々3Dグラフィックスをベースに
CUDAやGPGPUを発展させてきた。
決して、DeepLearningなどの汎用演算を想定してCUDAやGPGPUが
設計されきたわけではない。
ラスタライザやShaderコアなどで実装されている浮動小数演算器を、
より汎用的な演算に解放しよう努力はしているが
ラスタライズ処理で必須とされる回路規模のインパクトは今日現時点でも軽くはない。


では、スパコン業界ではどうだろうか?
時間レンタルでスパコンにTensorFlowを流したらどうだろうか?
昨今のスパコンは、米国製、中国製 問わず
Intel®Xeon®やnVidiaなどのハイエンドCPU/GPUを
コア・パーツとして力技で組み上げられていた。
しかし、その力技にも限界が見え始めてきた。
そんな流れを断ち切るかのように
完全に独自アーキのmany-coreベースのCPU SW26010 で
TOP500で1位
Green500で3位
にランクインしたことは前回の記事
Intelビビってる 世界最速スパコン神威太湖之光
http://qiita.com/homhom44/items/f91bb8962a40286171b0
で紹介した。
前回は、神威太湖之光のH/W基本構成と
OpenACCを基軸とするS/W構成に関して説明した。
その応用範囲はとても広く
地球大気シミュレーションから深層学習(deep learning) にまで及ぶ。
今回は、RayTraceの演算を通して、具体的にどのようにmany−coreを制御するのか?連携させるのか?
といったあたりを説明する。

