1.きっかけ
国立国会図書館デジタルコレクション(デジコレ)にある作品の中から地元の歴史にゆかりのある記述を引用してWikipediaやLocalWikiの記事を編集していたのですが、著作権保護期間が満了しているものは引用だけでなく作品全体を自由に利用することができるのに、みんなが原文(画像)を見ながら部分的に文字起こしして引用するのは勿体無いなぁと思い、作品全体をアーカイブする方法を探していたところ、ウィキソースにたどり着きました。
2.ウィキソースとは何か
ウィキソースのメインページにある説明によれば以下のとおり。
ウィキソースとは、自由(フリー)なソーステキストや、その翻訳文をウィキで作成することを目的としています。詳細はウィキソースとは何かをご覧ください。
ウィキペディアが図書館で云う一次資料や二次資料を引用して作る百科事典であるのに対して、ウィキソースはフリーな資料をまるごと記録するものです。作品1冊まるごとをひとりで記録するのは大変なので、例えばページごとに記録(文字起こし)する作業を誰でも分担して進められるようになっています。
ウィキソースの説明によれば次のようなものが取り入れられます。
- 任意の著者による以前に出版された原本
- 民族や国際的な関心に就いての歴史的な文書
- 原典の翻訳
- 数学のデータや公式の表
- 選挙結果のように、統計的な資料
- ウィキソースにおいて特集された著者の著書目録
- GFDLに適合する、あるいはパブリックドメインにあるソースコード
