Nutanix Advent Calendar 2015,12月21日分としての投稿になります。
本記事の内容はこの日付時点の情報(ce-2015.11.05-stable)に基づいています。そのため,今後新しいバージョンが提供された場合に,当該記載と矛盾が生じる場合がありますのでご注意ください。また,さわりはじめたばかりで認識誤り等があるかもしれません。おかしい,なんか違う等ありましたらご一報を。
はじめに
ce2015.07.16-betaでは試験的な実装、ce-2015.11.05-stableではGAとなり、デフォルトでHA機能(Best Effort Basis)が有効になっています。前回に引き続き、Nutanix CE、ce-2015.11.05-stableにおける新しいHAの機能について、見ていきます。
AHVのHAを試してみる!
いよいよAHVのHA機能を実際に試してみます。HAの検証は、以下のような条件でそれぞれ確認を行います。
HA機能の検証パターンとHA機能を確認するための操作手順など
HA機能検証の環境
HA機能の検証は、当然ながらマルチノードクラスター環境で行います。2つのノードは,Xeon E5-2600系を搭載し,もう2つのノードはXeon X5600系を搭載した,CPUの世代を混在させたクラスター構成です。4つのノードで構成されるNutanix CEクラスターで、すべてのノードは10GbEで接続されています。VMはリソースに応じて4台のノードに分散されて稼動しています。
| ノードIPアドレス | CVMのIPアドレス | ノードID | 搭載CPU | メモリ量 |
|---|---|---|---|---|
| 192.168.100.100 | 192.168.100.110 | NTNX-98448b07-A | Xeon E5-2680 | 128GB |
| 192.168.100.101 | 192.168.100.111 | NTNX-4ec1c789-A | Xeon X5670 | 96GB |
| 192.168.100.102 | 192.168.100.112 | NTNX-4125b3c8-A | Xeon X5670 | 96GB |
| 192.168.100.103 | 192.168.100.113 | NTNX-4bda71a1-A | Xeon E5-2680 | 128GB |
HA機能検証確認のパターン
デフォルトのBest Effort Basisのみが有効になっているパターンで確認を行います。ただし,Best Effort Basisモードの場合は「リソースに空きがあれば」機能するベストエフォートのHA機能であるため、リソースにほぼ空きがない環境でも簡単に確認を行ってみます。
なお,その1で触れているとおり,Manage VM High Availabilityモードでは,単純にノード障害が生じた際のVMの再起動分のリソースを確保しているだけで基本的な動作は変わらないため,Best Effort Basisでリソースに余裕がある状態での確認を行い割愛します。
HA機能検証の操作
上記2つ「HA検証確認のパターン」の条件下でそれぞれ、以下のような操作を行います。
- ノードをダウンさせる
- ノードを復帰させる
HA機能検証の確認事項
- ノードダウン時
- 障害対象となるノード上で動作しているVMに,PRISMを操作するPCからpingを打ち続ける(リソースに余裕がある場合のHA検証のみ)
- 操作後,RDPやssh等でログインを試みる(リソースに余裕がある場合のHA検証のみ)
- PRISM上でイベントの確認及びVM管理画面から動作状況を確認する
- ノード復帰時
- PRISM上でイベントの確認及びVM管理画面から動作状況を確認する
HA機能検証の操作の対象ホスト
上記のHA機能検証の操作対象とするホストは,それぞれ以下のように設定します。
リソースに余裕がある状態でのHA機能の確認時
192.168.100.100,ノードIDがNTNX-98448b07-Aのホストを対象として,それぞれCVM,ノードをダウンさせた後,ノード復旧を行います。
- ノードをダウンさせる
192.168.100.100にログインしノードをシャットダウン(ノードのサーバー機器自体の電源が落ちます)
- ノードを復帰させる
192.168.100.100のノードが動作していたサーバー機器の電源を投入
リソースがほぼ枯渇している状態でのHA機能の確認時
192.168.100.101,ノードIDがNTNX-4ec1c789-Aのホストを対象として,それぞれCVM,ノードをダウンさせた後,ノード復旧を行います。
- ノードをダウンさせる
192.168.100.101にログインしノードをシャットダウン(ノードのサーバー機器自体の電源が落ちます)
