最近バズっている「ハイパーコンバージド・インフラストラクチャー」ですが、VCE(EMC子会社)のVxRailを試す機会がありましたので、簡単にレポートしたいと思います。
なお、試用機はSSD・HDDハイブリッドタイプで、CPUはXeon E5-2600v2シリーズでしたので、現行機の1世代前です(といっても、Xeonの最新ラインアップはE5-2600v4ですので、現行機もそのうち世代交代すると思います)。
ハードウェア
事情により写真はありません。というより、データセンターのラックに直接設置したので、写真を撮ることができませんでした。
前面は、フロントベゼルをつけなければ「ちょっとドライブ数の多い2Uの汎用IAサーバ」という印象です。とりたてて変わったところはありません。強いて挙げれば、電源インジケータとIDランプ用のボタン(押すと背面の対象ノードの青色LEDが点灯する)が、左右に4ノード分存在することぐらいです。
背面を見ると、4つのノードに分かれていることが分かります。
各ノードに、10GのLAN I/Fが2種類(RJ-45とSFP+)×2、1Gの管理用I/F、VGA端子等が付いています。
といっても、2Uで4ノードの筐体はハイパーコンバージドでなくても存在するので、「普通のIAサーバ」であることには代わりがありません。
vSphere Web Client
見た目は完全に普通のWeb Clientです。VSANが組み込まれています。
なお、試用機には、NSXも組み込まれていました。
vSphere Web Client以外にも、VxRailの管理ツールとExtension、vRealize Log Insightなどがセットになっていますが、管理ツールの使い勝手は今一つ、という印象でした。多分、vSphere Web Clientでほぼ用が足りるので、(自分は)ほとんど使わないと思います。
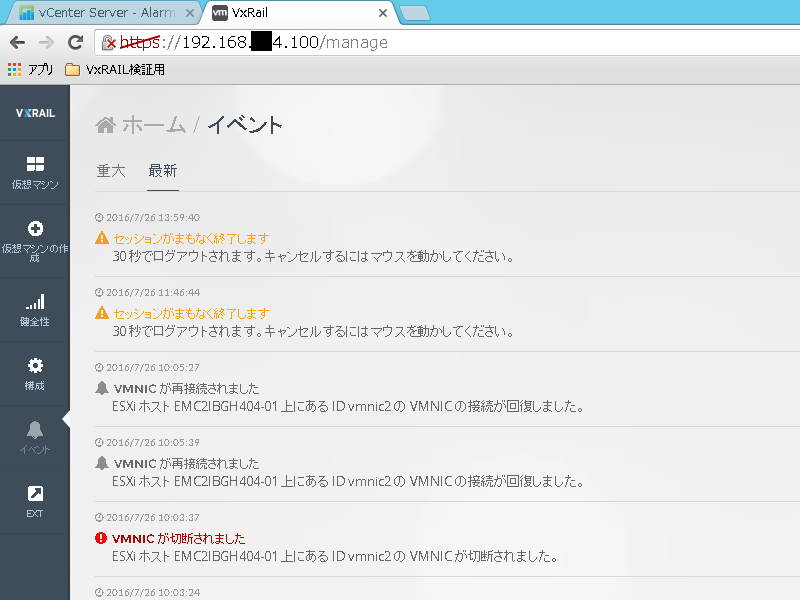
イベントログの表現は非常に平易です。
vRealize Log Insightは128CPUまでのライセンスがバンドルされているようです。
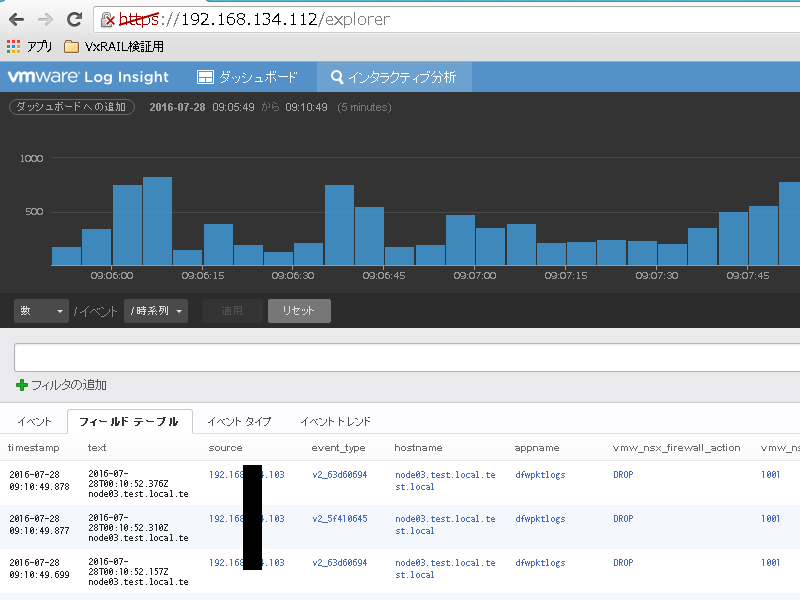
VSAN