実際のウィキソースのコンテンツの例
- 拾遺和歌集
- 聖書
- 平成二十二年二月二十八日の津波による災害についての激甚災害及びこれに対し適用すべき措置の指定に関する政令
- カリフォルニア州メンローパーク市の人口統計データ
- プログラマが知るべき97のこと
- 坂本龍馬の手紙
- 漱石山房の冬
次のようなものは取り入れられません。
- 著作権侵害のおそれを持つすべて
- ウィキペディアの投稿者がオリジナルに執筆したもの
3.青空文庫との違い
実はあまりよく分かっていないのですが、あえていえば青空文庫が国内の有志が始めた日本発のプロジェクトであるのに対して、ウィキソースはウィキメディア財団によるウィキペディアを始めとする世界的なプロジェクトのひとつとして多言語対応や周辺技術など、広範な枠組みを最初から持っているといった、出自の違いに由来する守備範囲や技術的な差異はあるように思います。青空文庫は利用者向けのビューアアプリなども複数あり、その名のとおり文庫としての機能が充実していますが、ウィキソースはまだ発展途上のプロジェクトでどちらかといえば資料を登録する人向けの機能が充実しています。
とはいえ、よく似たプロジェクトなので例えば青空文庫からインポートしたテキストはすでにウィキソースに多数存在します。その逆もライセンス侵害を起こさない範囲であればおそらく可能だと思いますが、2016年3月現在、まだその実例は見つかりませんでした。もしかしたら文字起こしをする際の細かな編集方針のすり合わせなどが必要なのかもしれません。