- ノードを復帰させる
192.168.100.101のノードが動作していたサーバー機器の電源を投入
Best Effort BasisモードでのHA機能確認
まずは,リソースが十分にある状態でのHA確認を行います。この検証時点でのVM数は30で,HA機能が正しく動作しているかは,ノードをダウンさせた後も残りのノードで合計30VMが動作していれば,正常にHAが機能したことを確認できるハズです。
| ノードIPアドレス | ノードID | 検証時稼動VM数 |
|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | 10 |
| 192.168.100.101 | NTNX-4ec1c789-A | 5 |
| 192.168.100.102 | NTNX-4125b3c8-A | 5 |
| 192.168.100.103 | NTNX-4bda71a1-A | 10 |
※検証時稼動VM数は,厳密に言うとそれぞれ+1となる,上記の表はCVMを除いたユーザーVMの数としているため
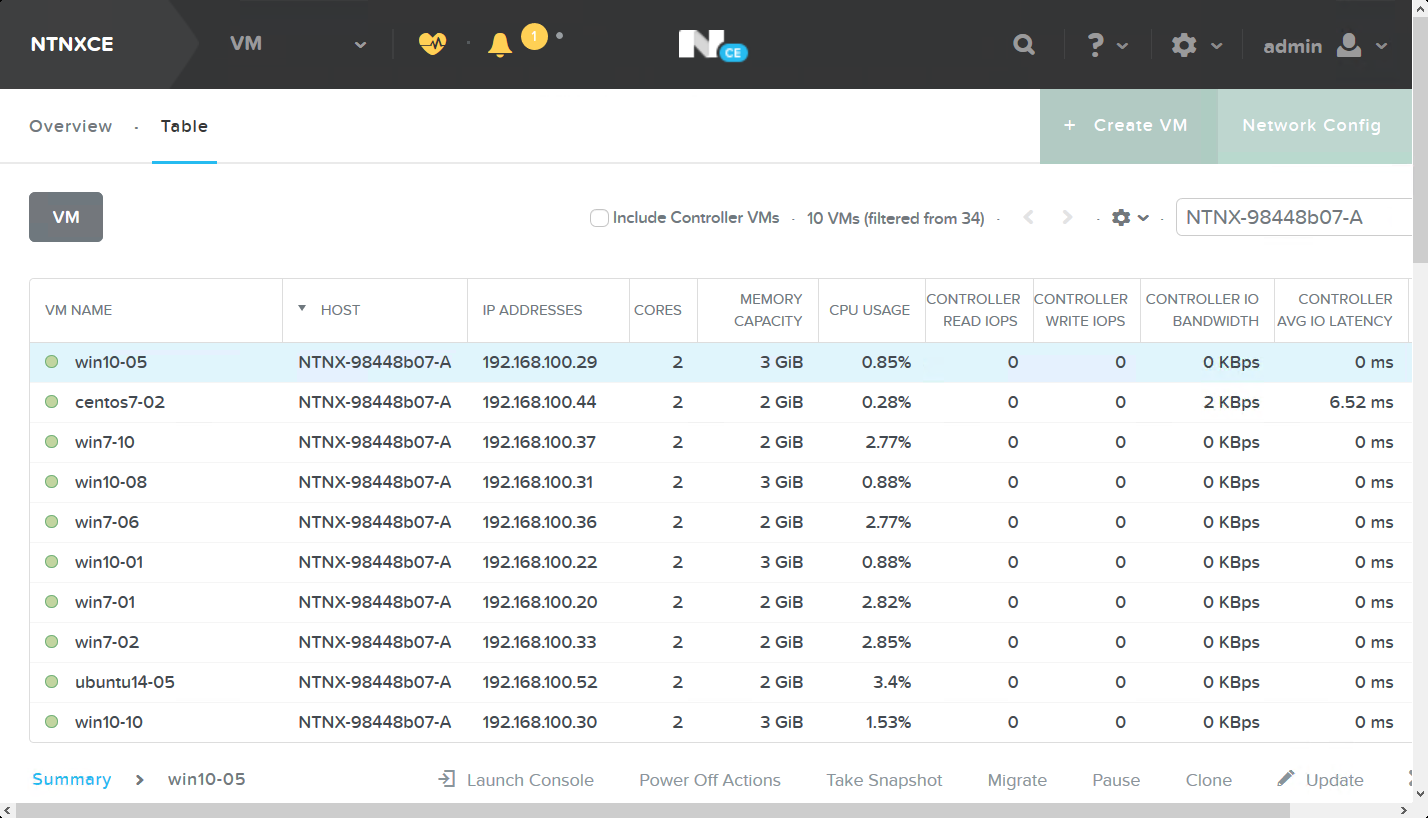
また,ノード障害状態を発生させる192.168.100.100のホストで動作しているVM名とVMのIPアドレスをリストにしておきます。
| VM名 | IPアドレス | OS |
|---|---|---|
| win10-05 | 192.168.100.29 | Windows 10 |
| centos7-02 | 192.168.100.44 | CentOS 7 |
| win7-10 | 192.168.100.37 | Windows 7 |
| win10-08 | 192.168.100.31 | Windows 10 |
| win7-06 | 192.168.100.36 | Windows 7 |
| win10-01 | 192.168.100.22 | Windows 10 |
| win7-01 | 192.168.100.20 | Windows 7 |
| win7-02 | 192.168.100.33 | Windows 7 |
| ubuntu14-05 | 192.168.100.52 | Ubuntu 14.04 |
| win10-10 | 192.168.100.30 | Windows 10 |
ノードをダウンさせる
192.168.100.100にsshでログインして,shutdown -h nowを実行します。
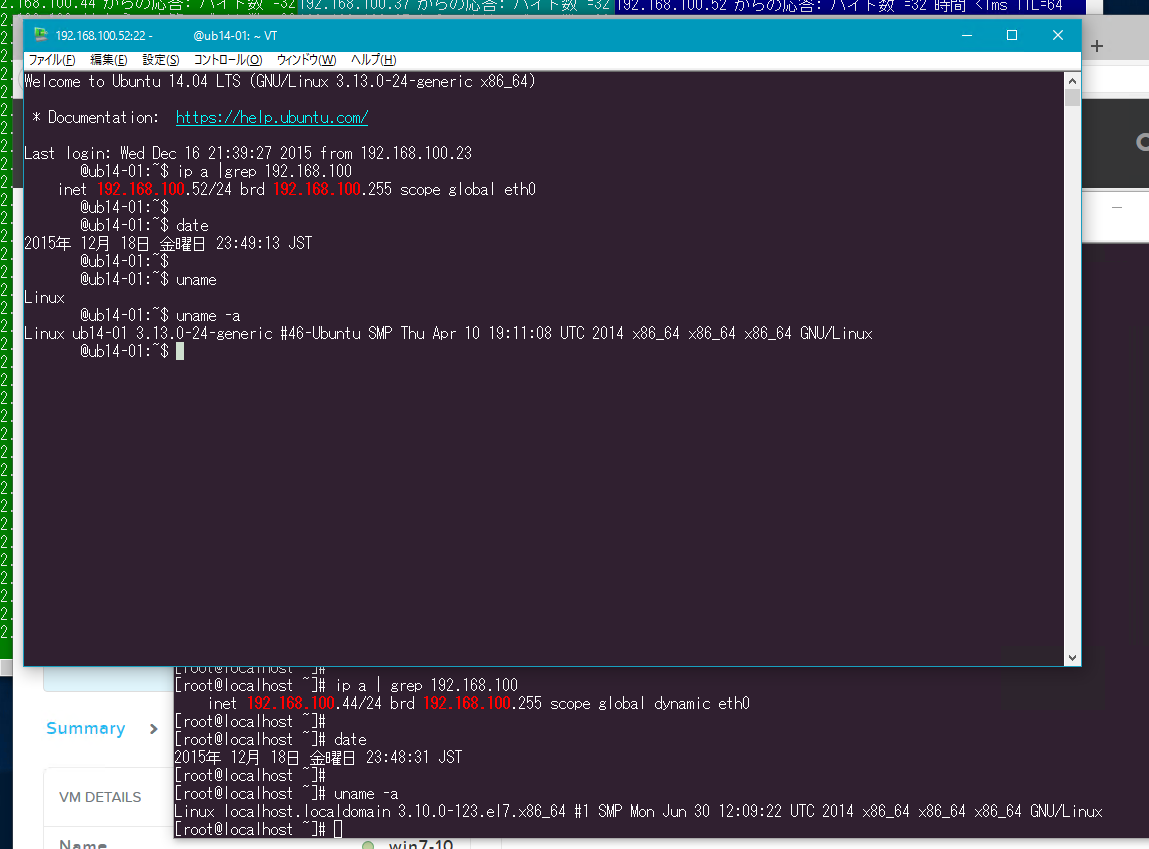
選択した4つのVMへのpingを確認します。
ノードをシャットダウンした直後にすぐにpingが対象のVMに届かなくなっています。ウィンドウは,左からWin10-05,centos7-02,win7-10,ubuntu14-05になっています。
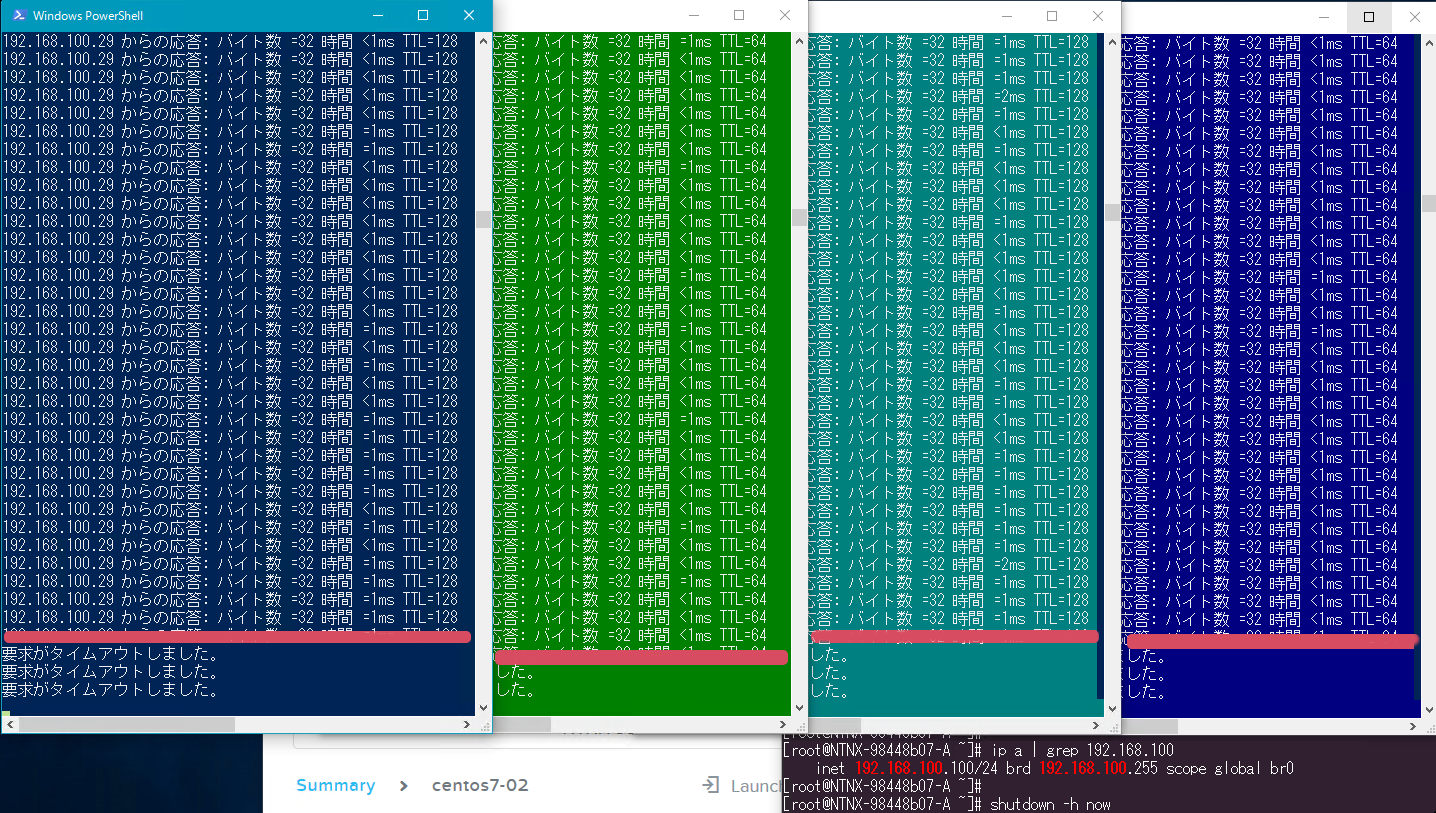
2分ほど後,再びpingが通るようになりました。無事にVMが再起動されたように見えます。スクリーンショットを取得した時点で,左から3番目のウィンドウのwin7-10がまだpingの応答が戻って来ていませんが,その後すぐにpingの疎通が戻っています。
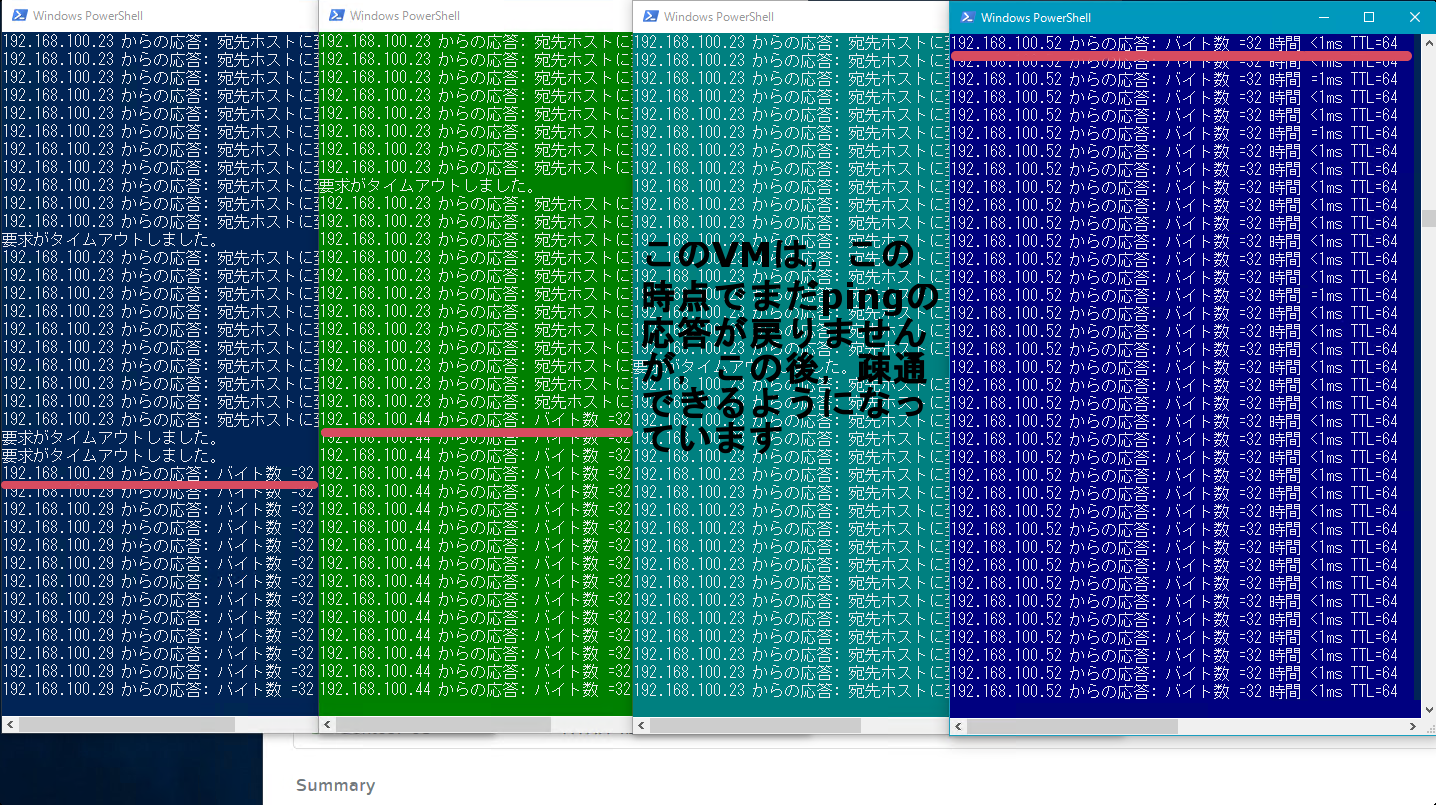
WindowsにRDP,Linuxにsshでアクセスしてみる。
pingの対象としたWin10-05,centos7-02,win7-10,ubuntu14-05にそれぞれRDPとsshで接続します。Windows,Linuxともに問題なく接続できました。
関連のイベントを確認する
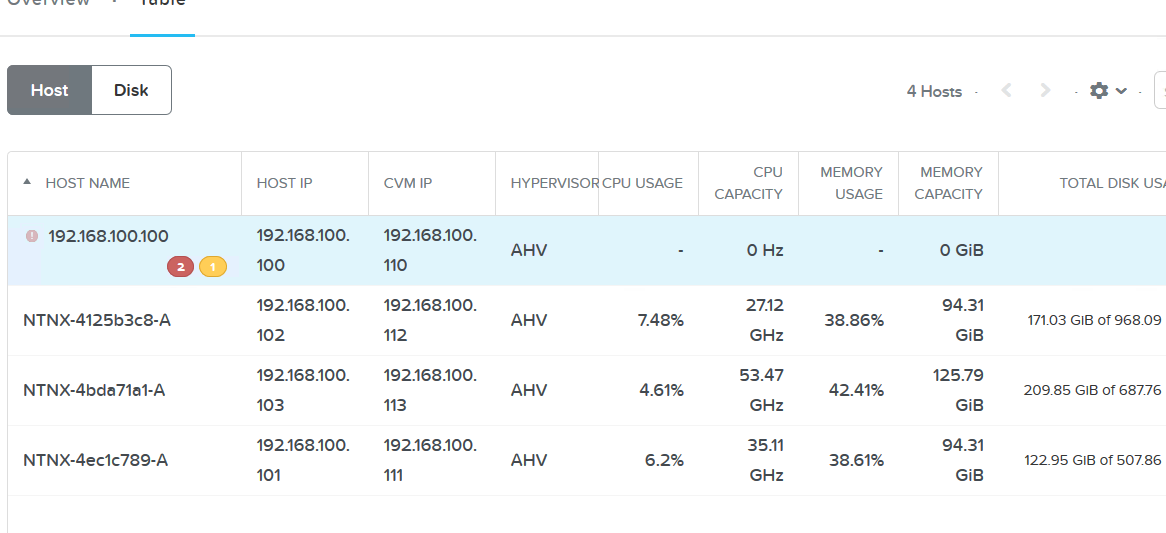
結果をイベントから確認します。また,再起動されたVM達がどこに行ったのかも併せて確認します。PRISM上でHardware管理の項目を見ると,ノードの一覧が確認できますが,192.168.100.100のノードは,シャットダウンしてしまったため状態が取得できない状態になっています。
ノードのイベント
以下のログを見る限り,10:40:46pmにHaFailoverが始まり,最終的にはRestartVmGroupが10:41:32pmに始まっており,正常にHA機能が動作したことが分かります。
HaFailover Node (Uuid) : 873fa2e9-f0fe-418b-92cd-63f0adbf031c 100 Succeeded 12/18/15, 10:40:46pm 2 minutes
StartHAFailover Node (Uuid) : 873fa2e9-f0fe-418b-92cd-63f0adbf031c 100 Succeeded 12/18/15, 10:41:02pm 30 seconds