組み込まれていたバージョンが6.0(最新版は6.2)だったので、問い合わせてみたところ、「ファームウェアがまだ対応していない関係で6.2の機能(ストレージIOPSの制限など)が一部使えないため」とのことでした。 VMwareにとって「純正」ともいえるVxRailで最新版が使えないとは意外でした。
(8/10訂正) 後で再確認したところ、「ファームウェアがまだ対応していない」のは試用機固有の問題、という話でした。
VSANは、ボリューム/LUNを切り出して使う通常のストレージとは違い、クラスタで1つのボリュームを構成します。その中で、いろいろなポリシーを作成し、冗長度(許容する障害の数=いくつのコピーを作るか)、ストライプ数などを定義します。
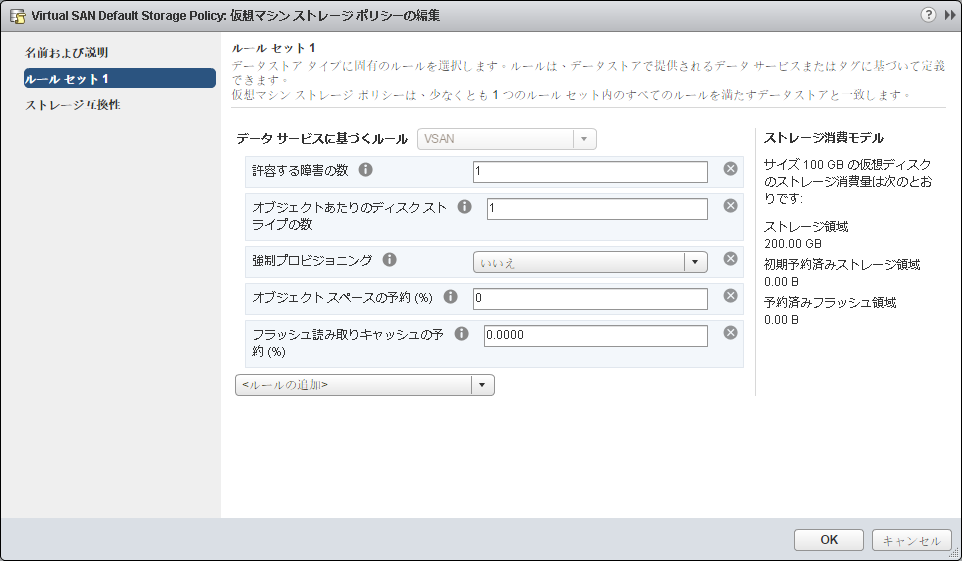
ポリシーは、仮想マシンに組み込む仮想ディスクを作成するときに指定します。
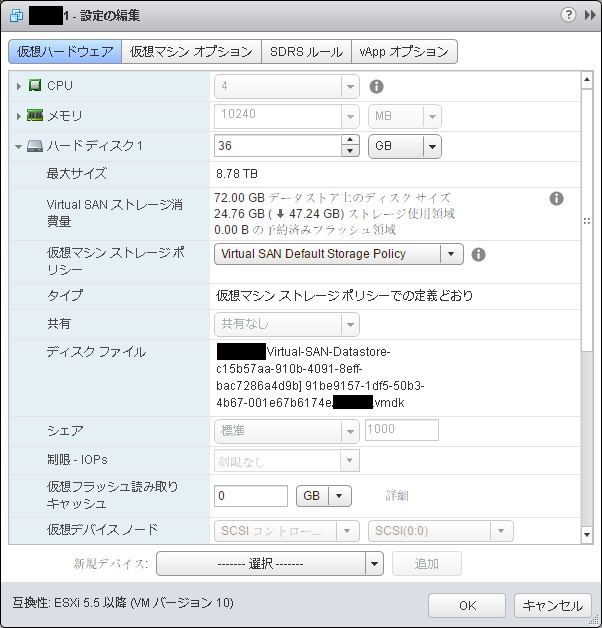
なお、仮想ディスクは、必ずしも仮想マシンと同じノードに作成されるわけではないようです(自動配置)。また、指定した冗長度の分だけ、別ノードのディスク上にコピーが作成されます。
NSX
NSXを使うと、複数のコンポーネントが仮想マシンとして動作するようです。
ファイアーウォール機能を使うには、NSX Edge(論理ルータ)を作成します。
通常のファイアーウォールと同様、ポリシーの定義ができます。
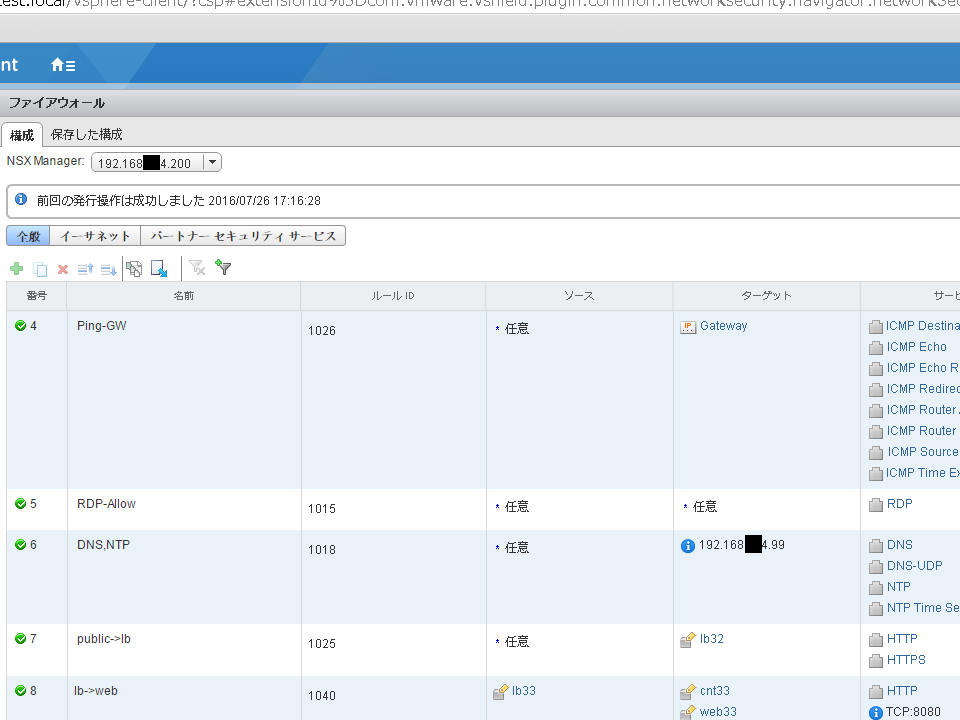
なお、試用機の環境では、仮想マシンのVMware toolsが最新版で、かつ正常動作していないと、ポリシー通り正しく通信できませんでした。
VMware toolsはLinuxカーネルのバージョンアップなどの際に再設定しないと動かなくなることがあり、また、止まっていることに気づきにくいので、注意が必要です。
高度なファイアーウォール機能はなさそうなので、必要であれば、Fortigate VMXやトレンドマイクロのDeep Securityなどと組み合わせて使うことになります。
性能評価
※事情により、具体的な数値の表現は控えます。
用意した仮想ディスクには、デフォルトのVSANポリシーを適用しました(冗長コピー=1)。
まずは自社で使っているWebアプリケーションに対してJMeterで負荷をかけてみたところ、特に問題なく動作。性能上も問題ないようです。