4.活用事例
ウィキソースをどのようなことに活用できるのか、考えてみました。
4.1.デジコレにある著作権保護期間満了の作品を機械可読な形式でアーカイブ
デジコレには様々、有用な作品が登録されていますが、現状ではあいにく画像化されているだけです。(書誌情報はテキスト化され、こちらで公開されています)これを画像を見ながら文字起こしして全文をテキスト化することにより、他の誰もが自由に利用できるリソースとしてポイントし、公開することができるようになります。
4.2.碑文などのソースとして
例えば水戸の偕楽園にある「偕楽園記碑」は現在wikipedia(media)上には画像としてアップされていますが、テキストとしてはウェブ上では個人ブログなどに記録されたものしかみつかりません。
烈公(徳川斉昭)によるこの文章が著作権保護期間を満了していることは明らかなのでウィキソース上にライセンスがクリアな形で登録・公開することにより、参照元としてはもちろん音声読み上げや全文検索など幅広い用途で自由に利用することができるようになります。
この碑文には烈公が学問の場としての弘文館に対して休息の場としての偕楽園を建築した趣旨として「一張一弛(いっちょういっし)」という言葉が記されているのですが、参照元として自由に利用できるソースをポイントできると、こういった地元で有名な言葉もより多くの人に知ってもらうことができます。
4.3.郷土史家などの調査研究のアーカイブとして
