GCPのML系機能を使いまくりたい・・という時にちょうど良い題材があったのでやってみました。GCPは機械学習を行う上で必要なデータ取得、preprocessing、学習と予測まで、フルマネージドな環境が揃っています。今回はその中で以下を使用しました。
- ML Engine
- Dataflow
- BigQuery
- Natural Language API
- Datalab
コードは全てDatalabで実行しました。開発環境を整える必要もなく、インタラクティブに結果を見られるのでGCPのML系を触るときは特におすすめです。
概要
色々発言が注目されるトランプ氏ですが、市場への影響はどれ位でしょうか?ツイートの後と通常(ランダムに時間帯を選択)でUSDJPYの価格変動がどう違うか比較します。
ランダムな日時
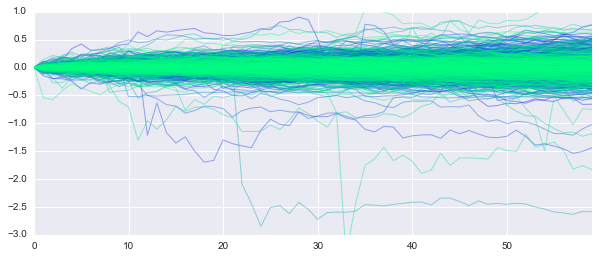
ツイート後
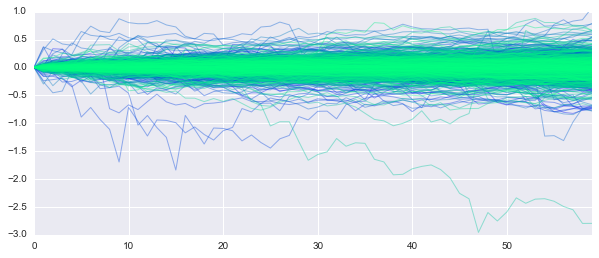
横軸は分、縦軸は変動(円)です。きちんと分散をみていませんが、ツイート後10分は荒れていますね。そこで今回は氏のツイート内容を感情分析し、その結果と為替の変動を学習し予測します。
1. Twitter APIでツイートを取得する
API自体は色んな方が紹介されていますね。早速トランプ氏のタイムラインを取得しましょう。まずはユーザー名を検索します。"donald trump"っと。
・・・何という事でしょう!同姓同名どころか、オレンジ色の顔まで同じ人がこんなにいるなんて・・・
とりあえず本物と自称しているrealDonaldTrumpさんのツイートでも取得してみます。*POTUSの方は本人がツイートしてるわけじゃなさそうなのでパス
def fetch_tweets(screen_name):
from twitter import Twitter, OAuth
from datetime import datetime
import pytz
token = '{token}'
token_secret = '{token_secret}'
consumer_key = '{consumer_key}'
consumer_secret = '{consumer_secret}'
t = Twitter(
auth=OAuth(token, token_secret, consumer_key, consumer_secret),
retry=True)
max_count = 200
kwargs = {'screen_name':screen_name,
'count':max_count}
while True:
result = t.statuses.user_timeline(**kwargs)
if len(result) == 0:
break
for r in result:
tm = datetime.strptime(r['created_at'],
'%a %b %d %H:%M:%S +0000 %Y').replace(tzinfo=pytz.UTC)
yield {'time': tm.strftime('%Y-%m-%d %H:%M:%S'),
'text': r['text'],
'tid': r['id']}
kwargs['max_id'] = result[-1]['id']
max_idで数珠繋ぎにPagingを繰り返します。Over Quota時のリトライはライブラリ側で勝手にやってくれるようです。
2. トランプ氏の感情を分析する
怒ってるだけでしょ?と思うなかれ、ツイートの内容から氏の感情を分析してみます。
