print文を仕込んで実行時間を出力していくパフォーマンスチューニング作業は辛いのでもう止めにしようってお話です。
プログラムで実行速度が遅いロジックを特定できれば改善は容易です。profilerを利用すると簡単に原因が特定できるので使い方を紹介します。前半はline_profilerを利用した実行速度が遅いロジックの特定方法、後半はPythonでの高速化テクニックです。
どの行が重いかprofilerで特定する
ローカル環境でprofilerを使いどの行が重いのかを特定していきます。Pythonには様々なprofilerが存在しますが、個人的にはline_profilerが必要十分な機能を持っていてよく利用しています。ここで特定するのは『どの行がN回実行されていて、全体でM%の実行時間が掛かっている』という点です。
line_profilerの使用例
実行に10秒くらい掛かるサンプルコードを書いてみました。time.sleep()している処理はDBアクセスと読み替えてください。ユーザがカード1000枚所持していて、カード毎にスキルを3つ所持しているデータをjsonで返却するプログラムです。
■ profilerが全部教えてくれるので読み飛ばして構わないコード
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import random
import time
import simplejson
class UserCardSkill(object):
def __init__(self, user_id, card_id):
self.id = random.randint(1, 1000), # SkillIDの範囲は1-999と仮定
self.user_id = user_id
self.card_id = card_id
@property
def name(self):
return "skill:{}".format(str(self.id))
@classmethod
def get_by_card(cls, user_id, card_id):
time.sleep(0.01)
return [cls(user_id, card_id) for x in xrange(3)] # CardはSkillを3つ持つ
def to_dict(self):
return {
"name": self.name,
"skill_id": self.id,
"card_id": self.card_id,
}
class UserCard(object):
def __init__(self, user_id):
self.id = random.randint(1, 300) # CardIDの範囲は1-299と仮定
self.user_id = user_id
@property
def name(self):
return "CARD:{}".format(str(self.id))
@property
def skills(self):
return UserCardSkill.get_by_card(self.user_id, self.id)
@classmethod
def get_by_user(cls, user_id):
time.sleep(0.03)
return [cls(user_id) for x in range(1000)] # ユーザがCard1000枚持っていると仮定
def to_dict(self):
"""
カード情報をdictに変換して返却
"""
return {
"name": self.name,
"skills": [skill.to_dict() for skill in self.skills],
}
def main(user_id):
"""
userが所持するcard情報をjsonで応答する
"""
cards = UserCard.get_by_user(user_id)
result = {
"cards": [card.to_dict() for card in cards]
}
json = simplejson.dumps(result)
return json
user_id = "A0001"
main(user_id)
line_profilerで重い行を特定する
それではprofilerツールをインストールして重い箇所を特定していきます。
pip install line_profiler
~~省略~~
# profilerのインスタンス生成と関数の登録
from line_profiler import LineProfiler
profiler = LineProfiler()
profiler.add_module(UserCard)
profiler.add_module(UserCardSkill)
profiler.add_function(main)
# 登録したmain関数の実行
user_id = "A0001"
profiler.runcall(main, user_id)
# 結果表示
profiler.print_stats()
line_profilerの実行結果
>>>python ./sample1_profiler.py
Timer unit: 1e-06 s
Total time: 0.102145 s
File: ./sample1_profiler.py
Function: __init__ at line 9
Line # Hits Time Per Hit % Time Line Contents
==============================================================
9 def __init__(self, user_id, card_id):
10 3000 92247 30.7 90.3 self.id = random.randint(1, 1000), # SkillIDの範囲は1-999と仮定