宅地開発などにより自然や遺構がどんどん消滅し、研究者や郷土史家なども高齢化しています。すでに現物が失われたものに関する事実情報を含む研究資料はかけがえのない、貴重なものです。そうしたもののうち、ライセンスがクリアなものはウィキソースやウィキメディアに登録することで人類の共有財産として後世に遺すことができます。
5.登録方法
ここでは国立国会図書館デジタルコレクション(デジコレ)の作品をウィキソースに登録する手順を説明します。
ウィキソースに登録する際には底本を何らかの手段で別に参照しながら文字起こしする方法と、底本を画像スキャンしたものを登録し、同じ画面の右側でそれを見ながら文字起こしする方法があります。検証可能性を考えると底本もあったほうが良いので、ここでは後者の底本を登録して参照する手順を紹介します。
5.1.事前準備
作品を選んで画像PDFをダウンロードし、ウィキソースで取り扱いやすい形に手元で整形します。底本として利用できるファイル形式はPDFまたはDjVuファイルですが、デジコレから取り出す場合は直接的にはPDF形式になります。
見開きで2ページが1画像としてスキャンされているものは、そのまま2ページを1単位として処理することもできますが、やはり1ページを1単位としておいたほうが実際の作品の構造を忠実に再現でき、また編集画面上も見やすいので作品の1ページごとにPDFの1ページとすることをオススメします。また、同一ページが2回スキャンされている場合がありますが、鮮明な方を選んで、あくまで原作品の構造に合わせたほうが扱いやすいです。
