機械学習を勉強しているhibinoだよ
お久しぶりです。院試とかが終わって続きました第二回目。
前回でとりあえず任意の識別が行わせられたぞ! という感じだったと思いますが、まだまだやることはたくさんあります。というのも、まだできているのは2種類の識別ですし、より複雑な識別を行わせていくと、なかなか精度が上がらない! ...といったことが起こってくるからです。
慣れている方は、ネットワークの形を変えてみたり、学習方法やパラメータを変えてみたり、あとは転移学習(できあがっているネットワークを使う)で、精度を上げていますが、まずは前提として必要となるであろうアプローチについて書いていきます。
今回は3種類以上の識別を行わせるための方法と、任意画像の識別結果を確認する方法を、CNNの簡単な解説と併せて、読者の方に理解して頂けるように書いていこうと思います。
1.任意種類の識別を行わせる方法について
今回もゆるゆりプログラムを使って、3種類以上で識別する方法を見ていこうと思います。といってもプログラムをちょちょいと一行変えるだけでできてしまうのですが。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import cv2
import numpy as np
import tensorflow as tf
import tensorflow.python.platform
NUM_CLASSES = 2
IMAGE_SIZE = 28
IMAGE_PIXELS = IMAGE_SIZE*IMAGE_SIZE*3
最初のこの部分のNUM_CLASSESで識別させるタグの数を宣言しています。ゆるゆりプログラムは2種類なので、2が定義されています。実際に同プログラムの下の方を見ていくと、
### 全結合層2の作成
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
や
## ラベルを入れる仮のTensor
labels_placeholder = tf.placeholder("float", shape=(None, NUM_CLASSES))
といった部分などで使われています。weight_variableって何? 全結合層って? ラベルのTensor?? …など。色々疑問はあると思いますが、ひとまず難しいことは抜きにして、この部分さえ変えれば識別させたいタグ(クラス)の数を変えることができる風に書いてくれているようです。
例えば0~9までの手書き文字を画像化したmnistデータを持っている場合、NUM_CLASSES=2からNUM_CLASSES=10と修正して、.txtファイルに画像ディレクトリと0~9までのタグ付けを行えば、識別ができるわけですね。
さて、前回はmnistの0と1の識別を試してみました。この学習はきっと収束したのではないかなと思います。しかし個人的にタグを3種類にしてオリジナルな学習を行わせたとき、ほとんど収束しませんでした。
(自分のやった学習は、固定位置から写真を撮って、物体の大きさを大まかに識別してくれないかなーというものでした)
しかし何度やり直しても正解率は0.35程度を彷徨ったままで、たまに1に収束することもあったのですが、「こんな一目瞭然な識別で、正解率が収束しないのか?」としばらく悩んでいました。
ディープラーニングは人の目で見ても分からないような特徴を捉えてくれる、というところに意味があるのに、単純な大きさも分からないのでは、とても使い物にはなりません。
2.学習を収束させるために.txtファイルを並べ替える
巨乳貧乳識別プログラムの方の記事を見て「もしかして.txtファイルはランダムに並び替えるべきじゃないか?」と考えました。
今まではオリジナルのデータセットを用いて、pythonプログラムを使って一覧を作り、それをCNNに読み込ませていました。その段階での.txtファイルはこんな感じ。
[タグ0の写真] 0
[タグ0の写真] 0
……
[タグ1の写真] 1
[タグ1の写真] 1
……
[タグ2の写真] 2
[タグ2の写真] 2
…
つまり、それぞれの写真がソートされた状態で読み出されていたわけです。
本プログラムは10枚づつ読みだし、ネットワークを変更する。また10枚読み出してネットワークを変更する、という処理を繰り返しています。このままでは最初にタグ0の特徴に特化して、タグ1,2を見分けられないようになってしまっているのではないかと思いました。
なのでこれをランダムに並び替えてみます。下のような1行を追加するだけ。
os.system('cat training-sort.txt | sort -R >training-images.txt')
os.system('rm training-sort.txt')
まずtraining-sort.txtに学習用データセットの情報を書き込んで、その後順序をばらばらにしたものをtraining-images.txtに書き込んでいく感じです。
これで順序はばらばらになったので、再度CNNにかけてみると、0.3付近で止まることなく、かなりスムーズに正解率が1に近づいてくれるようになりました。この手法はどんな学習を行うときにも必須です。
