データの可視化手法に興味あり Kibana が "4" となって使ってみたかったので試してみました。
動作させる環境は Mac(osx) です
Kibana
Kibana は Elasticsearch に投入されたデータを可視化するツールでありログデータの可視化等に主に使用されます。
ログの各データにTimestampが含まれているものに対して時系列データ分析の取り扱が大変強力ですが絶対にそれが必要というわけでもありません。
Elasticsearchは言うまでもなくSolrと並ぶ Lucene 検索エンジンが動作する分散型の全文検索サーバです、
準備 (Download)
どちらも最新(2015/6時点)をDownLoadします。
* Kibana4-download - 4.1
- Elasticsearch - download - 1.6.0
インストール
解凍するだけです
$ ls -ltr
total 75280
-rw-r-----@ 1 hiyuzawa staff 10139433 6 17 23:02 kibana-4.1.0-darwin-x64.tar.gz
-rw-r-----@ 1 hiyuzawa staff 28401477 6 17 23:08 elasticsearch-1.6.0.tar.gz
$ tar -zxvf elasticsearch-1.6.0.tar.gz
$ tar -zxvf kibana-4.1.0-darwin-x64.tar.gz
$ mv elasticsearch-1.6.0 elasticsearch
$ mv kibana-4.1.0-darwin-x64 kibana
起動
binの中の起動コマンド実行するだけです
- Elasticsearch
$ cd elasticsearch
$ ./bin/elasticsearch
[2015-06-17 23:14:52,684][INFO ]
....
[2015-06-17 23:15:00,788][INFO ][node ] [Harness] started
http://localhost:9200/
にアクセスすればversion情報等が含まれるJSONが出力されるはずです
- Kibana
Elasticsearch とは別ターミナルにて
$ cd kibana
$ ./bin/kibana
{"name":"Kibana",....,"msg":"Port 5601 is already in use","time":"2015-06-17T14:16:42.985Z","v":0}
http://localhost:5601/
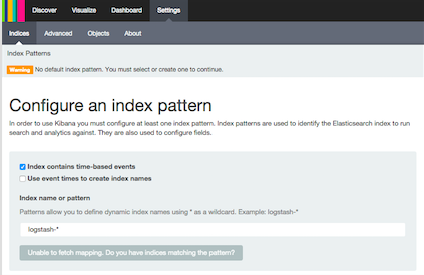
にアクセスすると下のような画面が表示されます。Elasticsearch内のデータの中でKibanaで可視化するindexを指定してください的な画面です。
まだ何もデータを投入していないので今できることはココまでです。
データの準備
よくあるチュートリアルでは httpd のアクセスログ等を用いている場合が多ので今回はちょっと変わったデータで試してみようと思います。
2015年6月16日 19時54分 2015年6月16日 19時50分ごろ 釧路地方中南部 北緯43.5度 東経144.1度 ごく浅い 2.3 この地震による津波の心配はありません。
2015年6月16日 16時51分 2015年6月16日 16時47分ごろ 宮城県沖 北緯38.7度 東経141.8度 50km 3.0 この地震による津波の心配はありません。
2015年6月16日 13時45分 2015年6月16日 13時42分ごろ 新潟県上中越沖 北緯37.5度 東経138.4度 10km 3.6 この地震による津波の心配はありません。
...
過去に発生した地震のデータです。とあるサイトからお借りしました。(いわゆるクロールですが) データはtsv形式で左から
- 発表時刻
- 発生時刻
- 震源地
- 緯度
- 経度
- 深さ
- マグニチュード
- 津波情報
として借りました。
データ作成
上の地震データを用いてElasticSearchのindexを作成します。先に書いたようにKibanaはtimestampを持つ時系列データの可視化が得意です。それを確認するために地震の発生時刻をtimestamp化させます。
今回はElasticsearchのBulk APIを利用してデータを挿入するので具体的には上の例に挙げた3行ので地震データを以下の6個(6行)のJSONデータ化します。
{ "index" : { "_index" : "disaster", "_type" : "earthquake", "_id" : "1" } }
{"tsunami":"この地震による津波の心配はありません。","timestamp":"2015-06-16 19:50:00","depth":"ごく浅い","location":{"lon":"144.1","lat":"43.5"},"place":"釧路地方中南部","power":"2.3"}
{ "index" : { "_index" : "disaster", "_type" : "earthquake", "_id" : "2" } }
{"place":"宮城県沖","power":"3.0","depth":"50km","tsunami":"この地震による津波の心配はありません。","timestamp":"2015-06-16 16:47:00","location":{"lon":"141.8","lat":"38.7"}}
{ "index" : { "_index" : "disaster", "_type" : "earthquake", "_id" : "3" } }
{"place":"新潟県上中越沖","power":"3.6","timestamp":"2015-06-16 13:42:00","tsunami":"この地震による津波の心配はありません。","depth":"10km","location":{"lon":"138.4","lat":"37.5"}}
見てわかる通り 2行1組です。挿入数するデータの投入先(index/type)=(disaster/earthquake)およびIDの指定が1行目で実データが2行目です.
