Googleの虎の子BigQueryをFluentdユーザーが使わない理由はなくなったとのこと。
よし、Google BigQueryを使って超高速ログ解析だ!!!!と思っているとそこまでの道のりは長かった。
Google BigQueryの環境を構築する
Google BigQueryはGoogle Cloud Platformのサービスの1つである。Google Cloud Platformには様々なサービスがあり、統合されているような、されていないような作りになっている。AWSのWebインターフェースも難しいけど、Google Cloud Platformもよくわからないので覚悟してかかろう。公式のドキュメントも記述が古いときもあるので疑ってかかろう。
プロジェクトを作成する
Google BigQueryを使用するにはGoogle Developers Consoleからプロジェクトを作成する必要がある。Google Cloud Platformの他のサービスを既に使用している場合はそのプロジェクトを使い回しても問題ない。
プロジェクトを作成するにはプロジェクト名とプロジェクトIDが必要である。このプロジェクトIDは後から変更できず、BigQueryでもよく記入することになるので、良い感じのプロジェクトIDを指定しよう。
Google BigQueryは処理データ量には無料枠が用意されているが、ストレージ自体は有料であるため、課金を有効にしないと使用することができない。予めプロジェクトの課金を有効にしておこう。Google BigQueryを無料で試せると思っていたユーザは諦めよう。
課金を有効にするにはプロジェクトの設定画面から課金を有効にする。クレジットカードによる決済が利用できる。
bqコマンドをインストールする
Google BigQueryはWebインターフェースから操作できるが、実際できないことも多い。空のテーブル作成とかできないので、HTTP APIか専用のCLIコマンドであるbqを使用して操作することになる。API経由ですべての処理を行うのは大変なのでbqコマンドをインストールしよう。
Google Cloud SDKをインストールする
bqコマンドはGoole Cloud SDKに含まれている。下記ページからダウンロード、インストールしよう。
zshのPATHを通してくれるシェルスクリプトは筆者の環境ではうまく動かなかった。結局google-cloud-sdk/binにPATHが通っていれば問題ない。PATHを通すには.bashrcや.zshrcみたいなファイルに次のように追記すれば良い。
export PATH=/Users/harukasan/google-cloud-sdk/bin:$PATH
インストール先もホームディレクトリである必要はない。共用環境などでは適切な位置に配置しよう。
アカウント認証を行う
Google Cloud SDKはOAuthによるAPI認証を行う。アカウント認証を行うには次のコマンドを実行する。ブラウザが開いた場合はそこで認証を行い、開かなかった場合は指定されたURIを開き、認証を行う。
$ gcloud auth login
認証を行ったアカウントは次のコマンドで確認することができる。
$ gcloud auth list
コマンドの確認
bqコマンドが実行できるか確認しよう。ヘルプが表示されれば問題ない。
$ bq
Python script for interacting with BigQuery.
USAGE: bq.py [--global_flags] <command> [--command_flags] [args]
...
プロジェクトが利用可能かどうかは次のコマンドで確認できる。
$ bq ls
projectId friendlyName
----------------- --------------
your-project-id your-project
BigQueryを準備する
さて、ここまででGoogle BigQueryを利用可能な環境が整ったはずだ。続いてBigQuery側の準備をしよう。FluentdからBigQueryに入力するには、今のところ、予めテーブルを作成しておく必要がある。
データセットを作成する
BigQueryにはデータセットとテーブルという概念がある。データセットには複数のテーブルが所属し、データセットごとに権限の指定ができる。
データセットを作成するには、Webインターフェースから操作するか、次のbqコマンドを実行する。
$ bq mk your-project-id:your_dataset
Webインターフェースから操作する場合は、プロジェクト名右の メニューの
メニューのCreate new datasetからデータセットを作成できる。
テーブルを作成する
BigQueryでは予めテーブルスキーマを決定しておく必要がある。スキーマの指定には、リスト形式で指定する方法とJSON形式で指定する方法があるが、JSON形式にしておくとFluentdの設定にもそのまま使用することが出来るので便利だ。Fluentdからログを入力する場合、ログのスキーマとテーブルスキーマが一致していなければならないので注意しよう。
リスト形式で指定する場合、ネストしたデータを扱うことが今のところ出来ない。Webインターフェースではファイルを指定してロードすることしか出来ないが、スキーマ指定はリスト形式でしか行えないため、Webインターフェースからネストしたデータを扱う方法も今のところない。
スキーマのJSONは次のような感じになる。指定できるデータ型には、STRING、INTEGER、FLOAT、BOOLEAN、RECORDがある。RECORDの場合はfields属性にネストするフィールドを指定する。
[
{
"name": "time",
"type": "INTEGER"
},
{
"name": "uri",
"type": "STRING"
},
{
"name": "request",
"type": "RECORD",
"fields": [
{
"name": "addr",
"type": "STRING"
},
{
"name": "ua",
"type": "STRING"
},
{
"name": "referrer",
"type": "STRING"
}
]
}
]
スキーマを記述したらbqコマンドを実行しテーブルを作成する。
$ bq mk -t your-project-id:your_dataset.your_table ./schema.json
Table 'your-project-id:your_dataset.your_table' successfully created.
