Google Cloud Dataflowがpublic betaになってから試してみたいと思っていたので、ようやく試してみることにした。Google Cloud Dataflowが何なのか知りたい時は次のスライドを読むと良い。
必要なもの
- Google Cloud Platformのアカウント
- Java 8
- Maven
Java 7では動かなかった気がするので、Java 8をあらかじめダウンロードしておこう。MavenはMac環境であればHomebrewでインストールできる。
Dataflow APIを有効にする
あらかじめDataflow APIをGCPのコンソールから有効にしておこう。コンソールのUIが変わっててちょっとびびったけど、検索できるので簡単に見つかる。
Dataflow SDK for Java をセットアップする
Google Cloud DataflowのSDKはGithubで公開されているのでこれをcloneしてくる。
$ git clone git@github.com:GoogleCloudPlatform/DataflowJavaSDK.git
SDKのビルドはmvnコマンドで実行できる。時間がかかるのでしばらく待とう。
$ mvn clean install
[INFO] Scanning for projects...
...
[INFO] Reactor Summary:
[INFO]
[INFO] Google Cloud Dataflow Java SDK - Parent ............ SUCCESS [ 0.475 s]
[INFO] Google Cloud Dataflow Java SDK - All ............... SUCCESS [02:36 min]
[INFO] Google Cloud Dataflow Java Examples - All .......... SUCCESS [ 12.342 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 02:49 min
[INFO] Finished at: 2015-05-28T18:17:45+09:00
[INFO] Final Memory: 90M/773M
[INFO] ------------------------------------------------------------------------
成功するとこんな感じで表示される。これでサンプルのプログラムが実行できるようになったはずだ。
WordCountを実行してみる
サンプルプログラムのWordCountを実行してみよう。シェイクスピアのテキストから単語ごとにカウントするよくあるやつだ。BigQueryでいうとこんなかんじ(データセットは違うかも)。
SELECT
COUNT(word) AS count,
word
FROM [publicdata:samples.shakespeare]
GROUP BY word
ステージングと出力先のバケットを用意する

Cloud Dataflowではコンパイル済みのjarと結果の出力先としてGoogle Cloud Storageを使用する(出力先はBigQueryに変えることもできる)。あらかじめ出力先のバケットを用意しておこう。バケットはgsutilコマンドで用意しても良いし、コンソールから作っても良い。
クレデンシャルファイルを用意する
GCEのインスタンス外で動かすと次のようなエラーが出力される。
[ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.1:java (default-cli) on project google-cloud-dataflow-java-examples-all: An exception occured while executing the Java class. null: InvocationTargetException: Failed to construct instance from factory method com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner#fromOptions: Unable to get application default credentials. Please see https://developers.google.com/accounts/docs/application-default-credentials for details on how to specify credentials. This version of the SDK is dependent on the gcloud core component version 2015.02.05 or newer to be able to get credentials from the currently authorized user via gcloud auth. The Application Default Credentials are not available. They are available if running in Google Compute Engine. Otherwise, the environment variable GOOGLE_APPLICATION_CREDENTIALS must be defined pointing to a file defining the credentials. See https://developers.google.com/accounts/docs/application-default-credentials for more information. -> [Help 1]
このエラーはクレデンシャルファイルのパスを環境変数GOOGLE_APPLICATION_CREDENTIALSに渡すことで解決できる。クレデンシャルファイルはコンソールから新たにクライアントIDを発行することで取得できる。クレデンシャルファイルがあればすべてのGCPのAPIが利用できてしまうので、外部に漏洩しないように扱いには気をつけよう。
ダウンロードしたJSONファイルのパスをGOOGLE_APPLICATION_CREDENTIALSにセットする。
ジョブを実行する
ここまでで前準備は完了だ。ステージングと出力先のバケットを指定してWordCountを実行してみよう。
$ export GOOGLE_APPLICATION_CREDENTIALS=/Users/harukasan/****.json
$ PROJECT="(プロジェクト名)"
$ STAGING="gs://dataflow-testing-staging/wordcount"
$ OUTPUT="gs://dataflow-testing-output/wordcount"
$ mvn exec:java -pl examples \
-Dexec.mainClass=com.google.cloud.dataflow.examples.WordCount \
-Dexec.args="--project=${PROJECT} \
--stagingLocation=${STAGING} \
--runner=BlockingDataflowPipelineRunner \
--output=${OUTPUT}"
[INFO] Scanning for projects...
