要件
- クライアント数は、約2000ノード
- 各ノードから秒間1~2件のログ (5000件/秒程度)
- ログの保存期間は2週間
アプリケーション/ミドルウェア
- Glaylog Server 2.1.1
- MongoDB (v3.0.4を使用)
- Java 1.8.0
- ロードバランサー(lvs, haproxy, nginx等)
- Elasticsearch 2.4.1 (Graylog2.1から2.4系に対応)
- Graylog Collector 0.5.0 (0.4系は非対応)
ハードウェア
- MongoDB .... 3台
- バランサ用サーバ ... 1台
- Graylog server ... 10台 (12GB memory / 300GB HDD)
- Elasticsearch ... 200台 (96G memory / 700GB SSD)
構成
各ミドルウェアの配置については、以下のようにしました。公式ドキュメントも参考になります。以前はGraylog Web interface というGUIが別途存在しましたが、Graylog2からは、Graylog Serverに統合されました。JavaScriptベースに書き直され、GUIがクライアントサイドで動くようになっています(データ自体はAPIから取得)
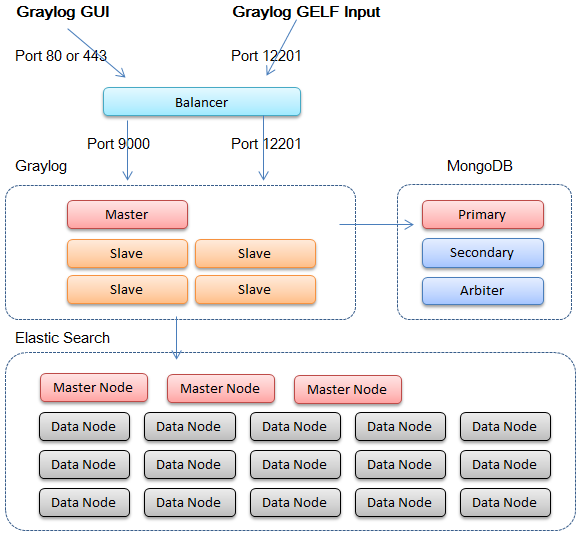
Mongodbについては、それほど高スペックなサーバは必要とされませんが、Mongoのノードが死ぬとGraylogが停止しますので、推奨されている3台構成がよいでしょう。
Graylog ServerおよびElasticsesrchについては、秒間のリクエスト数と、保存期間に応じて、それなりの台数までスケールする必要があります。
Graylog Serverのマスターノードは1台しか設定できません。マスターノードの停止中でもログは受信できますが、Inputの追加などの設定変更などができません。
ログの保存件数
必要なレコード数は、5000件/秒 * 86400秒 * 14日 なので、
1世代あたりのログの上限 x 世代数が、これを超えている必要があります。
elasticsearch_max_docs_per_index ... 1世代あたりのログの上限
elasticsearch_max_number_of_indices ... 世代数
この値はセットアップ後にも、GUI上から変更できます。
ElasticSearchの構築
今回はElasticsearchが200ノードありますが、冗長性を考え、1ノードあたり2シャード以下、かつ1シャードに対し2つのレプリカを構成します。だいたい120シャードが適切と計算しました。 200 * 2 > 120 * 1(プライマリ) + 120 * 2(レプリカ)。
こちらに関しては、別途記事を書きたいと思います。
Graylog のインストール
基本的にはtarを展開して、コンフィグを修正するだけです。
コンフィグの各行を見ていきましょう。
is_master = true
# マスターノードか否か。マルチノードの場合、1台だけtrueに設定する
password_secret = xxxxx
# mkpasswd などで生成する
root_password_sha2 = xxxx
# echo -n "password" | sha256sum などで生成
rest_listen_uri = http://xxx.xxx.xxx.xxx:9000/api/
web_listen_uri = http://xxx.xxx.xxx.xxx:9000/
web_endpoint_uri = /api/
# ListenするIPを書く。0.0.0.0ではなく、IPアドレスを指定する。
# GUIとRestAPIのポートは分けても良いし、同じにしてもよいですが、同じ場合は、URLで分けるため、`web_endpoint_uri` を設定する。
elasticsearch_max_docs_per_index = 30000000
elasticsearch_max_number_of_indices = 20
# 1インデックスあたりのログ上限と、インデックスの世代数を設定(GUIからも変更可能)
elasticsearch_shards = 120
elasticsearch_replicas = 2
elasticsearch_index_prefix = graylog
# シャードとレプリカの数の設定
elasticsearch_discovery_zen_ping_unicast_hosts = xxx.xxx.xxx.xxx:9300, xxx.xxx.xxx.xxx:9300, xxx.xxx.xxx.xxx:9300
# elasticsearchのマスターノードの一覧を設定
elasticsearch_node_master = false
elasticsearch_node_data = false
# Graylogは、内部でElasticSearchのクライアントノードとして動作して、クラスタにJOINするので、両方Falseにする
elasticsearch_transport_tcp_port = 9300
elasticsearch_network_host = 0.0.0.0
# クライアントノードとして動作する場合、外からの通信も受け入れなくてはいけないので、127.0.0.1ではなく、グローバルでListernする
mongodb_uri = mongodb://xxx.xxx.xxx.xxx,xxx.xxx.xxx.xxx,xxx.xxx.xxx.xxx/graylog
# MongoDB 3台分のURL。ポート番号27017は省略可能。
ロードバランサ
ロードバランサは、NginxやHAProxy、LVSなどを利用するのが良いでしょう。ただし、UDPでロードバランスしたい場合(たとえば、Syslogを収集したい場合など)は、現状ですと、LVS以外に選択肢はないと思います。
本来であれば、ロードバランサ自体もKeepalived等で冗長化するべきですが、今回は1台構成にしています。
各Graylogサーバはヘルスチェックコンテンツ(/api/system/lbstatus)を持っているので、ロードバランサ側に設定します。
HAProxyの場合、以下にするとよいでしょう。
Backend web-ui-backend
option httpchk GET /system/lbstatus
server webui-001 192.168.100.100:9000 check
server webui-002 192.168.100.101:9000 check
server webui-003 192.168.100.102:9000 check
GUIとAPIのポートを分けている場合は、以下のようにするとよいでしょう。
Backend web-ui-backend
option httpchk GET /system/lbstatus
server webui-001 192.168.100.100:9000 check port 12900
server webui-002 192.168.100.101:9000 check port 12900
server webui-003 192.168.100.102:9000 check port 12900
総括
以上のような構成にすることで、最大で、秒間数万件のログを受信できることを確認しました。クライアントノード数も、数千ノードまでは問題なく動きます。
その際に気を付けないといけないのは、1件あたりのログのサイズにも依存しますが、トラフィックになるかとおもいます。実際にネットワークの上限に到達すると、Graylog側のログに、indexing failのログが残ります。