緯度経度のところをちょっと構造化させてJSON化していますがこれは後で説明します。
とりあえず、このJSONファイルを eq_data.json として保存します。
データの挿入
投入してみます。以下のコマンドです。
$ curl -XPUT localhost:9200/_bulk --data-binary @eq_data.json
にアクセスするとElasticsearch内のデータが一部見えます。total の部分が3と3データ登録されていることが確認できます。

注意 rootパスで_search としているので全indexが対象となり、先にkibanaを試しでアクセスした場合にそれの管理データが挿入されているかもしれません。
全データを一度削除する場合は
$ curl -XDELETE 'localhost:9200/*'
とすればokですし、もしくはindex typeを以下のように指定しても投入したデータのみ3行見えると思います。
http://localhost:9200/disaster/earthquake/_search?pretty
マッピング
Elasticsearchは事前にindex構造を定義する必要がなく、データ投入時にそのデータ構造に応じて自動的にindexが型とともに定義されます。
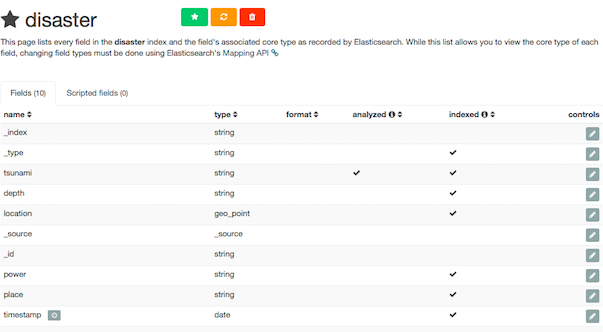
今回投入した際も特に指定していなかったので自動で作成されています。これを確認してみます。
{
disaster: {
mappings: {
earthquake: {
properties: {
depth: {
type: "string"
},
location: {
properties: {
lat: {
type: "string"
},
lon: {
type: "string"
}
}
},
place: {
type: "string"
},
power: {
type: "string"
},
timestamp: {
type: "string"
},
tsunami: {
type: "string"
}
}
}
}
}
}
上記のように表示されるとおり、すべてのindexが string 扱いであり、これはよろしくありません。
自動に頼らず自前で定義する必要があるということです。
マッピングの定義を以下のように作ります eq_mapping.json としときます。
- timestamp を目的通り date型にする
- 緯度経度を保持するlocationを geo_point型にする
- tsunami以外のindexは analyze不要なので not_analyzed とする (値をそのまま完全一致として利用したい場合は not_analyzedを指定)
{
"mappings": {
"earthquake":{
"properties":{
"depth":{
"type":"string",
"index" : "not_analyzed"
},
"location":{
"type": "geo_point"
},
"place":{
"type":"string",
"index" : "not_analyzed"
},
"power":{
"type":"string",
"index" : "not_analyzed"
},
"timestamp":{
"type":"date",
"format":"YYYY-MM-dd HH:mm:ss"
},
"tsunami":{
"type":"string"
}
}
}
}
}
これを Elasticsearchに適応させます。すでにデータがある状態でのmapping変更は厄介なので一度キレイにしてからmappingを定義します。以下のようにします
$ curl -XDELETE 'localhost:9200/*'
$ curl -XPUT localhost:9200/disaster --data-binary @eq_mapping.json
再び以下にアクセスしてmappingの状態をみます。
http://localhost:9200/_mapping?pretty
定義した形でmappingが定義されていることが確認できます。
データ挿入 再び