HostRestartAllVms Node (Uuid) : 873fa2e9-f0fe-418b-92cd-63f0adbf031c 100 Succeeded 12/18/15, 10:41:32pm 60 seconds
RestartVmGroup Node (Uuid) : 873fa2e9-f0fe-418b-92cd-63f0adbf031c 100 Succeeded 12/18/15, 10:41:32pm 37 seconds
VMのイベントと移動先ノードの確認
次に,シャットダウンされたノード上で動作していた各VMの状況を確認します。また,再起動したVMが,どのノードに行ったのか,各ノード上で稼動するVM数がどうなったのかも確認します。すべてのVMのイベントを確認していくと大量になるので,1つだけに絞って確認します。
VMのうちping確認を行っていたwin10-05のログを確認します。10:41:52pmにVmForcePowerOffのイベントで強制電源断となりVMが停止しています。8秒後の10:42:00pmにVmSetPowerStateで起動が開始されていることがわかります。また,2行目の部分で,VmSetPowerStateが「Node : NTNX-4ec1c789-A」で実施されたとあり,192.168.100.101のノードで再起動されたことがわかります。
VmForcePowerOff VM : win10-05 Node (Uuid) : 873fa2e9-f0fe-418b-92cd-63f0adbf031c 100 Succeeded 12/18/15, 10:41:52pm Under 1 second
VmSetPowerState VM : win10-05 Node : NTNX-4ec1c789-A 100 Succeeded 12/18/15, 10:42:00pm 8 seconds
ノードを1つシャットダウンしたことで,4台クラスターから3台クラスターになっていますが,この時点で,HA機能により再起動したVMの行き先と各ノードでの稼動VM数は以下のようになっています。
HA機能により再起動したVMの行き先は以下のとおり。
| VM名 | 移動先ノードID | 移動先ノードIPアドレス |
|---|---|---|
| win10-05 | NTNX-4ec1c789-A | 192.168.100.101 |
| centos7-02 | NTNX-4ec1c789-A | 192.168.100.101 |
| win7-10 | NTNX-4125b3c8-A | 192.168.100.102 |
| win10-08 | NTNX-4bda71a1-A | 192.168.100.103 |
| win7-06 | NTNX-4ec1c789-A | 192.168.100.101 |
| win10-01 | NTNX-4bda71a1-A | 192.168.100.103 |
| win7-01 | NTNX-4125b3c8-A | 192.168.100.102 |
| win7-02 | NTNX-4125b3c8-A | 192.168.100.102 |
| ubuntu14-05 | NTNX-4bda71a1-A | 192.168.100.103 |
| win10-10 | NTNX-4bda71a1-A | 192.168.100.103 |
上記の結果から,それぞれHA機能により再起動したVMは,以下のように分散配置されました。
| ノードIPアドレス | ノードID | 稼動VM数 | VM増減数 |
|---|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | - | -10 |
| 192.168.100.101 | NTNX-4ec1c789-A | 8 | +3 |
| 192.168.100.102 | NTNX-4125b3c8-A | 8 | +3 |
| 192.168.100.103 | NTNX-4bda71a1-A | 14 | +4 |
ノードを復帰させる
ノードを復帰させます。今回,シャットダウンさせたノードは,PRIMERGY RX300 S7を利用しているためIPMIであるiRMCの画面から電源の投入を行います。
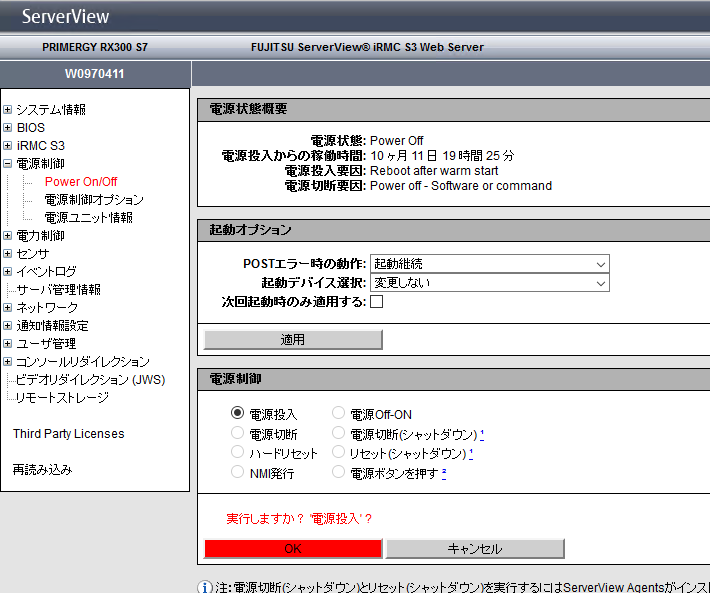
関連のイベントを確認する
結果をイベントから確認します。また,シャットダウンさせたノードを復帰させたことで何が起こるのかを確認していきます。
ノードのイベント