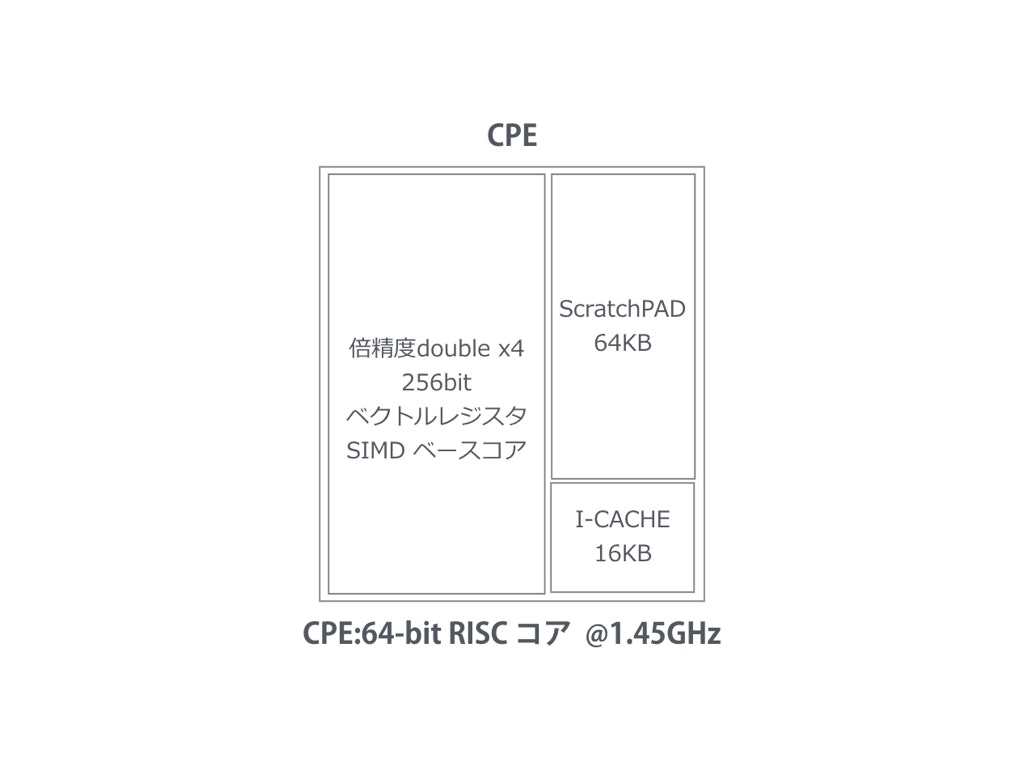


RayTraceに限らず、解こうとする問題を適切な粒度にまで細かく分割して
各ノード/コアに並行処理を進めるというところまでは基本。



MPEは管理職。会社でいえば部長・課長といったポジション。
部下であるCPEに対して適切な指示を出すだけでもかなりの仕事/演算量になる。

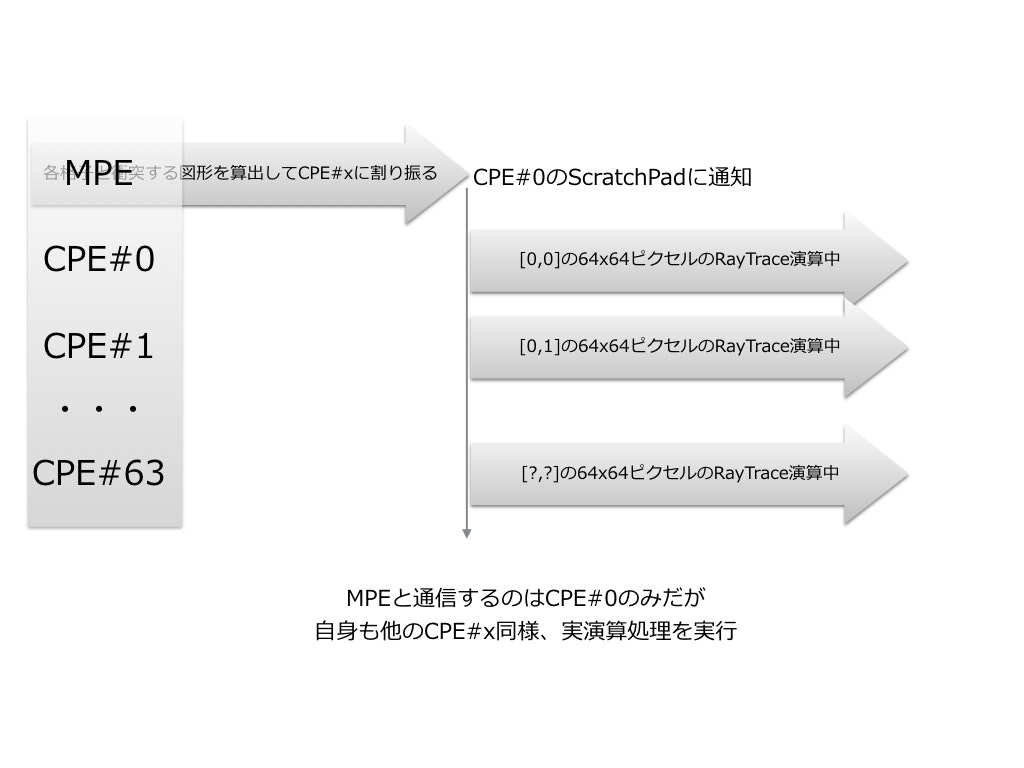
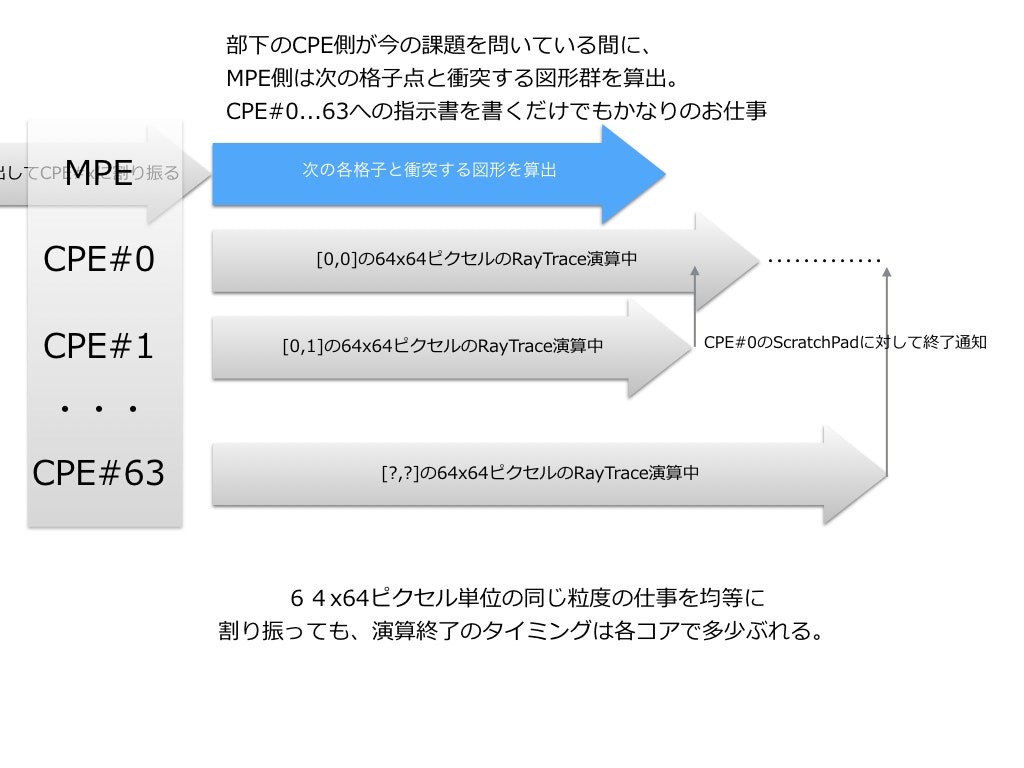
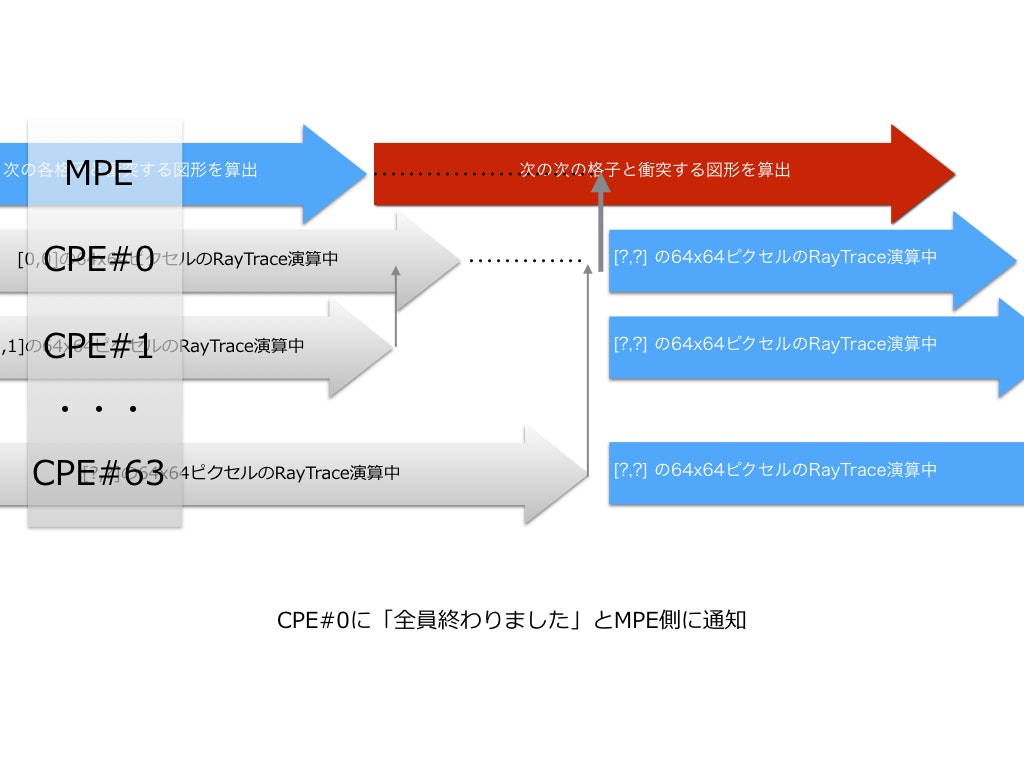
MPEは部下であるCPEがレンダリング画像を生成している間、
次の指示書を書いている。

