この記事はembulk advent calendarの6日目の記事です。
Qiitaでembulkのまとめを作っている佐藤(@hiroysato)です。
毎年11月29日のいいにくの日にに開催される全文検索エンジンGroongaの勉強会にて、全文検索エンジンGroongaにデータを投入するembulk-output-groongaの紹介をしてきました。
Groongaについて
Groongaは国産の全文検索エンジンです。全文検索機能を単体で使うだけではなく、MySQL(Mroonga)やPostgreSQL(PGroonga)に全文検索の機能を提供することができます。さらにPGroongaはJSONで格納したデータ内のすべてのテキスト値に関しても全文検索機能をサポートしています。
国産の全文検索エンジンだけあって、日本語特有の全角文字と半角文字の正規化などの機能もGroongaに組み込まれています。特別なプラグインは必要がありません。
速度もelasticsearchと比較をしても遜色ないようです。(検索に関してはGroongaの方が速いようです。)
国産の全文検索エンジンGroonga vs 世界的流行のElasticsearch
また開発も積極的に行われており、不具合や不明な点を報告するとすぐに対応をしてくれるのも魅力です。
embulk-output-groonga
勉強会で紹介したプラグインは、embulk-output-groongaで、全文検索エンジンGroongaへデータを登録するoutputプラグインです。
まだあまり、機能がなくgemにはしておりませんが、Groongaにデータを投入する際に利用をしています。
設定もものすごく簡単です。
out:
type: groonga
table: Data # 投入先のテーブル名
host: localhost
protocol: http
key_column: title # キーにするカラム
使いたいという方がいらっしゃれば是非おしらせください。
2015/12/6 更新: gemにしましたのでご利用いただき、ご要望があれば是非お知らせください。
メールをパースするパーサープラグイン
この時の発表では触れませんでしたが、自作したプラグインはもう一つあります。
電子メールのデータを取り込むパーサープラグインです。
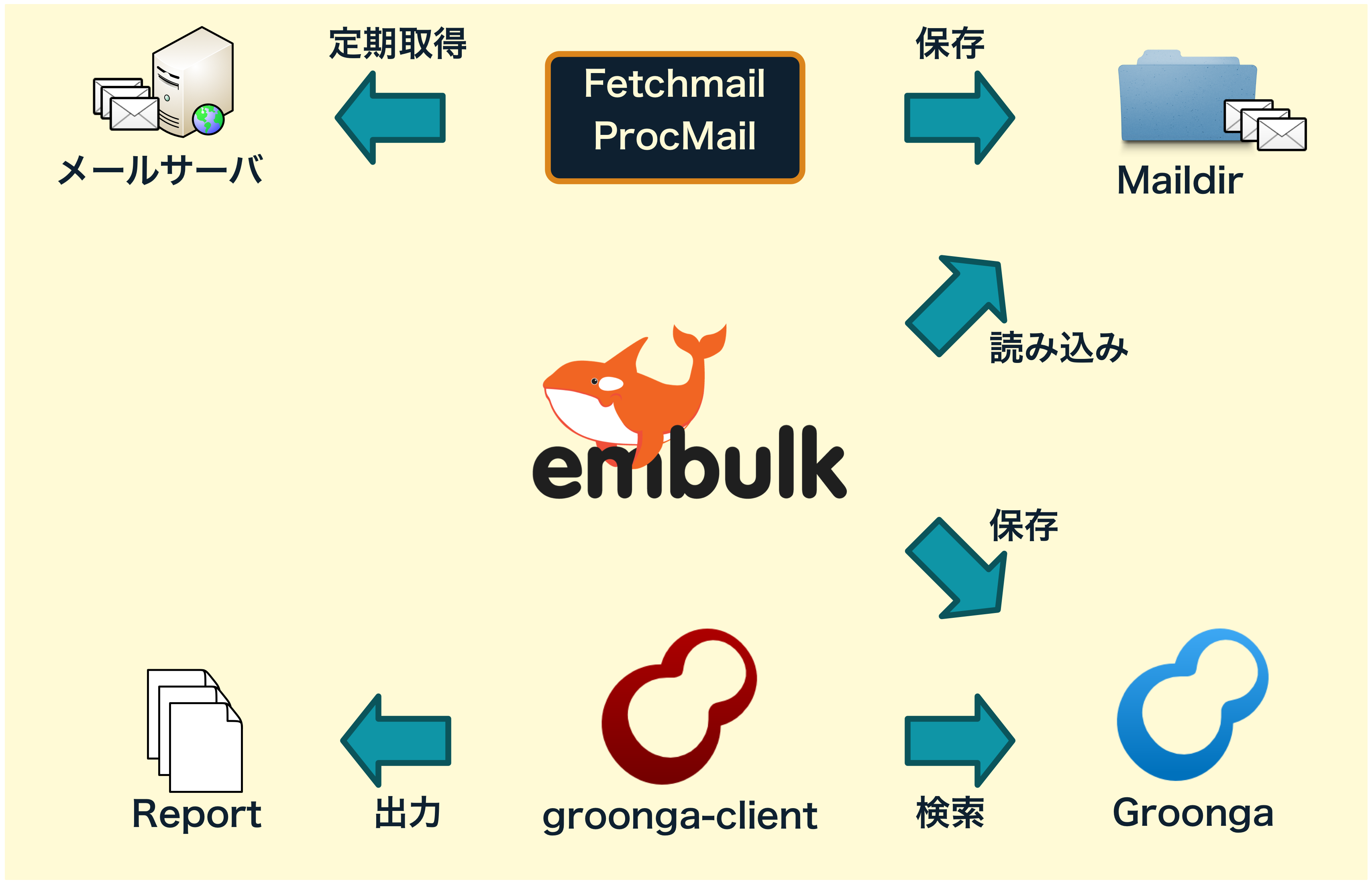
稼働しているサービスに必要なデータが電子メールで提供されるため、定期的にデータを取得してデータベースに登録する仕組みが必要でした。
そこで、fetchmailやprocmailを使ってメールデータをMaildir形式のディレクトリに保存した後、embulkを使ってデータを読み込むようにしました。
Maildirに保存されたデータは、1ファイル1メールデータになります。このデータを読み込み電子メールの中から必要な情報を抜き取って、データ化するパーサプラグインを作成しました。
パーサープラグインRubyで作成しました。Rubyには電子メールをパースするプラグインMailが提供されているため、自分で書くコードはほとんどありませでした。
こちらは業務に特化してるのでソースは非公開ですが、イメージ的には次のようなものです
def run(file_input)
while file = file_input.next_file
mail = Mail.new(file.read)
# メールのソースを解析
page_builder.add(record)
end
page_builder.finish
end
cronでの定期実行
新着メールの読み込みは、cronを定期実行して運用しています。
Maildirの仕様では、保存する各メールデータには、メールの受信時刻が使われます。
embulkを実行し最後に読み取ったメールはどのメールであったかを記録することができます。
次回embulkを実行する際は、前回読み取ったメールは再度読み込みを行わずに、新しく届いたメールだけを読み取ることが可能です。
embulk run config.yml -o config.yml
最後に
小規模サイトでのembulk利用例でした。Google BigQueryや、Amazon Redshiftなどは使わなくてもembulkを有効活用できる一例です。
末筆ですが、Embulkがリリースされた直後から、Fluentdのバッチ版Embulk(エンバルク)のまとめ というのを作成しています。ここ1年のembulkに関する記事の9割ぐらいはこちらから参照できると思います。これからembulkを始められる方は是非ご参考になさってください。