11 3000 5806 1.9 5.7 self.user_id = user_id
12 3000 4092 1.4 4.0 self.card_id = card_id
Total time: 0.085992 s
File: ./sample1_profiler.py
Function: to_dict at line 23
Line # Hits Time Per Hit % Time Line Contents
==============================================================
23 def to_dict(self):
24 3000 10026 3.3 11.7 return {
25 3000 66067 22.0 76.8 "name": self.name,
26 3000 6091 2.0 7.1 "skill_id": self.id,
27 3000 3808 1.3 4.4 "card_id": self.card_id,
28 }
Total time: 0.007384 s
File: ./sample1_profiler.py
Function: __init__ at line 32
Line # Hits Time Per Hit % Time Line Contents
==============================================================
32 def __init__(self, user_id):
33 1000 6719 6.7 91.0 self.id = random.randint(1, 300) # CardIDの範囲は1-299と仮定
34 1000 665 0.7 9.0 self.user_id = user_id
Total time: 11.0361 s
File: ./sample1_profiler.py
Function: to_dict at line 49
Line # Hits Time Per Hit % Time Line Contents
==============================================================
49 def to_dict(self):
50 """
51 カード情報をdictに変換して返却
52 """
53 1000 1367 1.4 0.0 return {
54 1000 10362 10.4 0.1 "name": self.name,
55 4000 11024403 2756.1 99.9 "skills": [skill.to_dict() for skill in self.skills],
56 }
Total time: 11.1061 s
File: ./sample1_profiler.py
Function: main at line 59
Line # Hits Time Per Hit % Time Line Contents
==============================================================
59 def main(user_id):
60 """
61 userが所持するcard情報をjsonで応答する
62 """
63 1 41318 41318.0 0.4 cards = UserCard.get_by_user(user_id)
64 1 1 1.0 0.0 result = {
65 1001 11049561 11038.5 99.5 "cards": [card.to_dict() for card in cards]
66 }
67 1 15258 15258.0 0.1 json = simplejson.dumps(result)
68 1 2 2.0 0.0 return json
■ profilerで重い行が特定できた。
line_profilerの実行結果から、65行目と55行目の処理が重いことが判りました。ユーザがカード1000枚持っていて、各カード毎に1000回UserCardSkillに問い合わせを行った結果、実行に10秒以上掛かってしまったみたいです。
高速化テクニック
具体的なプログラムの実行速度改善テクニックです。profilerで調査したプログラムを出来るだけコード構造を変更せずにCacheによるメモ化やHash探索によってチューニングしていきます。Pythonの話がしたいのでSQL高速化の話には触れません。
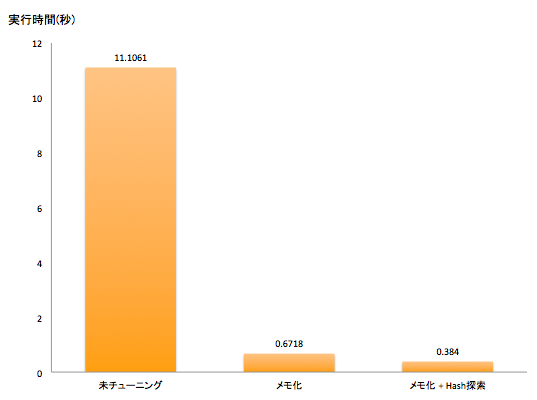
メモ化を組み合わせたDB問い合わせ回数削減
コードの構造を出来るだけ変更せずに、UserCardSkillへの問い合わせ回数を削減します。一括でuserに紐づくUserCardSkillを取得して、メモリ上に保存しておき2回目以降はメモリ上のデータから値を返却するコードです。
class UserCardSkill(object):
_USER_CACHE = {}
@classmethod
def get_by_card(cls, user_id, card_id):
# 改善前の都度DBアクセスする関数
time.sleep(0.01)
return [cls(user_id, card_id) for x in xrange(3)]
@classmethod
def get_by_card_from_cache(cls, user_id, card_id):
# 改善後の初回のみDBアクセスする関数
if user_id not in cls._USER_CACHE:
# キャッシュ上にデータが存在しない場合はUserに係る全スキルをDBから取得する
cls._USER_CACHE[user_id] = cls.get_all_by_user(user_id)
r = []
for skill in cls._USER_CACHE[user_id]:
if skill.card_id == card_id:
r.append(skill)