感情分析自体はQiitaでも多くの方が書かれているので細かい話は書きませんが、ちゃんとやろうと思うと結構大変です。(ちゃんとやりたい方はこの辺に学習データが置いてあるのでチャレンジしてみてください)
今回はGCP ML系使いこなしなのでCloud Natural Language APIを使ってみます。
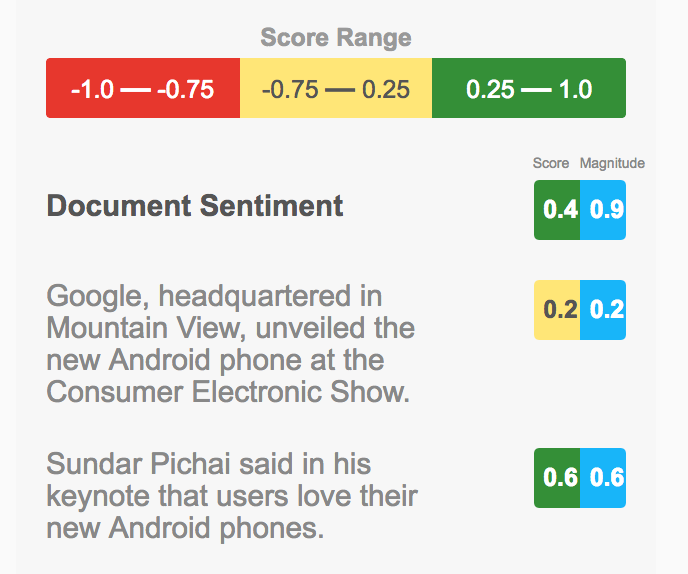
こちらのAPIはただテキストを渡せば感情をスコアで返してくれるので楽チンです。Scoreがプラスだとポジティブ、マイナスだとネガティブな文章と判断になり、Magnitudeはその強さの指標となります。こちらの公式ブログによると文章中の感情値の発生数により増加するとあります。
def analyze_sentiment(row):
import time
from google.cloud import language
# Instantiates a client
language_client = language.Client()
# The text to analyze
document = language_client.document_from_text(row['text'])
# Detects the sentiment of the text
while True:
try:
sentiment = document.analyze_sentiment().sentiment
break
except:
time.sleep(100)
ret = {'score': sentiment.score,
'magnitude': sentiment.magnitude}
ret.update(row)
return ret
ほぼサンプルそのままです。100秒あたりのリクエスト数制限があるため、APIがエラーしたらウェイトを入れてリトライさせます。(後述するDataflowで並列に実行する場合は注意が必要です。急にウェイトが入るとタスクの実行時間推定が大きくバラつき、パフォーマンスが落ちる場合があります。今回はworker数を抑えているので安直にこうしています。)
3. BigQueryに結果を保存する
1-3はDataflowで一気に実行します。
(p | 'user name' >> beam.Create(['realdonaldtrump'])
| 'fetch tweets' >> beam.FlatMap(fetch_tweets)
| 'analyze sentiment' >> beam.Map(analyze_sentiment)
| 'write to bq' >> beam.Write(beam.io.BigQuerySink('twitter.trump',
schema="tid:INTEGER, text:STRING, time:DATETIME, score:FLOAT, magnitude:FLOAT",
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED))
)
p.run() #.wait_until_finish()
はじめにユーザー名を指定すると、Twitterのタイムラインを取得し、NL APIで解析結果を付加しBigQueryに格納するまでを一気に行えます。これで「そのオレンジは本物じゃない!」と言われても安心です。ユーザー名を書き換えて実行し直せば良いだけですからね。
実行結果は以下のようになりました。
意外と早く終わったなぁと思ったら、Twitter APIでタイムラインは過去3200件までしか遡れないようです。氏のタイムラインだとちょうど1年分でした。
4. 分析結果を少しみてみる