...
実行中は端末にもなにを実行しているか表示されるし、コンソールでもグラフィカルにログを見たりすることができる。実際にバッチをスケジューリングして動作させている時には便利かもしれない。
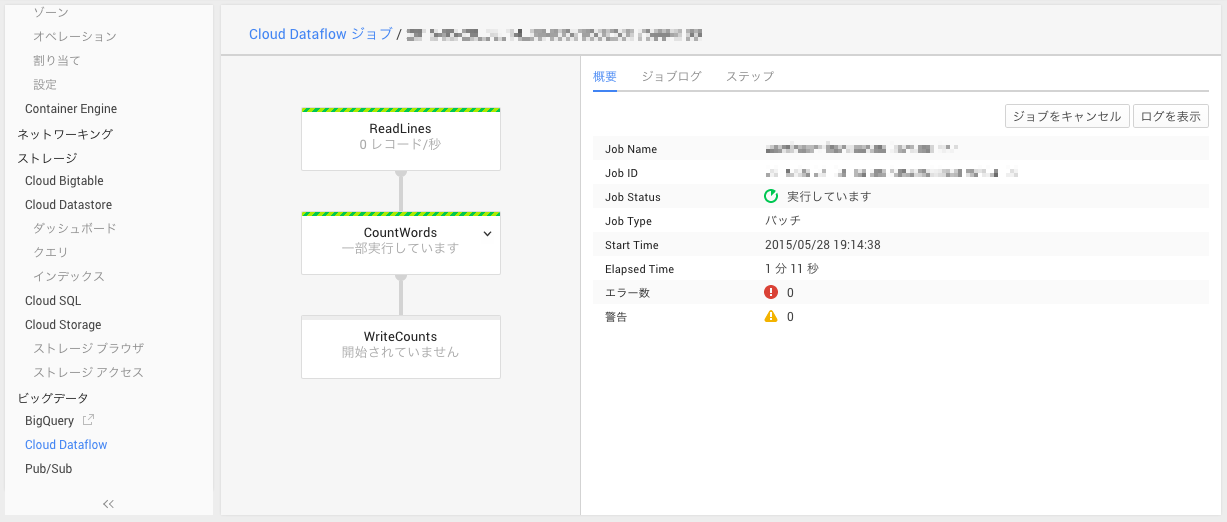
結果はGoogle Cloud Storageに出力されているのでコンソールで確認してみよう。
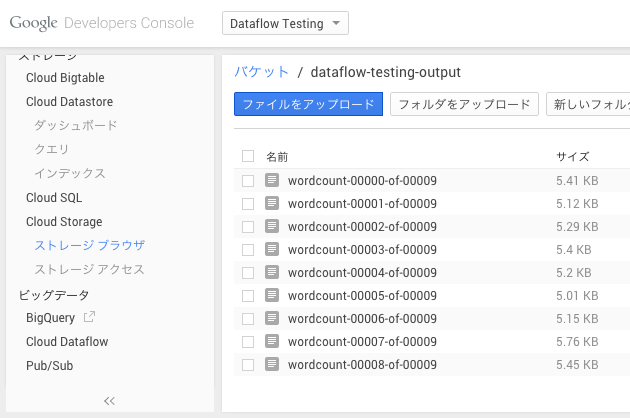
それぞれのテキストファイルには各行にワードごとのカウントが記録されている。
stoops: 1
knapped: 1
was: 46
sense: 5
vassal: 1
graves: 1
building: 1
shadowy: 1
...