以下のログを見ると,電源投入してシャットダウンされたノードが復帰してきた際に,12:28:20amにHostRestoreVmLocalityと言うイベントが発生しています。これだけを単語の意味のみで見ると,ローカル性のリストア,となんとなく分かりそうで分からない内容ですが,個々のVMに関するイベントを見ると,このHostRestoreVmLocalityと言うイベントの正体が判明します。
HostRestoreVmLocality Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:20am 48 seconds
VMのイベント
復帰してきたノードで12:28:20amに発生したHostRestoreVmLocalityと言うイベントに関連して,12:28:21am頃から以下のVM達に一斉にMigrate VMと言うイベントが発生しています。このイベントが発生しているVMを見ると,全て,元はシャットダウンした192.168.100.100ノードで稼動していたVM達です。そしてこれらのVM達のマイグレーション先は,すべてNTNX-98448b07-Aとなっています。NTNX-98448b07-Aは,言うまでもなく復帰した192.168.100.100のノードなります。
Migrate VM : win7-01 Node : NTNX-4ec1c789-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:29:03am 6 seconds
Migrate VM : centos7-02 Node : NTNX-4ec1c789-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:56am 6 seconds
Migrate VM : win10-05 Node : NTNX-4ec1c789-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:54am 9 seconds
Migrate VM : win7-02 Node : NTNX-4125b3c8-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:50am 7 seconds
Migrate VM : win7-06 Node : NTNX-4125b3c8-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:39am 14 seconds
Migrate VM : win7-10 Node : NTNX-4125b3c8-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:37am 13 seconds
Migrate VM : ubuntu14-05 Node : NTNX-4bda71a1-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:31am 5 seconds
Migrate VM : win10-01 Node : NTNX-4bda71a1-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:30am 9 seconds
Migrate VM : win10-08 Node : NTNX-4bda71a1-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:21am 10 seconds
Migrate VM : win10-10 Node : NTNX-4bda71a1-A Node : NTNX-98448b07-A 100 Succeeded 12/19/15, 12:28:21am 10 seconds
ここで再び,各ノードでの稼動VM数を確認します。以下のように,ノードのシャットダウン前と同じ状態に戻りました。ノードが復帰されたことで,Nutanixの用語で言うローカリティを確保するため,障害によって別のノードで再起動していたVMがすべて元のノードに戻って来ました。
| ノードIPアドレス | ノードID | 稼動VM数 | VM増減数 |
|---|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | 10 | +10 |
| 192.168.100.101 | NTNX-4ec1c789-A | 5 | -3 |
| 192.168.100.102 | NTNX-4125b3c8-A | 5 | -3 |
| 192.168.100.103 | NTNX-4bda71a1-A | 10 | -4 |
Best Effort BasisモードでのHA機能確認(リソースほぼ枯渇状態)