作成したテーブルは次のコマンドで確認することが出来る。また、Webインターフェースでも確認できる。
$ bq show your-project-id:your_dataset.your_table
存在するテーブルを確認するにはbq lsコマンドを実行すれば良い。
$ bq ls your-project-id:your_dataset
FluentdからBigQueryにログを挿入する
FluentdからBigQueryにログを挿入するには@tagomorisさんがつくったfluent-plugin-bigqueryを使う。適切な方法を用いてインストールしておこう。
認証キーを取得する
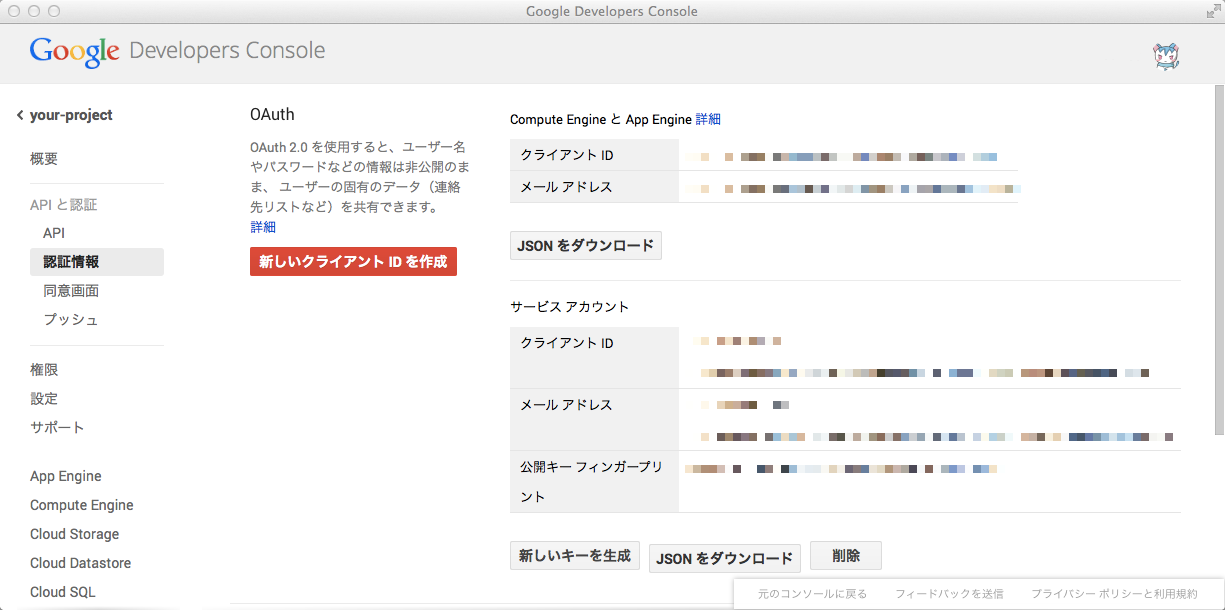
FluentdをCompute Engine以外で実行する場合は鍵認証が必要になる。鍵認証を行うには、Google Developer Consoleからサービスアカウントを作成する。
サービスアカウントの作成はプロジェクトのコンソールの認証情報画面で行う。作成するには、OAuthの新しいクライアントIDを作成をクリックし、サービスアカウントを選択する。発行が完了すると、画面上にクライアントID、メールアドレス、フィンガープリントが表示され、鍵ファイルがダウンロードされる。
Fluentdを設定する
サービスアカウントが発行できたらFluentdの設定を行う。出力する部分の設定は次のようになる。
<match access.log>
type bigquery
method insert
auth_method private_key
email XXXXXXXXXXXX@developer.gserviceaccount.com
private_key_path ./XXXXXXXXXXXX-privatekey.p12
project your-project-id
dataset your_dataset
table your_table
time_format %s
time_field time
schema_path ./your_table_schema.json
</match>
認証
認証には先ほど取得したサービスアカウントのメールアドレスと鍵ファイルを使用する。メールアカウントと鍵ファイルはそれぞれemail、private_key_pathディレクティブに指定する。
auth_method private_key
email XXXXXXXXXXXX@developer.gserviceaccount.com
private_key_path ./.keys/XXXXXXXXXXXX-privatekey.p12
テーブル
挿入するテーブルは次のディレクティブで指定する。tableディレクティブの代わりにtablesディレクティブを用いると、複数テーブルの指定が可能になり、レコードがシャーディングされる。インサート数がGoogle BigQueryの制限にかかってしまう場合に有効だ。
project your-project-id
dataset your_dataset
table your_table
スキーマ
スキーマはリスト形式でも指定できるが、先ほど使用したJSONファイルを指定するだけで良い。JSONファイルはschema_pathディレクティブに指定する。
time_format %s
time_field time
schema_path ./your_table_schema.json