return r
@classmethod
def get_all_by_user(cls, user_id):
# Userに係る全スキルをDBから一括で取得する
return list(cls.objects.filter(user_id=user_id))
from timeit import timeit
@timeit # 実行時間がprintされる
def main(user_id):
>>>sample1_memoize.py
func:'main' args:[(u'A0001',), {}] took: 0.6718 sec
改善前の11.1061 secから0.6718 secと15倍以上高速化しました。UserCardSkillへの問い合わせ回数が1000回から1回にまとめられたことが実行速度改善の理由です。
線形探索からハッシュ探索に書き換える
メモ化したコードではget_by_card_from_cache関数内でcard毎のskillを線形するために毎回要素数が3 * 1000のリストcls._USER_CACHE[user_id]を線形探索(フルスキャン)しています。毎回線形探索しては効率は悪いのでcard_idをkeyとするdictを事前に生成しておいてhash探索に書き換えます。このコードにおいて線形探索の計算量はO(n), ハッシュ探索の計算量はO(1)です。
~~省略~~
class UserCardSkill(object):
_USER_CACHE = {}
@classmethod
def get_by_card_from_cache(cls, user_id, card_id):
if user_id not in cls._USER_CACHE:
# キャッシュ上にデータが存在しない場合はUserに係る全スキルをDBから取得する
users_skill = cls.get_all_by_user(user_id)
# card_idをKEYとするdictに変換する
cardskill_dict = defaultdict(list)
for skill in users_skill:
cardskill_dict[skill.card_id].append(skill)
# キャッシュに保存
cls._USER_CACHE[user_id] = cardskill_dict
# 線形探索からハッシュ探索に書き換えた
return cls._USER_CACHE[user_id].get(card_id)
@classmethod
def get_all_by_user(cls, user_id):
# Userに係る全スキルをDBから取得する
return list(cls.objects.filter(user_id=user_id))
>>>sample1_hash.py
func:'main' args:[(u'A0001',), {}] took: 0.3840 sec
改善前は要素数3000のリストをカード1000枚分フルスキャンしていたのでif skill.card_id == card_id:が300万回呼び出されていました。hash探索に置き換えたことで無くなったため、hashを生成するコストを差し引いても実行速度改善に繋がっています。
cached_propertyを利用
お手軽なメモ化といえばcached_propertyではないでしょうか。インスタンスキャッシュにself.func.__name__(サンプル実装であれば"skills")をKEYにして戻り値を保存しています。2回目以降の問い合わせではキャッシュから値を返却することで実行速度が改善します。実装は数行なのでコード読んだ方が早いかもしれません。cached_property.py#L12
from cached_property import cached_property
class Card(object):
@cached_property
def skills(self):
return UserCardSkill.get_by_card(self.user_id, self.id)
@timeit
def main(user_id):
cards = Card.get_by_user(user_id)
for x in xrange(10):
cards[0].skills
# cached_property適用前
>>>python ./cached_property.py
func:'main' args:[(u'A0001',), {}] took: 0.1443 sec
# cached_property適用後
>>> python ./sample1_cp.py
func:'main' args:[(u'A0001',), {}] took: 0.0451 sec
スレッドローカルストレージを利用
wsgiとApacheでWebサーバを稼働させていること前提のお話です。
スレッド ローカル ストレージ (TLS) は、指定されたマルチスレッド プロセスの各スレッドに固有のデータを格納する場所を割り当てるための手段です。wsgiとApacheでWebサーバを動作させている場合、configにMaxRequestsPerChild を1以上の値を設定すると、子プロセスはMaxRequestsPerChild 個のリクエストの後に終了します。スレッド ローカル ストレージ (TLS) を利用したプログラムを書くと、子プロセス毎にキャッシュを保存できます。マスターデータのような全ユーザ間で共通のデータをTLS に保管することで大幅な速度向上が見込めます。
最大0 - 500010の範囲の整数から素数を計算するプログラムを書いてみました。素数計算結果をTLS に記録することで、2回目以降の素数計算をスキップしています。
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import random
import threading
import time