次に,リソースがほぼ枯渇している状態でのHA確認を行います。この検証時点でのVM数は115で,ベストエフォートでのHA機能がどのように振る舞うのかを確認していきます。リソースがほぼ枯渇している状態なので,1つのノードをシャットダウンした場合,残りのノードでは,全てのVMが再起動できないはずだと想定されます。
VMを大量にクローンする
まず,Nutanix CEクラスター内の総メモリ容量をギリギリ近くまで使い切るため,Windows 10をクローンしします。完全に枯渇させると、障害が発生したノード上のすべてのVMが再起動できないと思われるため、数VM程度は起動可能な余力を残しておきます。この時点でクラスター全体で稼動しているVM数は115,クラスター全体の総メモリ容量の91.48%を使っています。以下のスクリーンショットで,VM数が119とありますが,うち4つのVMは,CVMであるため除外したユーザーVMのみをカウントしています。
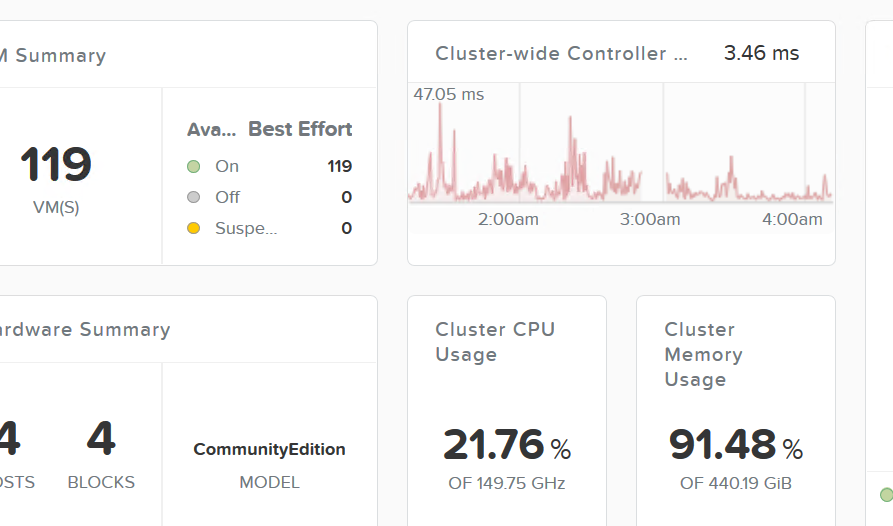
なお、このクローン作業を行った後,acli上で一気,vm.on(VMの電源オン)を流したら大変なことになりました。
Nutanix CEのHA機能ためすのに、VMを大量にクローンしたら、4台のラックマウントサーバーのファンが唸りを上げて猛回転し、そしてブレーカ落ちたwwwww大惨事wwwww
— 鼻からミルク a.k.a hana(ry (@hanakara_milk) 2015, 12月 18
ノードをダウンさせる
192.168.100.101にsshでログインして,shutdown -h nowを実行します。シャットダウン当時、192.168.100.101では、24VMが動作しており、それらが残りの生きているどこかのノードで、全部ではないけどいくつかのVMは再起動されるはずです。
リソースが十分にある状況下での検証と異なり,VMの数が多いためリストを取るのはやめています。シャットダウンの直前で全てのVMは起動しており,停止中のVMは存在しないため,192.168.100.101のノードのシャットダウン後は,ログからシャットダウン直後にVmSetPowerStateで起動をしようとするVMを捕まえることで確認を行います。
| ノードIPアドレス | ノードID | 検証時稼動VM数 |
|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | 34 |
| 192.168.100.101 | NTNX-4ec1c789-A | 24 |
| 192.168.100.102 | NTNX-4125b3c8-A | 24 |
| 192.168.100.103 | NTNX-4bda71a1-A | 33 |
192.168.100.101にsshでログインして,shutdown -h nowを実行します。
関連のイベントを確認する
ノードのイベント
以下のログを見る限り,先の検証と同様にHaFailoverが始まあり,StartHAFailoverまでは同様ですが,HostRestartAllVms及びRestartVmGroupのイベントがFailedになっています。もう少し見ると「Failed to restart one or more VMs on ...」とあり,1つ以上の再起動に失敗したとあります。
HaFailover Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Succeeded 12/19/15, 04:24:50am 1 minute
StartHAFailover Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Succeeded 12/19/15, 04:24:50am Under 1 second
HostRestartAllVms Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Failed : Failed to restart one or more VMs on ... 12/19/15, 04:24:50am 60 seconds
RestartVmGroup Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Failed : Failed to restart one or more VMs on ... 12/19/15, 04:24:50am 23 seconds
VMのイベントと移動先ノードの確認
引き続き,シャットダウンされたノード上で動作していた各VMの状況を確認します。先ほどの検証と同様に,再起動したVMが,どのノードに行ったのか,各ノード上で稼動するVM数がどうなったのかも確認します。今回は,再起動に成功したVMと再起動できなかったVM,それぞれ1つずつに絞って確認します。