time_formatでは時刻のフォーマットを指定するが、BigQueryにはTIMESTAMP型は存在しないため、unix epochを指定する。unix epoch形式で挿入しておけばクエリで後から変換が可能だ。時刻のフィールドはtime_fieldで指定する。このフィールドもスキーマに含まれている必要がある。
クエリを発行する
さて、Fluentdによるログの挿入が出来たら実際にクエリを発行してみよう。クエリの発行にはAPIを使用する方法、Webインターフェースを用いる方法、そしてbqコマンドを使用する方法がある。
Webインターフェースからクエリを発行する
Webインターフェースからクエリを発行するには、テーブルを選択し、右上のQuery Tableボタンか、COMPOSE QUERYからクエリ入力画面を開く。
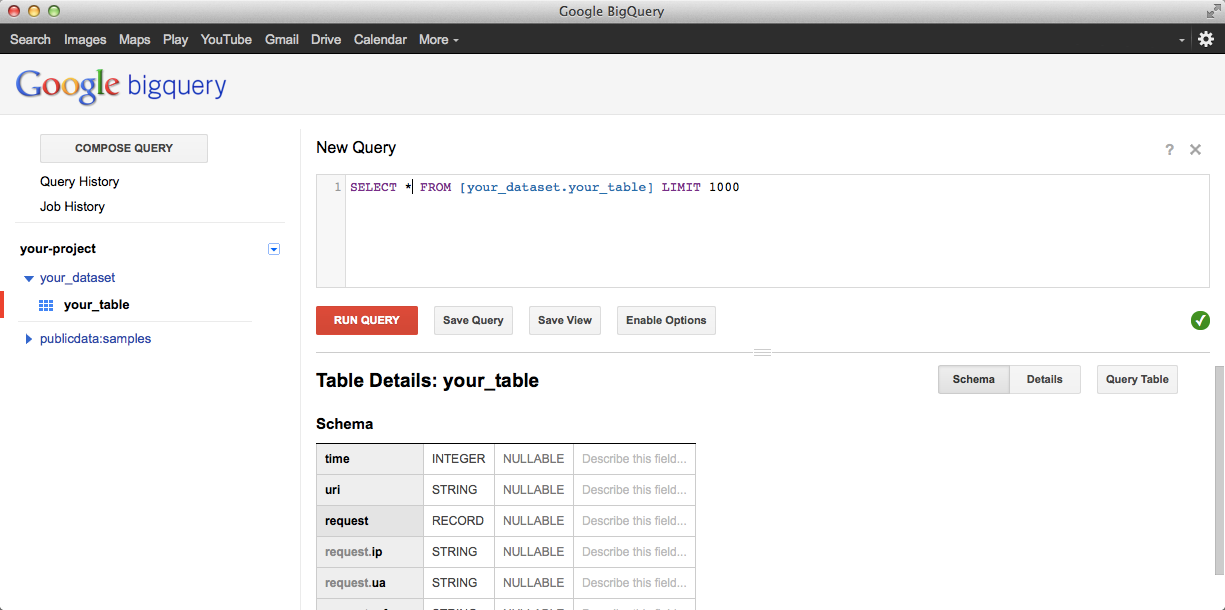
Enable Optionsから出力先のテーブルを指定したり、キャッシュの有効・無効、クエリの優先度を指定することが出来る。また、右のチェックマークをクリックすることで、クエリを発行することでどれだけのデータ量を処理するかを教えてくれるので、課金される前に確認するようにしよう。
bqコマンドからクエリを実行する
bqコマンドからクエリを実行するにはbq queryコマンドを用いる。
$ bq query --project_id your-project-id "SELECT * FROM your_dataset.your_table LIMIT 1000"
--dry_runオプションを指定することで、実際にクエリを発行する前にクエリの確認を行うことが出来る。
$ bq query --project_id your-project-id --dry_run "SELECT * FROM your_dataset.your_table LIMIT 1000"
Query successfully validated. Assuming the tables are not modified, running this query will process 0 bytes of data.
実行結果は標準出力に出力されるが、--formatオプションを指定することで、JSON、CSV形式での出力も可能である。
$ bq query --format cdv --project_id your-project-id "SELECT * FROM your_dataset.your_table LIMIT 1000"
フォーマットには現在のところ、次の種類が指定できるようだ。
--format <none|json|prettyjson|csv|sparse|pretty>
まとめ
この記事ではGoogle Cloud Platformに登録し、Google BigQueryを使い始め、Fluentdからログを挿入し、実際にクエリを実行するまでを紹介した。実際つらい道のりであったが、まだクエリを実行できただけで、ログ解析の道のりはここからである。
プロダクションのログを用いて検証しているが、ログの挿入、クエリの実行は確かに高速である。TreasureDataと違い、クエリのスケジューリング等は標準で提供されておらず、基本的にはAPI経由で使用することになる。Google Apps Scriptを用いれば、Spreadsheetへの出力や、スケジューリングも行うことが出来る。日本語のドキュメントは殆どないので、Qiitaに記事が増えてくれるとうれしい。