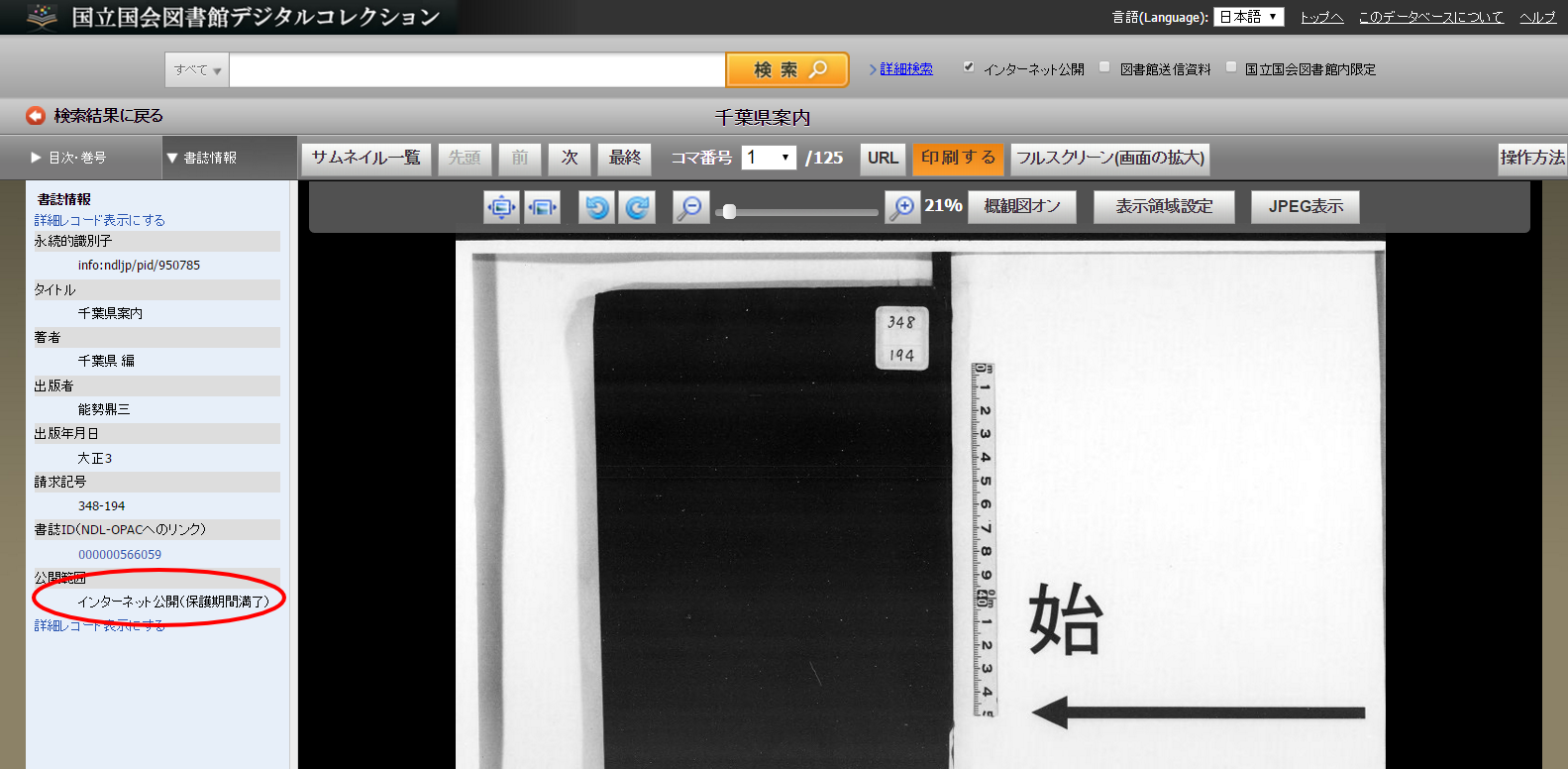
著作権保護期間が満了したものには上記のように公開範囲のところに「インターネット公開(保護期間満了)」と記載されています。
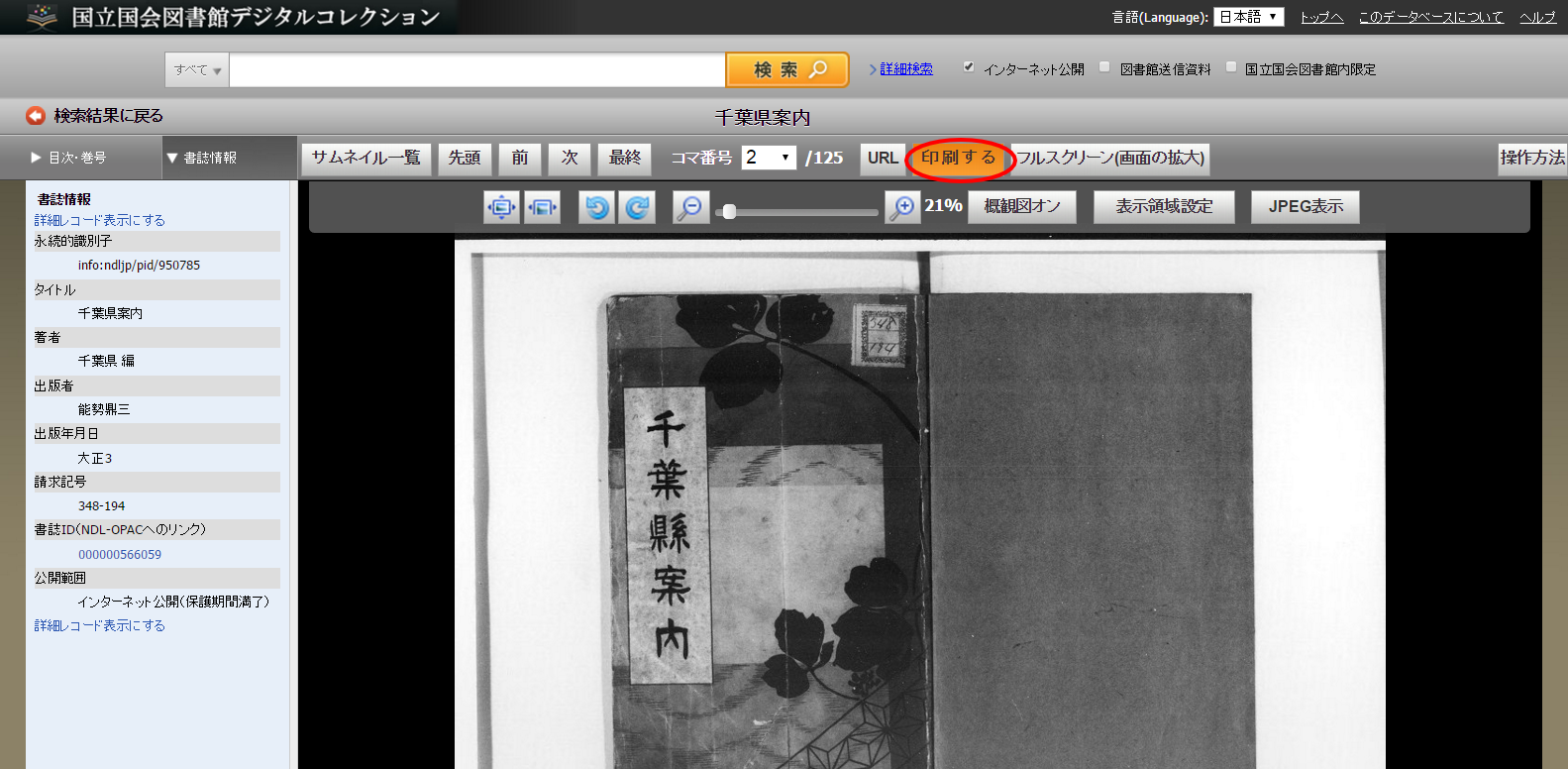
上部の「印刷する」ボタンを選ぶとポップアップが開くので
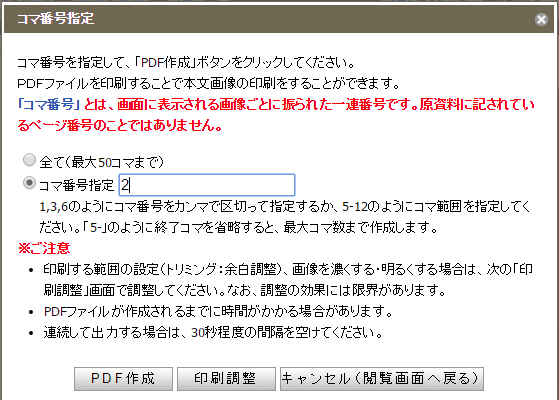
対象ページのコマ番号(デジコレ画面中央上部)を指定して「印刷調整」ボタンを押して
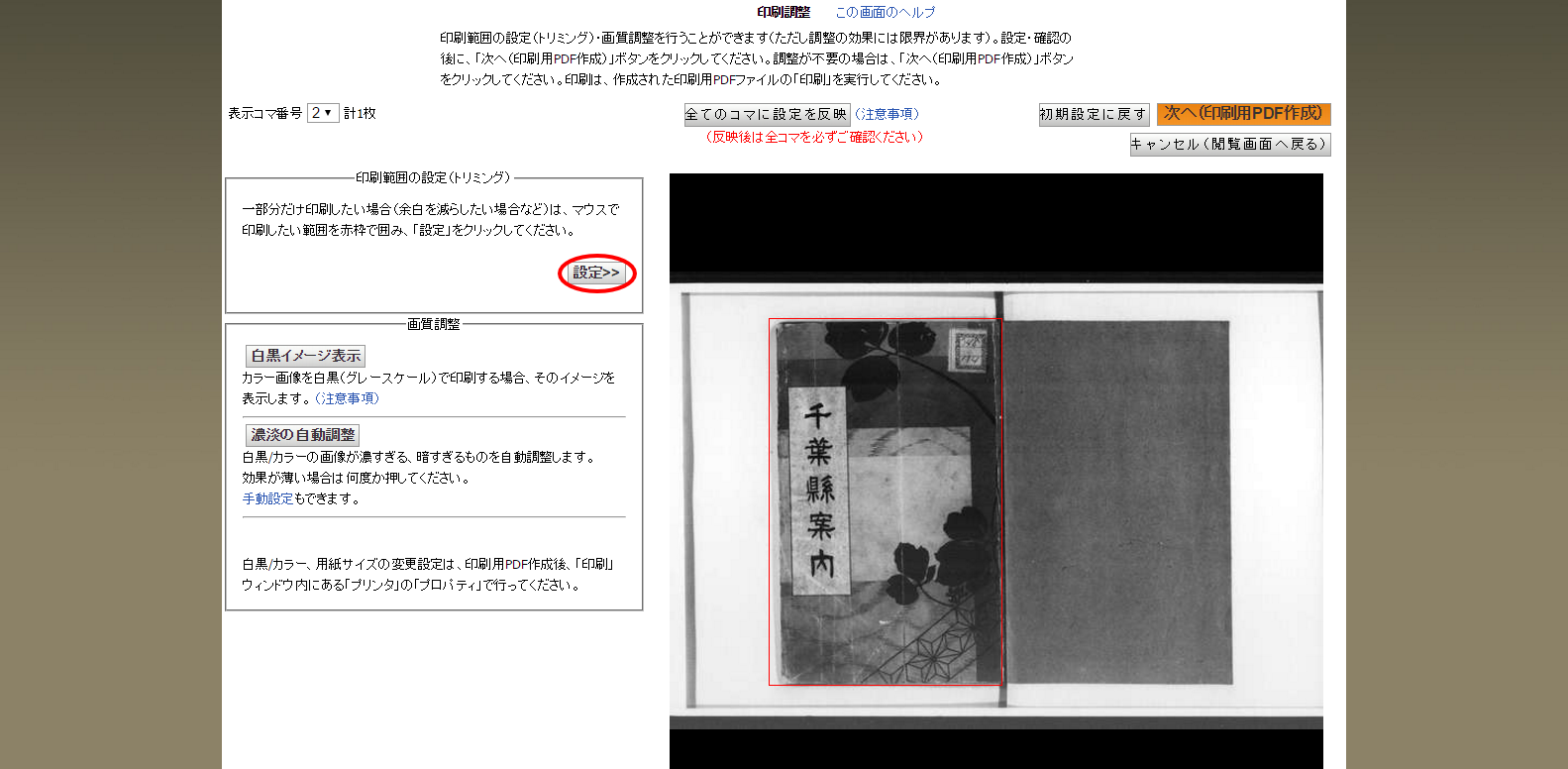
不要な空白をカットするなどのために印刷(画像出力)範囲を矩形で指定して「設定」ボタンを押し
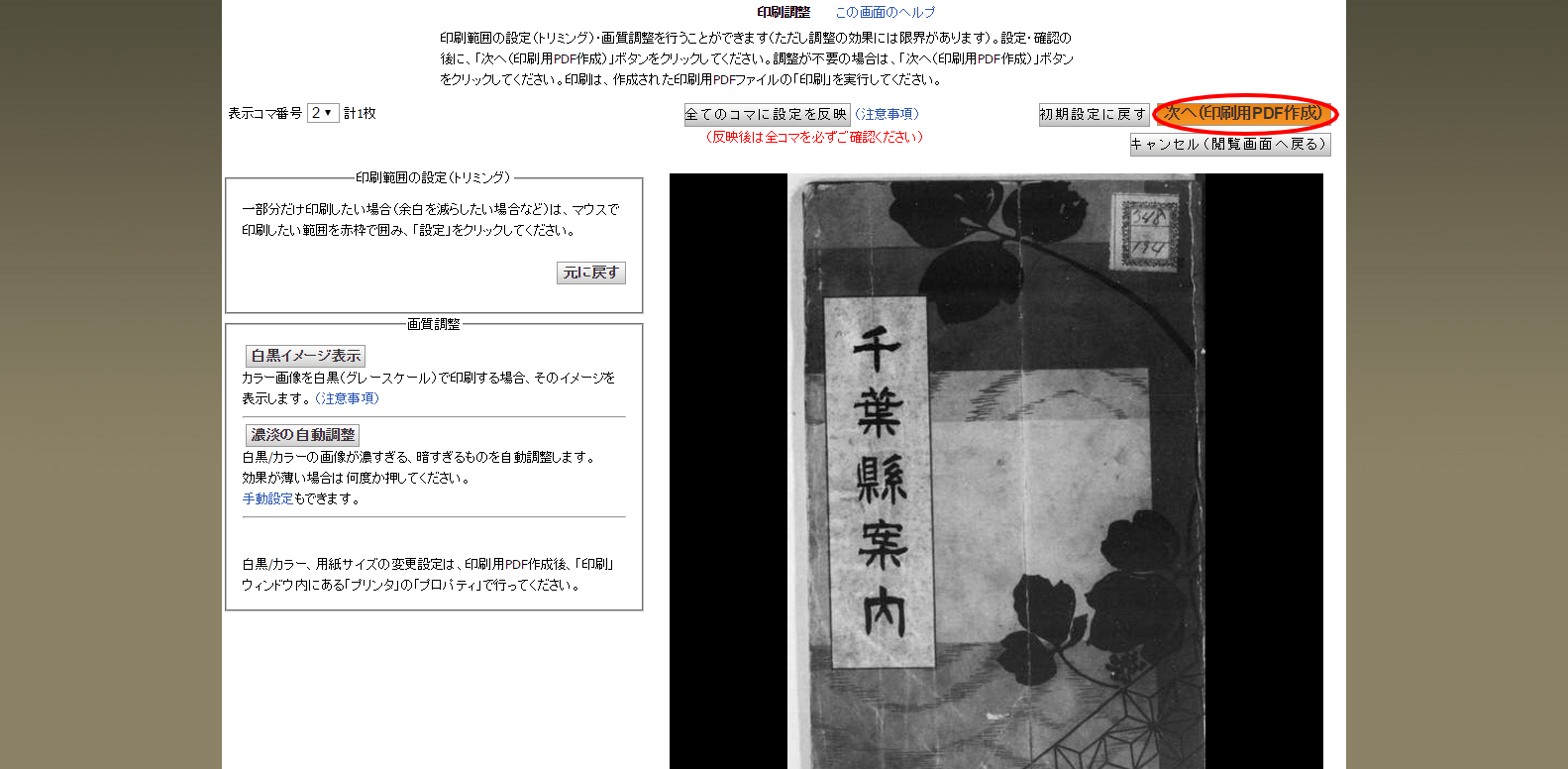
「次へ(印刷用PDF作成)」ボタンを押すと指定の矩形を切り取ったPDFファイルが出力されます。
PDF画像として取り出した後はお手元のPDF編集ソフトなどでページ分割、結合などの操作を行い、作品全体を1つのPDFファイルにします。ファイル名の命名規則は厳密には決まっていないようですが、私は他の方の命名を参考に「タイトル(著者名, 発行年).pdf」のようにしています。
5.2.Wikimedia Commonsにアップロード