別のノードで再起動に成功したVM
VmForcePowerOff VM : win10-77 Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Succeeded 12/19/15, 04:24:50am Under 1 second
VmSetPowerState VM : win10-77 Node : NTNX-4bda71a1-A 100 Succeeded 12/19/15, 04:25:11am 1 second
別のノードで再起動に失敗したVM
VmForcePowerOff VM : win10-04 Node (Uuid) : f4406781-bbbe-4ec9-a790-fd94e7e1f378 100 Succeeded 12/19/15, 04:25:11am Under 1 second
VmSetPowerState VM : win10-04 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
失敗したVMは,「Failed : No host has enough available memory. ...」とあり,ノードが1つ障害で失われた結果,そのノードで稼動していたすべてのVMを他のノードで再起動できるだけのメモリがなかったため,再起動に失敗しています。同様に再起動に失敗したVMが多数あり,結果としてノードをシャットダウンした後のベストエフォートでのHAが機能した結果,以下のようにVMは再配置されました。
| ノードIPアドレス | ノードID | 稼動VM数 | VM増減数 |
|---|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | 35 | +1 |
| 192.168.100.101 | NTNX-4ec1c789-A | - | -24 |
| 192.168.100.102 | NTNX-4125b3c8-A | 24 | ±0 |
| 192.168.100.103 | NTNX-4bda71a1-A | 35 | +2 |
先の検証と同様に再起動されたVMは,リソースの空き状況に従って均されて配置されましたが,先ほどと状況が異なるのは,VMの増減数を見ると合計で-21となります。つまり24VM中3VMしか,他のノードで再起動できず,21VMが再起動に失敗したことが想定されます。検証開始前は115VMが起動していましたが,ノードを1つ停止後は,94VMしか稼動していないことになります。
実際に,ログを「No host has enough available memory」で検索すると,以下のように21件がヒットしました。想定どおり,空きリソースがギリギリの状況下では,障害が発生したノードで稼動していた24VMのうち,3VMのみが別のノードで再起動に成功しましたが,残りのVMは,リソースに空きがなく,VMの再起動に失敗しています。
01:VmSetPowerState VM : win10-27 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
02:VmSetPowerState VM : win10-41 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
03:VmSetPowerState VM : win10-47 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
04:VmSetPowerState VM : win10-83 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
05:VmSetPowerState VM : win10-58 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
06:VmSetPowerState VM : win10-84 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
07:VmSetPowerState VM : win10-18 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
08:VmSetPowerState VM : win10-11 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
09:VmSetPowerState VM : centos7-01 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