threadLocal = threading.local()
def timeit(f):
def timed(*args, **kw):
# http://stackoverflow.com/questions/1622943/timeit-versus-timing-decorator
ts = time.time()
result = f(*args, **kw)
te = time.time()
print 'func:%r args:[%r, %r] took: %2.4f sec' % (f.__name__, args, kw, te-ts)
return result
return timed
@timeit
def worker():
initialized = getattr(threadLocal, 'initialized', None)
if initialized is None:
print "init start"
# TLSの初期化
threadLocal.initialized = True
threadLocal.count = 0
threadLocal.prime = {}
return []
else:
print "loop:{}".format(threadLocal.count)
threadLocal.count += 1
return get_prime(random.randint(500000, 500010))
def get_prime(N):
"""
素数のリストを返却
:param N: int
:rtype : list of int
"""
# TLSにデータが有ればキャッシュから返却
if N in threadLocal.prime:
return threadLocal.prime[N]
# 素数を計算する
table = list(range(N))
for i in range(2, int(N ** 0.5) + 1):
if table[i]:
for mult in range(i ** 2, N, i):
table[mult] = False
result = [p for p in table if p][1:]
# TLSに結果を記録
threadLocal.prime[N] = result
return result
for x in xrange(100):
worker()
>>>python tls.py
init start
func:'worker' args:[(), {}] took: 0.0000 sec
loop:0
func:'worker' args:[(), {}] took: 0.1715 sec
loop:1
func:'worker' args:[(), {}] took: 0.1862 sec
loop:2
func:'worker' args:[(), {}] took: 0.0000 sec
loop:3
func:'worker' args:[(), {}] took: 0.2403 sec
loop:4
func:'worker' args:[(), {}] took: 0.2669 sec
loop:5
func:'worker' args:[(), {}] took: 0.0001 sec
loop:6
func:'worker' args:[(), {}] took: 0.3130 sec
loop:7
func:'worker' args:[(), {}] took: 0.3456 sec
loop:8
func:'worker' args:[(), {}] took: 0.3224 sec
loop:9
func:'worker' args:[(), {}] took: 0.3208 sec
loop:10
func:'worker' args:[(), {}] took: 0.3196 sec
loop:11
func:'worker' args:[(), {}] took: 0.3282 sec
loop:12
func:'worker' args:[(), {}] took: 0.3257 sec
loop:13
func:'worker' args:[(), {}] took: 0.0000 sec
loop:14
func:'worker' args:[(), {}] took: 0.0000 sec
loop:15
func:'worker' args:[(), {}] took: 0.0000 sec
...
スレッドローカルストレージ(TLS) に格納したキャッシュはApacheの子プロセス毎に保存されて、子プロセスが終了するまで残り続けます。
キャッシュには副作用がある
適切にキャッシュを利用するとプログラムの実行速度が改善します。ただし副作用と呼ばれるキャッシュ特有のバグが発生することが多々あるため十分注意しましょう。過去に自分が見かけたり、やらかした中だと
■ 更新しても新しい値が取得出来ない表示バグ
キャッシュのライフサイクル設計を意識せずに利用すると発生するバグです。
1.値取得 >> 2.値更新 >> 3.値取得 の順に行うプログラムを書いたときに、1で値がキャッシュされた結果2で更新するときにキャッシュが消えず、3で取得時に更新された値が取得できずに古い値を取得してそのまま表示してしまうバグです。
■ データ消えちゃうバグ
致命的な奴です。1.値取得 >> 2.取得した値にAddして値更新 の順に行うプログラムにて、1の値がキャッシュを参照していて更新されなかった結果、たとえば1234 + 100, 1234 + 200, 1234 + 50と、値が消えてしまうバグが発生したりします。
■ 副作用の防ぎ方
cached_propertyデコレタのようにパッケージ化して、十分に試験されたパッケージからキャッシュを扱えば誰でも安全に利用できます。理屈を知らなくても扱えるようになりますが、出来ればキャッシュのライフサイクルに関する理屈を知っておいた方が適切に扱えると思います。
memo
line_profilerの公開日は2008年