PDFファイルをアップロードして、ウィキソースに資料を追加します(詳細はヘルプ:資料を追加するを参照してください)。
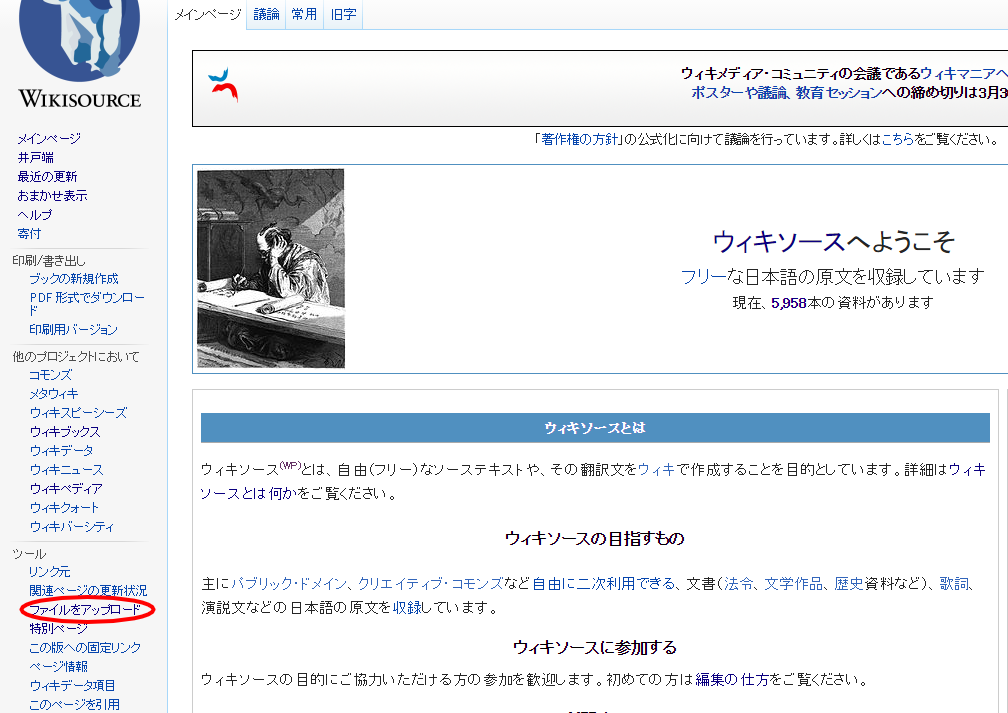
ウィキソースの左サイドメニューから「ファイルをアップロード」を選択。
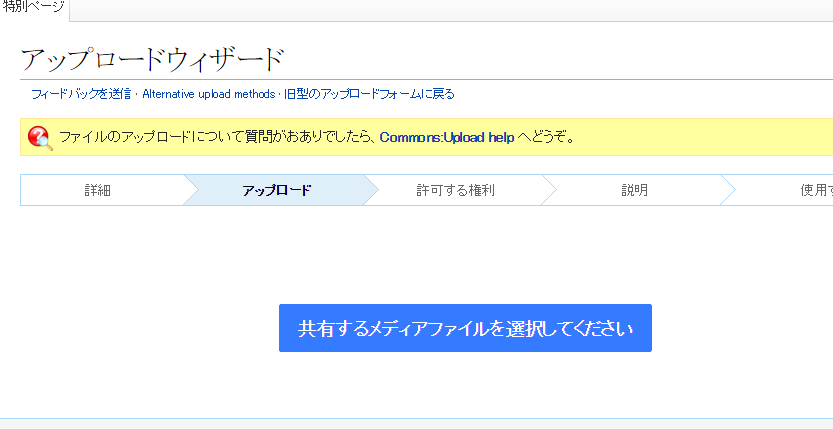
Wikimedia Commonsのアップロードウィザードにリダイレクトされるので、対象ファイルを選んでウィザードにしたがって利用者に許可する権利、説明などを設定します。このとき、概要説明の原典欄にはデジコレ上の該当作品URLを記入することを忘れないようにしてください。
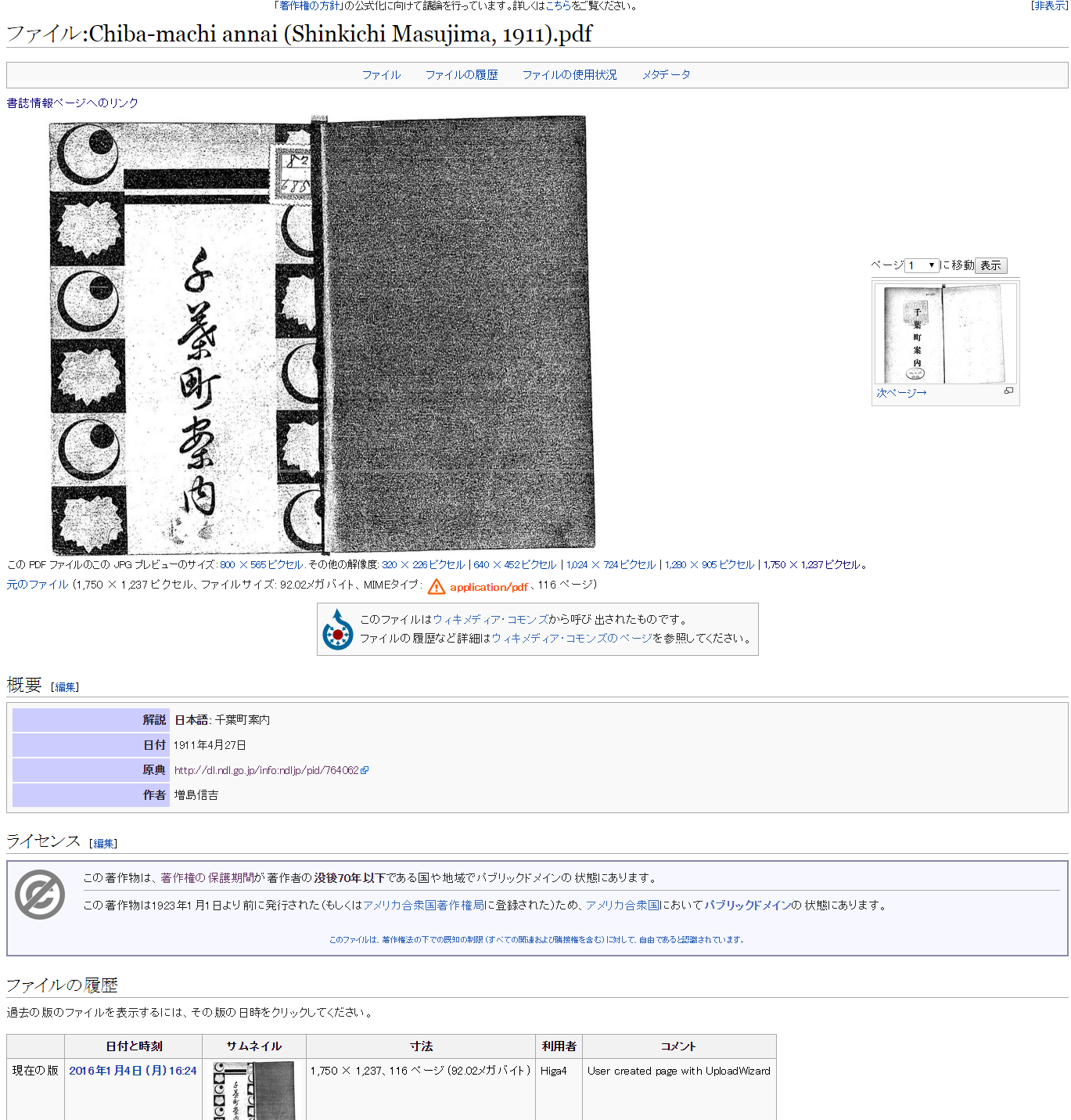
アップロードが完了すると上記のように登録されます。(ウィキソースからWikimedia Commonsへ自動的にリンクされます)
なお、この例は私が初めてアップしたもので見開きの2ページ分をpdfの1ページとして作成しており、あまりよくない例です ;)
5.3.indexページの作成
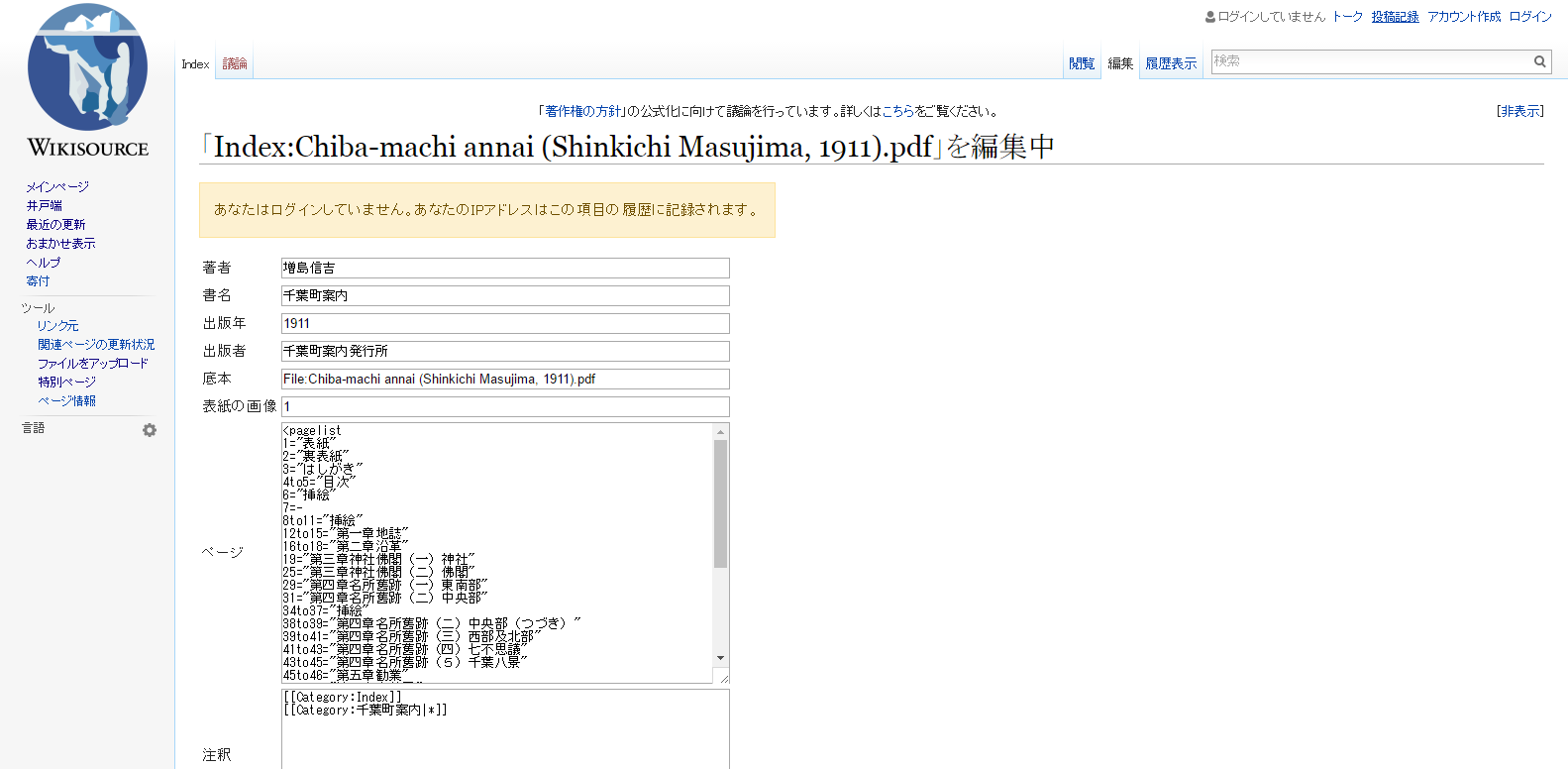
"Index:【アップロードしたファイルの名前】"という名前のページを作成します。著者、署名などの入力項目が現れるのでヘルプ:Indexファイルの基本ガイドを参考にそれぞれ入力します。
<入力例>
5.4.編集(底本を見ながら文字起こし)