SW26010が many-core で成功したポイントはいろいろ挙げられる。
-
コア間通信を最低限に
-
MPEと通信するのはCPE#0のみ。各CPE#xは#0とのみ通信。
-
通信の媒体はCPEのScratchPadのみ
上記では便宜上、「通信」と記述したが実際にはScratchPad経由でのアクセスのため
単なるSRAM R/Wに過ぎない。
SRAMの入力ポート数、出力ポート数は不明だが、DMACが存在しているのでそれぞれ最低でもx2portはあると思われる。
また通知に割り込みを使っていないことも特徴的だ。
CPE側は割り込みコントローラすら削り落としている様子だ。
IntelですらLarrabee®でmany−coreアーキテクチャに挫折している。
どこで差がついたのか?
Larrabee®が持っていて、SW26010/CPEでは思い切って削ぎ落としたブロックがある
- 2次キャッシュ
- 各コア間 メモリコントローラ
- テクスチャフィルタ(グラフィックス用途も想定しているため)
- ハイスピード・ループ・コントローラ
SW26010/CPE陣営が不要なものを見極めて削ぎ落とした判断が
結果的にmany-core(低消費電力)の成功に繋がったと思われる。
スパコンは個人ではなかなか手の届かない所にある。
しかしSW26010自体は枯れた40nmプロセスで製造されたCPUに過ぎない。
この思想を受け継いだCPUカードがPCIe 3.0 で接続できれば
GPGPU以上の汎用性を個人が入手できる可能性がある。
その時、DeepLearningやTensorFlowなどの分野で開花するのではないだろうか。
グラフィックスは飽和点に達してるが、人工知能系では2016年現時点での計算資源では
全く足りないのだ。