さて、これでめでたしめでたし…としても良いのですが、ネットワークの内部ではどのような事が起こっていたのでしょうか。並び替えた場合とそうでない場合を検証するため、実際のネットワークの状態をTensorBoardを使って可視化してみることにします。
3.ネットワークの構造と畳み込み層の可視化結果
本検証ではmnistの0と1、二種類のタグを判別させるように設定したネットワークを使います。難しい話はいらん!という人は、この章は読み飛ばしてもらって結構です。
具体的には、並び替えが行われたtraining-images.txtで構築したネットワークと、順序をいくつかばらばらにしたネットワークで、ネットワークの中身が変化するかどうかを確かめていきます。ここで行っているTensorBoardでの可視化方法はまた後日記事にまとめようかなと思っていますが、ひとまず結果だけ書いていこうと思います。
可視化を行ったのはCNNのうち畳み込み層のフィルターです。
ここで、畳み込みの処理について少し詳しく書いておきます。
そもそもCNNとは[Convolutional Neural Network]の略で、日本語訳すると(深層)畳み込みニューラルネットワークです。本プログラムでは画像の入力、畳み込み、プーリング、全結合、ソフトマックス関数による正規化の処理に分かれていますが、CNNと呼ばれるネットワークはほとんど、これらの5層によって構成されています。
画像の入力はともかく、他の処理について「???」となる方も多いと思いますので、今回は畳み込み層という部分だけ解説しますね。畳み込みの画像認識における処理について非常に詳しく解説してくれているサイトを以下に紹介します。
けんごのお屋敷-自然言語処理における畳み込みニューラルネットワークを理解する
http://tkengo.github.io/blog/2016/03/11/understanding-convolutional-neural-networks-for-nlp/
本プログラムでは、まず入力層に入力された画像が畳み込み層によって畳み込まれるようになっています。具体的には以下の部分が、CNNの入力層と畳み込み層にあたります。
x_image = tf.reshape(images_placeholder, [-1, 28, 28, 3])
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
x_imageという部分に、画像データが入力されます。
[-1,28,28,3]という部分に注目してください。まず1つ目の-1という部分は無視して構いません。それより大切なのは後者の28,28,3という数値。この部分には画像が入ります。どういうことかと言いますと、つまり[28,28,3]というのは、[縦,横,RGB]という情報を表しています。プログラム内で入力されたRGBによって構成される28*28ピクセルの3色カラー画像が、x_imageという変数に格納されているのがこの部分。
次に、'conv1'と書かれているwith構文を見てみましょう。
ここでは、3つの変数にそれぞれ何かが格納されています。
まずW_conv1ですが、これにはニューラルネットワークでいう"重み"、畳み込みの処理で言うなら"フィルタ"が格納されています。
(フィルタの値は、切断正規分布(正規分布の端を切ったもの)によってランダムに決定されているようです)
b_conv1は、バイアスを意味します。
h_conv1は、ReLU関数によってパーセプトロンの計算を行っていることを意味します。
ここまでで"重み"、"バイアス"、"パーセプトロンの計算"、そして"ReLU関数"という単語が出てきました。これらは一体どういうものなのか? ということですが、これはを理解するためにマカロック-ピッツのモデルを上げておきます。

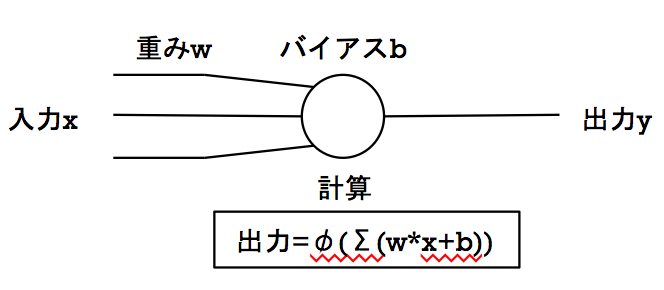
このモデルがディープラーニング、ニューラルネットワークを理解する上で非常に重要な機械学習のモデルです。非常に単純な2層のディープラーニング(ディープとは言ってない) と思って頂ければいいと思います。この例では、上であげたような畳み込みやらプーリングやらは一切行っていません。ですが今後ディープラーニングと呼ばれるものに触れる方は、必ず知っていなければならない部分だと思うので、必要だと思った部分だけ解説します。
まずこのモデルの入力には[0]または[1]という単純な二値が入るものとします。次にそれぞれの入力場所に対する重みを決定します。これが後々、ある入力の集団xに対して出して欲しい出力yを出すために、アルゴリズムで変化させていく場所になっています。今は頭の中で適当な0.0~1.0の間の小数値を想像で入れておいてください。
入力と丸い部分が、画像では3本繋がっていますが、まずは一番上の部分の重みと、入力([0]か[1])を掛け合わせる計算が行われます。この時点で、入力が0なら計算後の値も0となります。1であった場合は、何らかの値が出てきます。例えば重みが0.5であったとすれば計算後の値も0.5となります。さらにここから調整を行うためにバイアスという値を加えて計算を行いますが、今はあまり気にしないでください。