次に、mysqlslapで、read/write混在モードのテストを行いました。結果、自社で利用しているフルHDDのiSCSIストレージ(ネットワークI/Fは10G)とほぼ同等の性能が出ました。何度か実行してみましたが、特に性能のばらつきは生じませんでした。
ノード障害が発生した場合
ノード障害時、仮想マシンはHAにより別ノードで起動し、仮想ディスクはポリシーを満たすため別ノードに新たなコピーが作成されます。
あるノードに接続された2本の10G LANケーブルを外してみると、そのノードはシャットダウンされ、その上で動作していた仮想マシンの移動、および仮想ディスクのコピー再配置が始まりました。
この状態でJMeterによる負荷をかけたところ、どうやらパケットロスが発生し、リクエストに対するレスポンスが正しく返らないケースがちらほら見られました。時間の経過とともに減っていきましたが、仮想ディスクのコピーが影響しているのでしょうか?
もしかすると、試用機の設定ミスで発生したのかもしれませんが…。
また、管理用の仮想マシンはきちんと起動しているのに、なぜかログやイベント情報が取れなくなりました。
試用してみた印象
短い期間の試用であり、問題が発生したときの原因調査に割く時間もほとんどなかったので、設定等に問題があったかもしれませんが、
- 何もなければ普通に動く
- 障害(問題)が発生したときの動作に「?」な部分がある
- 標準添付の管理ツールから得られる情報が(従来型の物理サーバ+ストレージサーバの構成と比べて)少なく、障害の切り分けが少し難しい
という印象でした。
結果、ハイパーコンバージドの1つのウリである、「管理コストの削減」につながるか、ちょっと微妙な感じでした。
もちろん、ストレージサーバがいらなくなることで、ハードウェア点数が減る=システム全体の故障率は下がるでしょうし、親会社EMCで定評のあるリモートでのサポートを受けられることで、実際には問題解決をある程度「お任せ」できるというメリットはあります。
歴史が浅い分急速に進化もしていますし、もう少し様子を見てみてもいいかな、と思いました。
なお、後日、Nutanixについても試用予定です。情報の公表に関する制限条項が以前と変わっていなければ、性能に関する情報を外部に公表することはできませんが…。