(詳細はヘルプ:編集の仕方を参照してください)
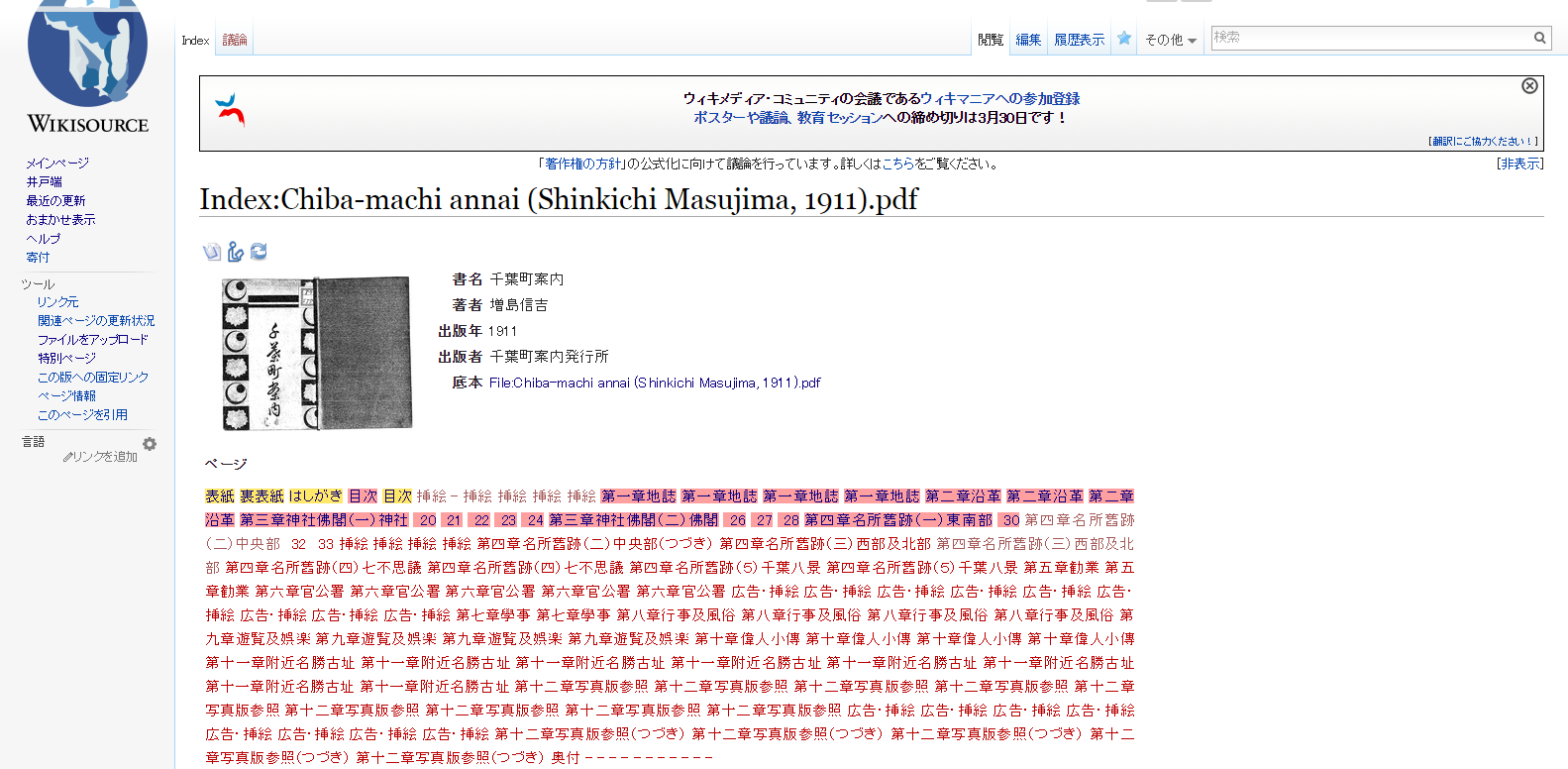
インデックスページを開くと上記のように底本のトップ画面が表示されます。赤字のリンクをクリックすると、それぞれのページの編集画面に遷移します。そのページの処理状況によって背景色が変わります。
これ以降は底本を登録した本人だけでなく、誰でも文字おこしの共同作業に参加できる状態になります。
5.4.1.文字起こし
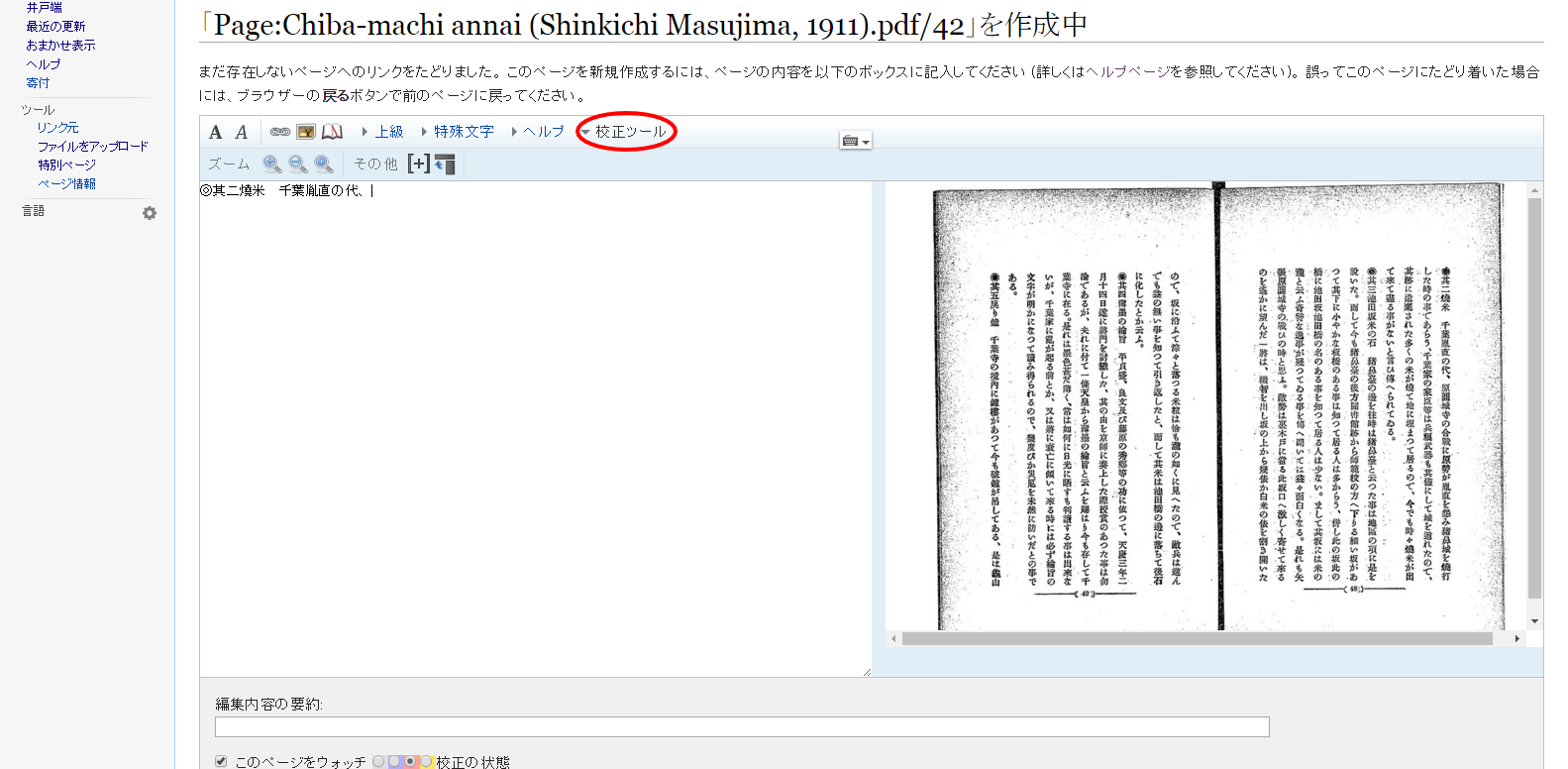
右に画像を見ながら、左側に文字を入力していきます。「校正ツール」をクリックするとズーム(虫眼鏡)ボタンが現れ、画像の表示サイズを調整することができます。
旧字体も正確に転記していきます。(上記の例だと「焼」ではなく「燒」の旧字を入力します)
5.4.2.画像とテキストの分離
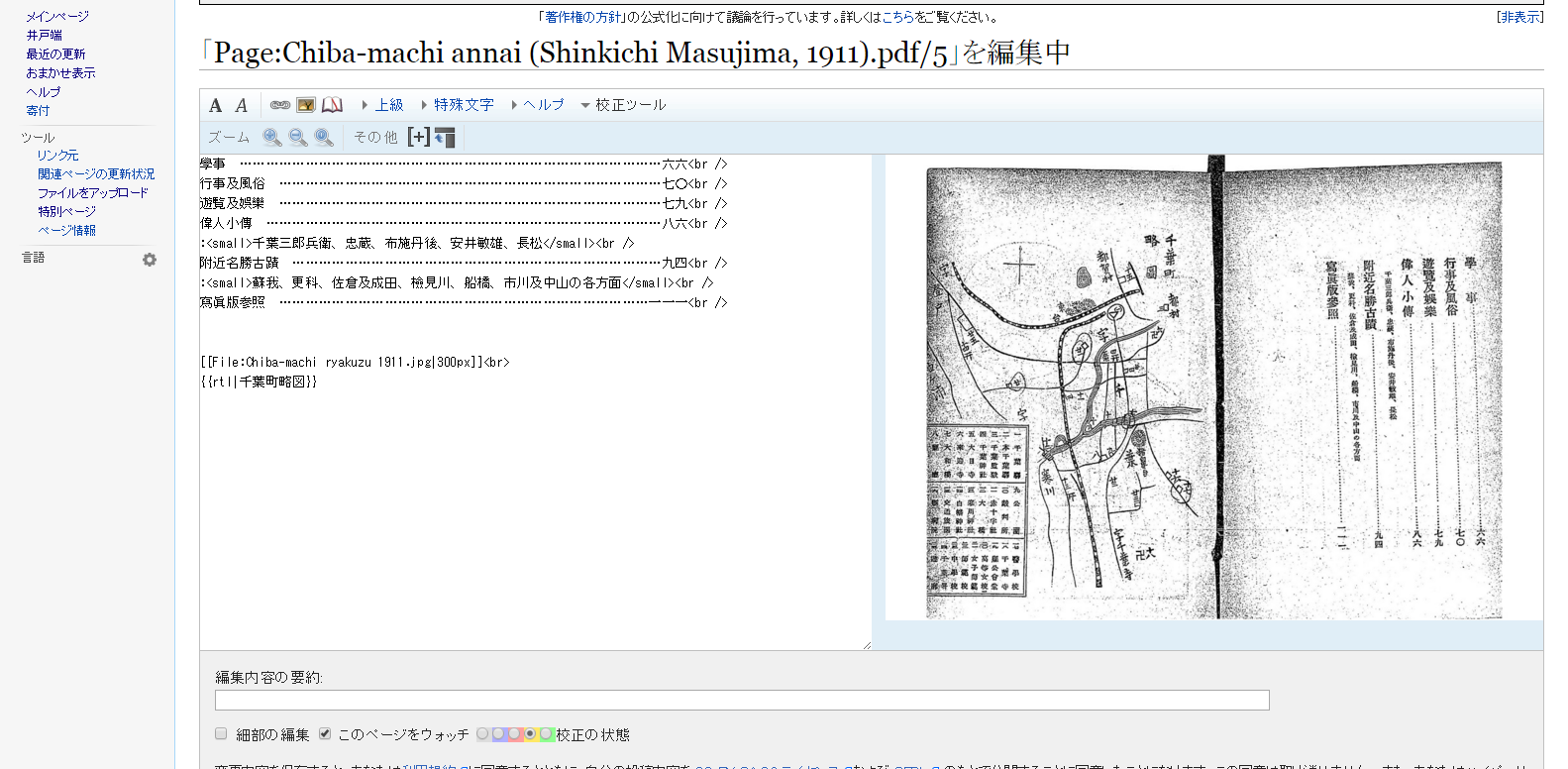
写真や図などの画像が入ったページでは、できるだけ画像と文字を別々に登録します。画像部分はjpegなどの形式にしてWikimedia Commonsに別途アップロードして、上記のように編集画面からリンクを貼ります。
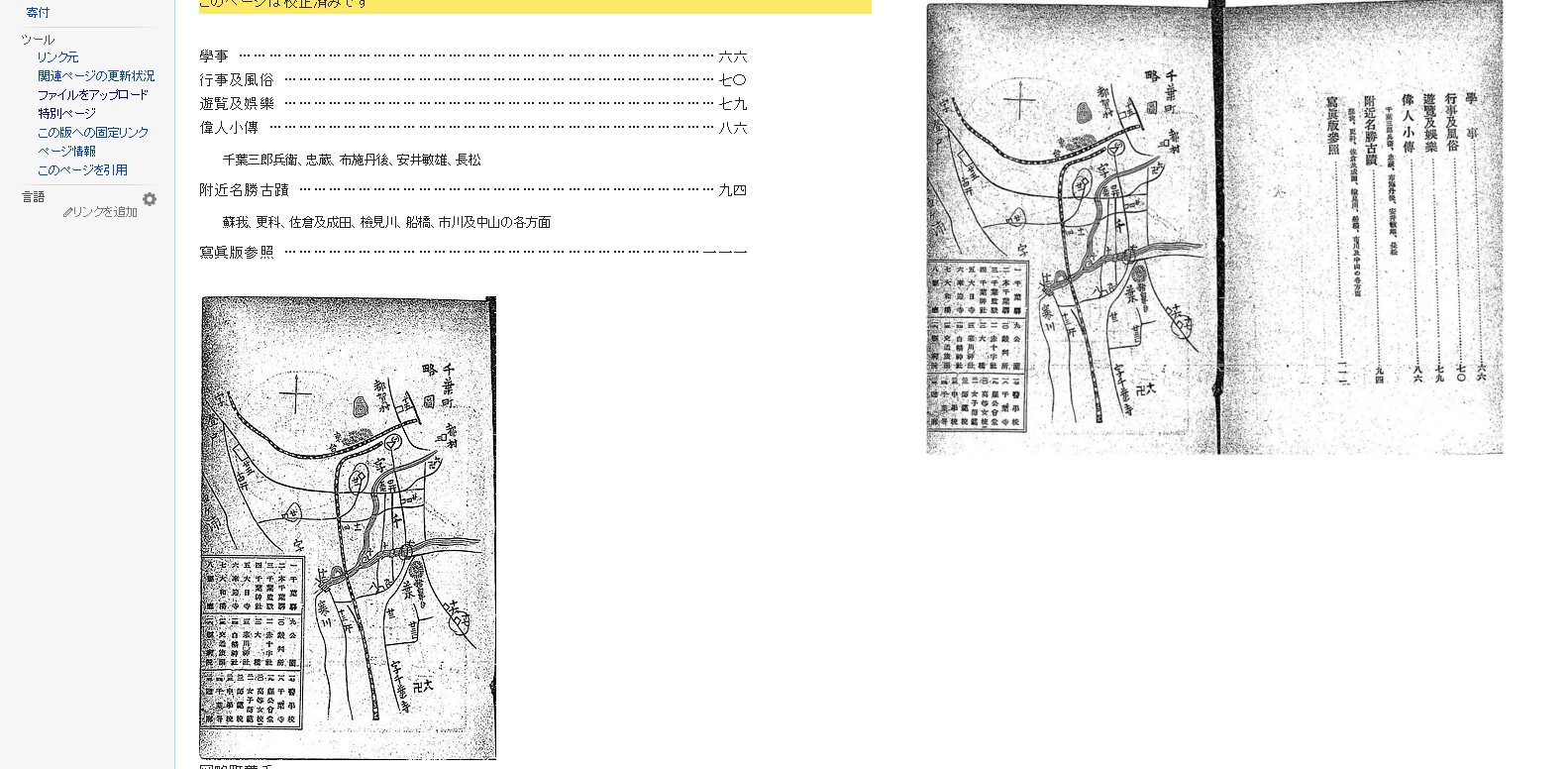
画像と文字を別々に登録することにより、画像だけを利用することもできますし、文字列(上記の例では「千葉町略図」)で検索することもできるようになります。