この計算を、全ての入力・重み・バイアスに対して行います。その後、計算した値を全て足し合わせて出した値が、ある一定の数値を超えているかどうかを判別します。それが上の図であるφ(Σ(wx+b))、今回のCNNではReLUと呼ばれている部分で行われている処理です。Σ(wx+b)の値が一定の数値を超えていれば出力y=1、超えていなければy=0というわけです。
それでは、畳み込みの話に戻ります。畳み込み層でもこのような計算が行われているわけですが、ややこしいのは、この入力の部分に[28283]の画像が入るという点です。つまり2352個の入力場所があります。上のモデル入力部がすごくいっぱい並んでるのだと思ってください。
そして入力と出力の間にある重みの部分を計算するわけですが、ここに畳み込みフィルタによって畳み込む、という処理が表現されます。これは画像処理でいうところの畳み込みと全く同じ計算です。
そして最後に、出力をこちらの意図通りにするためのアルゴリズムで計算を行って、この重みやバイアスを調整していきます。
解説が分かり辛かったら申し訳ないです……間違いがあればコメントで指摘していただければ嬉しいです。また、ここに書いた解説は本当に最低限の、肝心のアルゴリズムには全く触れていません。(単層パーセプトロンにおける誤り訂正学習、多層パーセプトロンにおける誤差逆伝播法やReLU関数のグラフなど)
また、実際の入力も0か1ではなく、0~255の値を表現するような正規化された小数値になっているはずです。
詳しい解説はCNNで検索して調べてください。丸投げしてごめんなさい。m(_ _)m
ともあれ、上記のようなモデルがたくさんあって、そこで重みW_conv1、バイアスb_conv1、Relu関数h_conv1といったものでCNN畳み込み層の計算が表現されているという点だけお伝えできていればなと思います。
さらに話を戻します。ゆるゆりネットワークでは、順に以下のように結合しています。
入力層-畳み込み層1-プーリング層1-畳み込み層2-プーリング層2-全結合層1-全結合層2-出力層
このうち入力層-畳み込み層1間では、[28283]の入力画像を[553]の畳み込みフィルタ32枚で畳み込んでいます。その結果、出てくる出力は[28281]の32枚の画像となります。(これをCNNでは特徴マップと呼びます)
今回可視化を行ったのは、畳み込み処理における畳み込みフィルタです。
フィルタを見ることによって、画像のどのような特徴を捉えるようになっているかを知る手がかりになると考えています。
まずはソートを行って学習した場合、以下のような畳み込みフィルタの画像を得ることができました。可視化を行うにあたって、ネットワークは32枚の畳み込みフィルタで畳み込んでいるため、フィルタを見るにはそれぞれ32種類のデータを出力する必要があります。そこでhibinoのプログラムでは以下の画像のように、一枚の画像に32種類のデータを並べて表示してあります。空、と書かれている部分は何も表示されません。

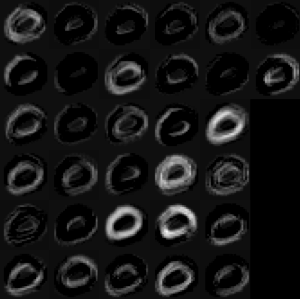
実際にTensorBoardによって可視化した[553]の大きさを持つ32枚のフィルターがこちら。

RGBで表現されています。今回はmnist0,1の分類なので、グレースケールでやったほうがよかったかもしれないですね。
また、W_conv1(ネットワークの重み)についても可視化を行ってみました。
まずはソートせずに学習を行った結果から。
mnistの0の特徴が出ているのが分かります。
では次にソートしなかった場合について。試しに学習段階で読み込ませる順序を以下のように変更して、再度新しくネットワークを構築してみました。
./mnist/test-images/0/im[xxxx].png 0
./mnist/test-images/1/im[xxxx].png 1
./mnist/test-images/0/im[xxxx].png 0
./mnist/test-images/1/im[xxxx].png 1
./mnist/test-images/0/im[xxxx].png 0
./mnist/test-images/0/im[xxxx].png 0
…
そして再度結果表示。

形が変わったのが分かると思います。
さらに0111010000……という風な順番で読み込ませたバージョンも作ってみました。
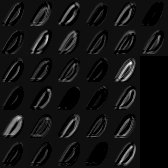
W_conv1を可視化した際に出てきたこれらの結果ですが、ただ単に1枚の画像を32枚のフィルタで分解したものなのか、それとも重みの結合強度を示すものであるのか。
何を可視化したのか自分でも理解できていない状態ですので、わかる方がいればご教授いただければなと思います。
4.おわりに
今回の内容はここまでです。
これで3種類以上の学習にも対応できるようになったのではないかなと思います。
以上、機械学習を勉強するhibinoがお送りしました