kimonoのサービスは終了したようです
WebスクレイパーサービスKimono LabsがPalantirに買収され、サービスは2月末に閉鎖へ
kimonoの仕組み?
kimonoの使い方 基礎編の続きです。
kimonoの動作の流れとしては、
1.スクレイピング
2.kimonolabsサーバに保存
3.kimono APIの呼び出し
4.kimonolabsからデータを取得
のようになっています。
kimono APIを呼び出した時に、対象のWebページに、直接アクセスする訳ではないようです。
なので、kimonoを使って一定時間毎にデータを取得したい時には、"kimonoがスクレイピングするタイミング"と"kimono APIを呼び出すタイミング"に気をつけなければいけないようです。
kimono クローラーの設定
前置きが長くなりましたが、今回は、そんなkimonoのクローラーの設定についてです。
とりあえず、クローラーの設定画面を開きましょう。
CRAWL SETTINGタブです。
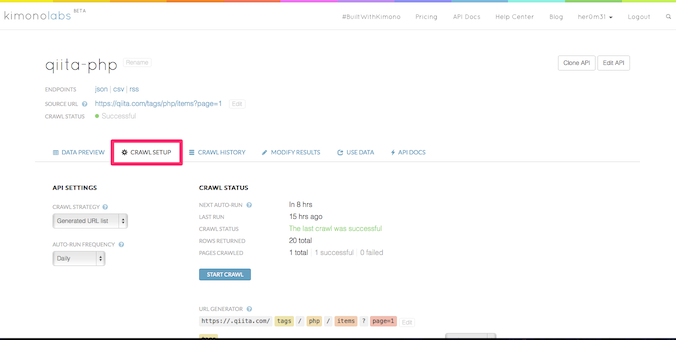
今回は、クローリングのタイミングの設定と、クローリング対象ページの設定を行いたいと思います。
クローリング頻度
kimonoは、どのタイミングでクローリングを行うか決めることができます。
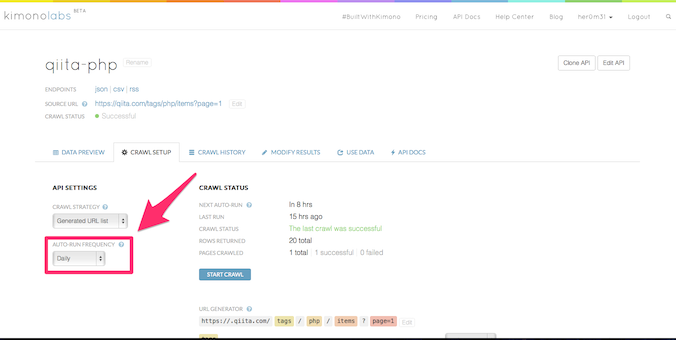
2015/7/16時点では、「手動」「毎時間」「毎日」「毎週」「毎月」のタイミングから選べます。
ちなみに、手動以外は、前回のクローリング実行時を基準としているようです。
クローリング対象URLの設定
クローリング対象は、最初に作成した時のページ以外も指定出来たりします。
左のCRAWL STRATEGYです。
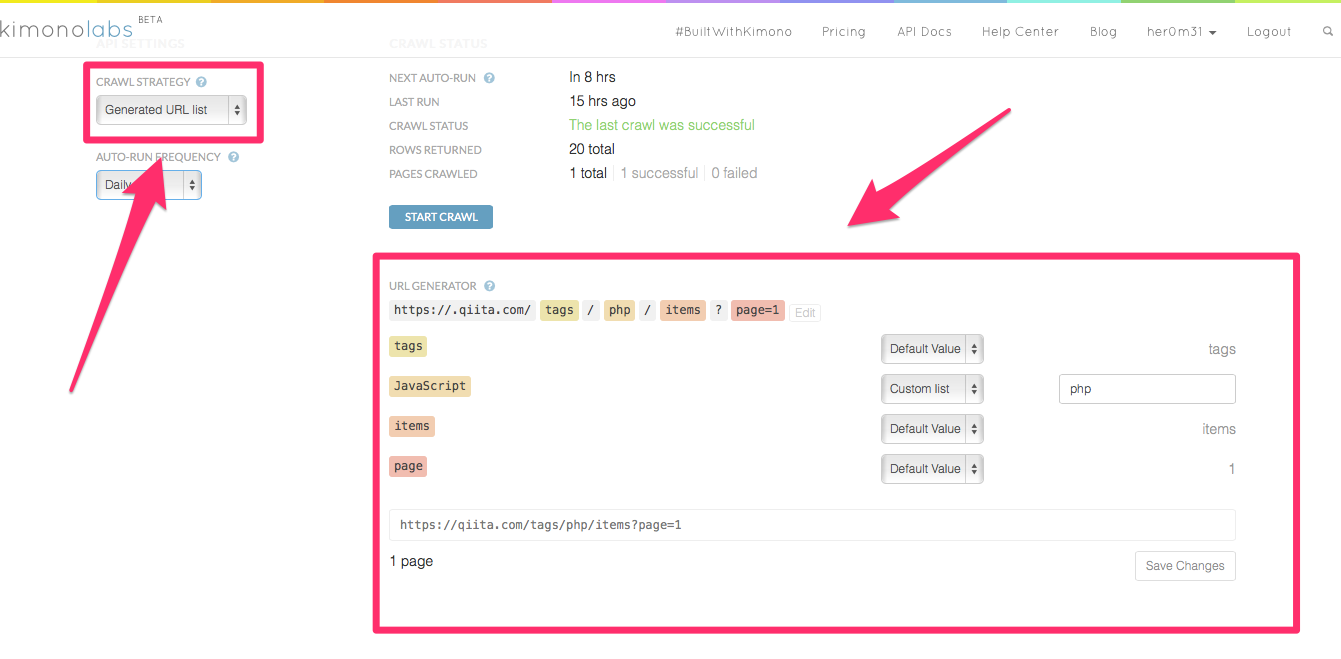
CRAWL STRATEGYのGenerated URL listを選択します。
すると下にURL GENERATERが表示されるので、これを使って設定していきます。
ページ数なんかを設定して、検索結果とか記事一覧とかが複数ページに分かれているときに使うと便利です。
おわり
クローラーの設定をしました。上手く設定できるとアンテナサイトが作れそうな感じがしますね。
そして、実は、クローリングとスクレイピングの定義が曖昧だったりするんですが、良い資料とかあれば教えて頂きたいです。
*kimonoの使い方 基礎編の続きです。