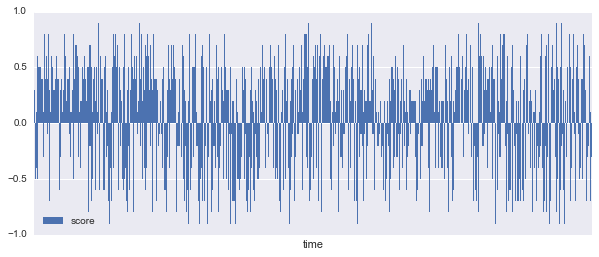
感情分析したので、時系列的に傾向があるかどうかプロットして確かめてみます。縦軸が上に行くほどポジティブ、下に行くほどネガティブです。一年前(2016年4月頃、チャート左側)は割とポジティブですが、全体的にはネガティブな発言も多いようです。
参考までに、オバマ前大統領の場合。
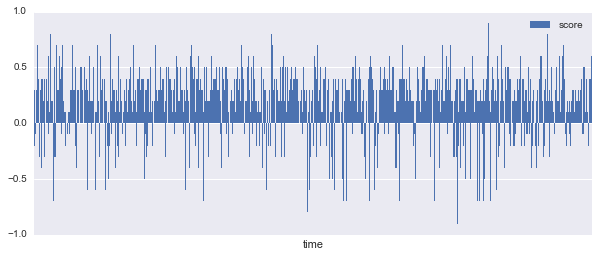
はい、ほぼポジティブですね。ツイート数が違うので期間は異なります(2014/7/31〜)が、正確に比較するまでもないでしょう。
トランプ氏のツイートに戻ります。
ちなみに一番ポジティブな発言は何でしょうか?BigQueryで調べてみます。
SELECT * FROM [twitter.trump] WHERE score > 0 ORDER BY magnitude DESC
A fantastic day in D.C. Met with President Obama for first time. Really good meeting, great chemistry. Melania liked Mrs. O a lot!
— Donald J. Trump (@realDonaldTrump) 2016年11月11日
オバマ前大統領と会った時のツイートですね。確かにべた褒め。
次にネガティブですが・・
FAKE NEWS media knowingly doesn't tell the truth. A great danger to our country. The failing @nytimes has become a joke. Likewise @CNN. Sad!
— Donald J. Trump (@realDonaldTrump) 2017年2月25日
NYタイムズとCNNをディスってるツイートです。これ実はscoreは-0.3なのでまだまだ上があります。過激なので転載しません。。
さて、次は学習です。
5. モデル学習
特徴データにはScoreとMaginitudeを、ラベルはツイート後10分の価格変動上下2クラスとします。
特徴もデータ数も少ないので小さめのDNNでいいでしょう。こちらで紹介したMagicコマンドを使うとDatalabから学習ジョブをCloud ML Engineに投げられます。
import tensorflow as tf
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=2)]
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=2,
model_dir="./trumpmodel")
classifier.fit(x=x_train,
y=y_train,
steps=2000,
batch_size=50)
と、ここまでやっておいて学習するならやっぱりコーパスから特徴ベクトル作った方が良かったかなぁと後悔。でも一応ジョブを流してみました。
・・・うーん、学習が進みませんでした。感情分析結果をそのまま使ってトレードした方がまだ良さそうです。
例えばMagnitudeが1以上の時にLongした場合の資産推移。
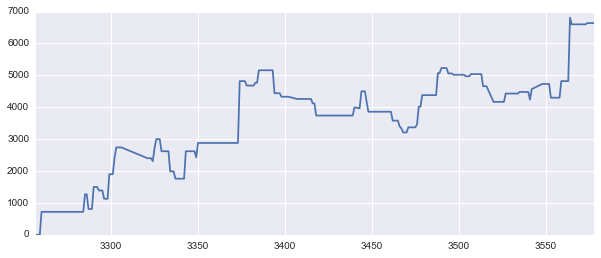
一応右肩上がりにはなりました。
まとめ
今回、題材は置いておいてシステムとしては機械学習のフローでベースとなるような構成になったのではないかと思います。
GCPは機械学習のベストプラットフォーム!だと信じてやまない私ですが、利用者が増えて色んな使い方がシェアされるといいですね。