10:VmSetPowerState VM : win10-80 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
11:VmSetPowerState VM : win10-94 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
12:VmSetPowerState VM : win10-04 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
13:VmSetPowerState VM : win10-74 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
14:VmSetPowerState VM : win10-52 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:12am Under 1 second
15:VmSetPowerState VM : win7-09 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
16:VmSetPowerState VM : win10-38 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
17:VmSetPowerState VM : win10-71 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
18:VmSetPowerState VM : win10-30 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
19:VmSetPowerState VM : win10-29 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
20:VmSetPowerState VM : win10-92 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
21:VmSetPowerState VM : win7-05 100 Failed : No host has enough available memory. ... 12/19/15, 04:25:13am Under 1 second
ノードを復帰させる
ノードを復帰させます。今回,シャットダウンさせたノードは,PowerEdge R710を利用しているためIPMIであるiDRACの画面から電源の投入を行います。
関連のイベントを確認する
結果をイベントから確認します。また,シャットダウンさせたノードを復帰させたことで何が起こるのかを確認していきます。
ノードのイベント
以下のログを見ると,先の検証時と同様にHostRestoreVmLocalityと言うイベントが発生しています。
HostRestoreVmLocality Node : NTNX-4ec1c789-A 100 Succeeded 12/19/15, 05:15:39am 3 minutes
VMのイベント
復帰してきたノードでHostRestoreVmLocalityに関連して,再起動に成功した3つのVMだけMigrate VMと言うイベントが発生しています。先ほどと同様にこれらのVM達のマイグレーション先は,すべてNTNX-4ec1c789-Aとなっています。NTNX-4ec1c789-Aは,復帰した192.168.100.101のノードなります。
Migrate VM : win10-77 Node : NTNX-4bda71a1-A Node : NTNX-4ec1c789-A 100 Succeeded 12/19/15, 05:15:39am 4 seconds
Migrate VM : win10-66 Node : NTNX-4bda71a1-A Node : NTNX-4ec1c789-A 100 Succeeded 12/19/15, 05:15:39am 5 seconds
Migrate VM : ubuntu14-02 Node : NTNX-98448b07-A Node : NTNX-4ec1c789-A 100 Succeeded 12/19/15, 05:17:51am 3 seconds
続いて,それ以外の再起動に失敗したVMはどうなったかの確認します。win10-27をサンプルとして見てみます。復旧させたノードでHostRestoreVmLocalityのイベントが発生した直後から,VmSetPowerStateが開始されていますが,約1分ほど失敗しています。その後,NTNX-4ec1c789-Aで起動に成功したとログから読み取ることができます。他のVMもすべて同様にNTNX-4ec1c789-Aで再起動されていました。