WordCountは何をやっているのか
せっかくなのでWordCountは何をしているのか見てみよう。main()の処理は次のようになっている。
public static void main(String[] args) {
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.named("ReadLines").from(options.getInput()))
.apply(new CountWords())
.apply(TextIO.Write.named("WriteCounts")
.to(options.getOutput())
.withNumShards(options.getNumShards()));
p.run();
}
ここでは、パイプラインを作成し、いくつかのオブジェクトをapplyに渡している。TextIOはテキストファイルの読み書きをするためのユーティリティで、Google Cloud Storageからの読み書きを簡単に記述できる。
実際の集計を行っているのはCountWordsクラスだ。CountWordsクラスはPTransform<PCollection<String>, PCollection<String>>を継承している。Dataflow SDKではPTransformを継承してデータをtransformする処理を記述する。
public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> {
private static final long serialVersionUID = 0;
@Override
public PCollection<String> apply(PCollection<String> lines) {
// 1行からワードを抽出する
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// ワードをカウントする
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
// ワードとカウントごとに出力する文字列にフォーマットする
PCollection<String> results = wordCounts.apply(
ParDo.of(new FormatCountsFn()));
return results;
}
}
Dataflow SDKではデータをPCollectionクラスで表現する。PCollectionはIntegerやStringといったデータを複数格納するデータセットで、PCollectionのapplyメソッドに処理を行うオブジェクトを渡すことでデータの変形を行う。
行からワードを抽出する
例として行からワードを抽出する処理を見てみよう。linesのapplyメソッドに対しParDo.of(new ExtractWordsFn())を渡している。ParDoはCloud Dataflowにおいて並列処理を行うためのコアとなる仕組みで、MapReduceにおけるMapperに近い処理を行う。つまり、入力されたPCollectionを要素ごとに分散し、処理を実行してくれるわけだ。ParDoを使うことで、行ごとに分散して単語に分割する処理を行うことができる。
ParDoにはDoFnを継承したクラスのオブジェクトを渡す。ExtractWordsFnの実装を見てみよう。DoFn<String, String>はStringを入力し、Stringを出力する処理を示す。要素の処理はprocessElementメソッドで行う。ここでは正規表現による分割が行われていることがわかる。
static class ExtractWordsFn extends DoFn<String, String> {
private static final long serialVersionUID = 0;
private final Aggregator<Long, Long> emptyLines =
createAggregator("emptyLines", new Sum.SumLongFn());
@Override
public void processElement(ProcessContext c) {
// Keep track of the number of empty lines. (When using the [Blocking]DataflowPipelineRunner,
// Aggregators are shown in the monitoring UI.)
if (c.element().trim().isEmpty()) {
emptyLines.addValue(1L);
}
// Split the line into words.
String[] words = c.element().split("[^a-zA-Z']+");
// Output each word encountered into the output PCollection.
for (String word : words) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}
Aggregatorは集計に使うクラスで、ここでは空行を集計するためにAggregatorを用いている。Aggregatorの値はコンソールから確認することができる。
ワードごとにカウントする
ワードごとにカウントを行っているのはCountだ。Dataflow SDKでは、CountやSumなどよく使う集計処理がいくつか定義されていて簡単に利用できる。
// ワードをカウントする
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
まとめ
本稿ではGoogle Cloud Dataflow上でサンプルプログラムを動かすまでの簡単な流れと、サンプルプログラムのWordCountが何をやっているのか簡単に説明した。実際にどのようにプログラムを記述するかはDataflow Programming Modelを読むとなんとなく雰囲気がわかるかと思う。
BigQueryからの入出力を行うBigQueryTornadoesや、スライドで紹介されているオートコンプリートを行うAutoCompleteなどいくつかのサンプルプログラムもSDKに付属しているので、これを読むのも良いかもしれない。次回があれば、これらのサンプルプログラムを紹介するか、実際にCloud Dataflowでプログラムを作成する方法を紹介するかもしれない。