それではデータを今度は全部投入してみます。全データ入っているjson を eq_data_all.json とすると上で3件入れた時と同じです。
結果出力は不要なので /dev/null に逃がします。
$ curl -XPUT localhost:9200/_bulk --data-binary @eq_data_all.json > /dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7866k 100 2222k 100 5644k 241k 612k 0:00:09 0:00:09 --:--:-- 0
何件挿入できたか確認します。
http://localhost:9200/disaster/earthquake/_search?pretty

23,721件です. (...取りすぎですね。ごめんなさい(某サイト))
Kibana による可視化
ようやくKibanaの出番です。
indexの定義
http://localhost:5601/
へアクセスします。可視化するデータのindexの指定を求められますので
- indexは時系列イベント(time-based)である
- index名は disaster
と指定します。するとプルダウンに時系列のfieldってどれ?って言われるので mapping で date型と定義した timestamp を選択します。
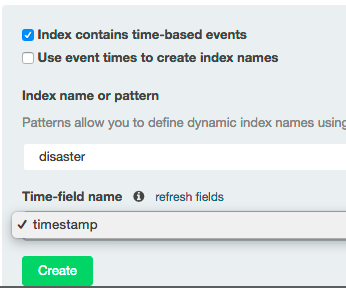
create をクリックすると indexの定義が読み込まれ一覧されます。
とりあえず可視化
試しに可視化してみるには上のメニューの Discover です。

選択すると No result found とか今回のデータは出ると思いますが、慌てず右上をみます。
とりあえず 直近15分のデータを可視化しますね、ってなってるので今回の例だとぜんぜんだめなので、
これを最大の Last 5 years に変更します
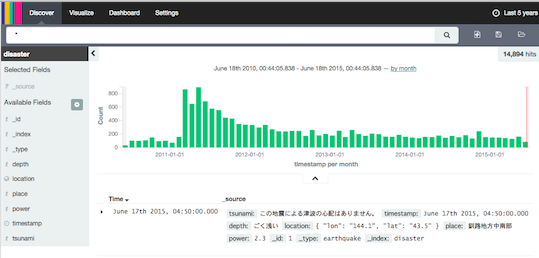
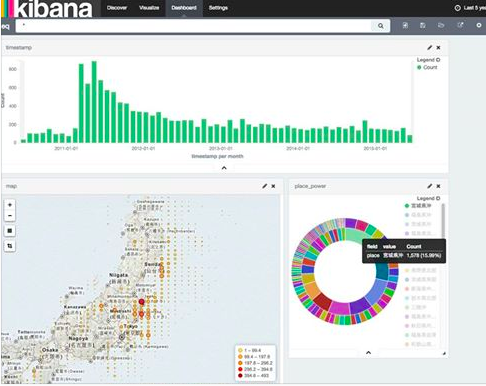
これだけでちょっとした可視化完成です。時系列でデータの頻度が可視化されます (2011年3月から地震の発生が多いのが一目わかります)
左メニューを使ってみます. place (震源地)を選択してVisualizeを選択します
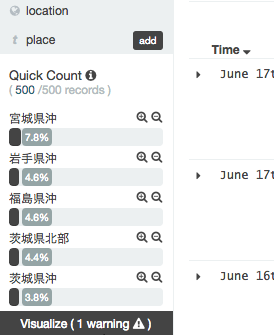
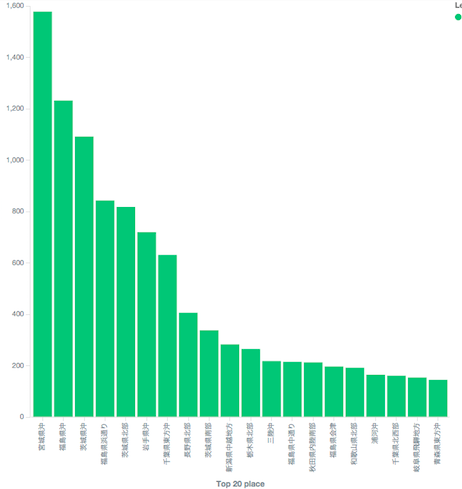
震源地Top20が縦棒グラフで表示されました
ダッシュボードの作成
ダッシュボードを利用すると複数のデータをタイル状で一覧して確認できます。また、各アイテムを選択、時系列範囲の調整に応じてダッシュボード内のデータが連動して切り替わります。大変便利です。作ってみましょう。
流れは
- 個別の可視化オブジェクトを上部メニューのVisualizeから作成
- Dashbordにてそれを取り出して好きなレイアウトに配置
です。今回すこしこだわっていた緯度経度 geo_point の可視化オブジェクトをダッシュボードに貼り付けるまでをやってみます。
可視化オブジェクト作成
-
Visualizeメニューから Tile map を選択します。

-
新しく定義するので 「From a new search」を選択します
-
左にメニュー右に世界地図が表示されるので左メニューのBucketsから Geo Coordinates を選択します。
-
どのフィールドが位置情報かと聞かれるので location を選択します (おそらく選択すでにされているはず)
-
緑の再生ボタンを押したら実データを使って可視化されます。
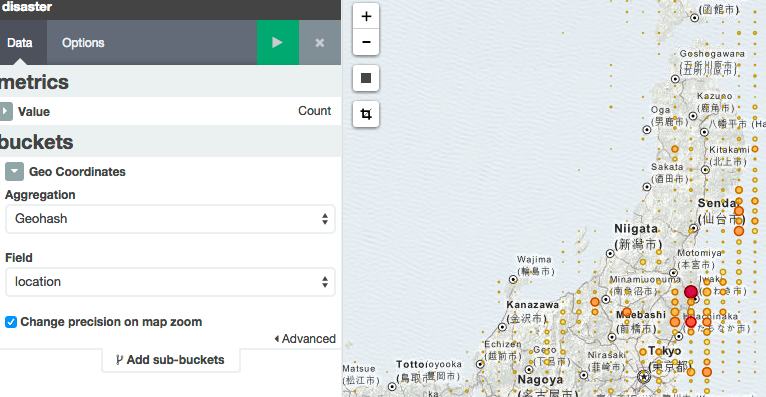
-
これをダッシュボードに利用したいのでsaveします。右上のSave Visualizationを選択します。適当に名前を付けて保存します
ダッシュボード作成
- 右上の 丸の+のボタンを押すと、作成した可視化オブジェクトが一覧されます。
- それを選択するとパネルに表示され、自由にレイアウトが可能です。
- これを繰り返すと以下のようなダッシュボードが作成できます