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:15:44am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:15:45am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:15:47am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:15:51am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:15:59am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:16:15am Under 1 second
VmSetPowerState VM : win10-27 100 Failed : Host f4406781-bbbe-4ec9-a790-fd94e7e1... 12/19/15, 05:16:47am Under 1 second
VmSetPowerState VM : win10-27 Node : NTNX-4ec1c789-A 100 Succeeded 12/19/15, 05:18:03am 2 seconds
最後に再び,各ノードでの稼動VM数を確認します。以下のように,今回もノードのシャットダウン前と同じ状態に戻りました。ノードが復旧されたことで,障害によって別のノードで再起動していたVM及び再起動に失敗していたVMがすべて元のノードに戻って来ました。
| ノードIPアドレス | ノードID | 稼動VM数 | VM増減数 |
|---|---|---|---|
| 192.168.100.100 | NTNX-98448b07-A | 34 | -1 |
| 192.168.100.101 | NTNX-4ec1c789-A | 24 | +24 |
| 192.168.100.102 | NTNX-4125b3c8-A | 24 | ±0 |
| 192.168.100.103 | NTNX-4bda71a1-A | 33 | -2 |
まとめ
上記の検証の結果をまとめると以下のようになります。
| 操作 | リソース十分状態 | リソース枯渇状態 |
|---|---|---|
| ノード障害 | HAで別ノードで再起動 | HAで空きリソース分だけVMが再起動 |
| ノード復旧 | 復旧ノードにマイグレーション | 復旧ノードにマイグレーション及び復旧ノードで再起動 |
Best Effort Basisでも,基本的に問題なくHA機能が動作することが分かりました。また,ノード復旧時には,待避していたVMが元のノードに自動で戻ってくることも確認できました。
Nutanix CEのce-2015.11.05-stableでは,何度か述べてきたようにデフォルトでHA機能が有効になっているため,当然の振る舞いと言えば,そうなのですが,今回HA機能に係る設定操作は何一つ行っていません。他の製品では,デフォルトで有効等の機能があっても,それなりの設定が必要になるケースが多いのですが,Nutanixに関しては,本当に電源を入れてクラスターを構成したのみで,それだけで電源を落とそうが,ブレーカーが落ちて全ノードが停止しようが,HA機能が有効に働いてくれることが分かりました。
Nutanix CEにおけるHA機能に関するまとめとしては以下のようになります。
- HA機能は,デフォルトで有効であり,何一つ設定する操作を必要としない
- 停止してしまったVMは全て全自動で別のノードで再起動,復旧してくれる
- データの置き場所を意識しなくても良く,どこでVMが起動していてもデータは自動で正しく再接続される
- ノードが復旧すると元のノードに全自動でマイグレーションされる
- クラスターの全ノードが停止しても,再起動でクラスター及びVMがすべて復旧される
無償のCommunity EditionでここまでしっかりとしたHA機能が利用できるものは,なかなかお目にかかれないと思います。Nutanix CEは,企業や自宅の検証ラボ等,いつもで普通に使えて欲しいけど,システム管理者が手間暇をかけられない又はインフラに詳しいエンジニアがいないと言った状況下でも,多少の障害が発生しても運用に支障が出ない,修理や交換でハードウェアさえ正常な状態で電源を入れれば,復旧も全自動で行ってくれる環境が簡単に導入できる,ちょっとお得なプロダクトではないでしょうか。