5.4.3.画像PDFから文字を抽出する方法
デジコレのように底本とするスキャン画像ファイルに文字テキストが無く、単に画像だけという場合、全て手作業で転記するのはかなりの手間がかかります。いろいろ試した結果、Googleドライブを使う方法がいちばん手軽に画像から文字列をOCR抽出できたのでご紹介します。
手順は極めて簡単で2ステップで出来上がりです。
1)画像ファイル(pdf)をGoogleドライブにアップロードします。
2)アップロードしたものを下記のように選択して右クリックして「アプリで開く」、「Googleドキュメント」の順に選びます。
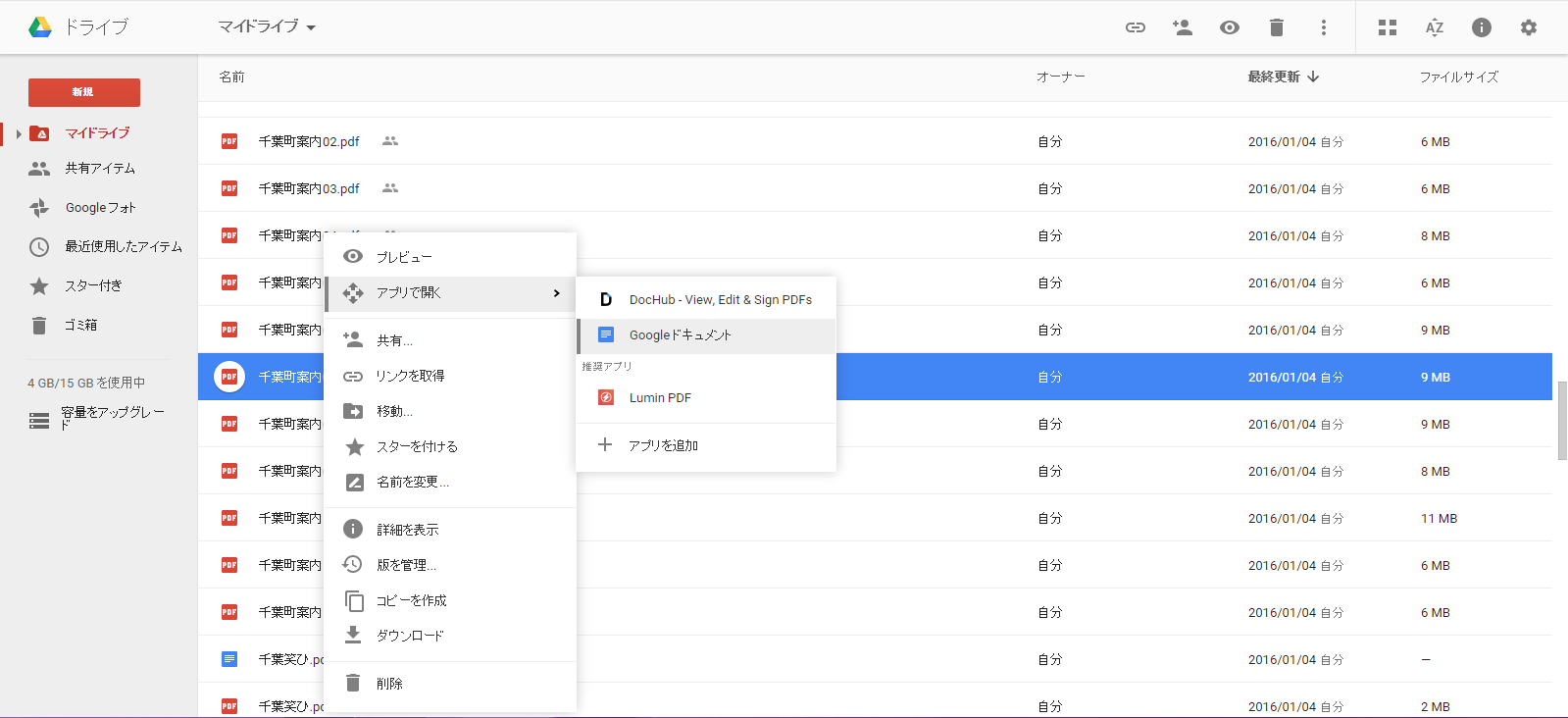
処理中の画面になり、1,2分後に元画像とともに読み取られた文字がテキストとしてGoogleドキュメントに出力されます。

印刷が不鮮明であったり旧字体が多い場合には文字化けも多くなりますが、手作業で転記するよりはかなり楽です。
5.4.4.作業中の例
下記は私が作業中のものです。よろしければ文字起こし作業にご協力ください ;)
5.4.5.作品を公開する
編集および校正作業が終わったら、ウィキソース上にページを作って、作品を公開します。これで出来上がりです。
6.利用できるソースの例
デジコレ以外にも下記のようなサイトに利用できるソースがあります。利用許諾条件の詳細は個々に確認してください。
Please enjoy happy WikiSourcing!