ツクリタイモノ
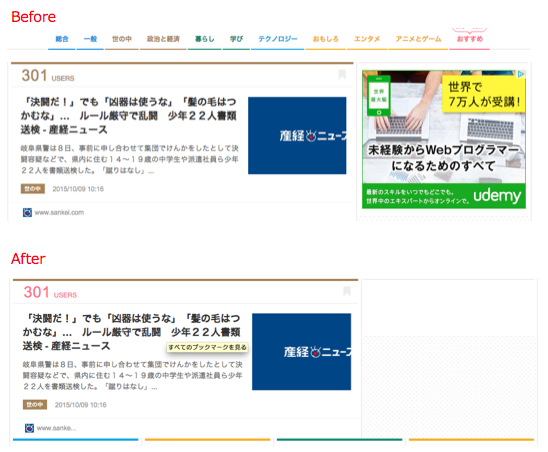
はてぶの広告を消したい
WEBRickにはプロキシサーバ用のクラスがある
るびまの過去ログ読んでたらWEBrick::HTTPProxyServerを利用したコンテンツフィルターの実装例があったので実装してみました。
るびまの過去ログを元にザックリ実装
hatena_ad_block_proxy.rb
IP = '0.0.0.0'
PORT = '13636'
DOC = './'
require 'webrick'
require 'webrick/httpproxy'
handler = Proc.new() {|req,res|
if req.host != nil and req.host.include?("hatena.ne.jp") and res['content-type'] != nil and res['content-type'].include?("text/html;")
res.body.gsub!(/<noscript>.*<\/noscript>/m, "")
end
}
opts = {
:BindAddress => IP,
:Port => PORT,
:DocumentRoot => DOC,
:ProxyContentHandler => handler
}
server = WEBrick::HTTPProxyServer.new(opts)
# コマンドラインでCtrl+Cした場合止めるイベントハンドラ
Signal.trap(:INT){ server.shutdown}
# サーバースタート
server.start
server起動
>ruby hatena_ad_block_proxy.rb
[2015-10-09 19:23:35] INFO WEBrick 1.3.1
[2015-10-09 19:23:35] INFO ruby 2.2.3 (2015-08-18) [x86_64-darwin13]
[2015-10-09 19:23:35] INFO WEBrick::HTTPProxyServer#start: pid=98756 port=13636
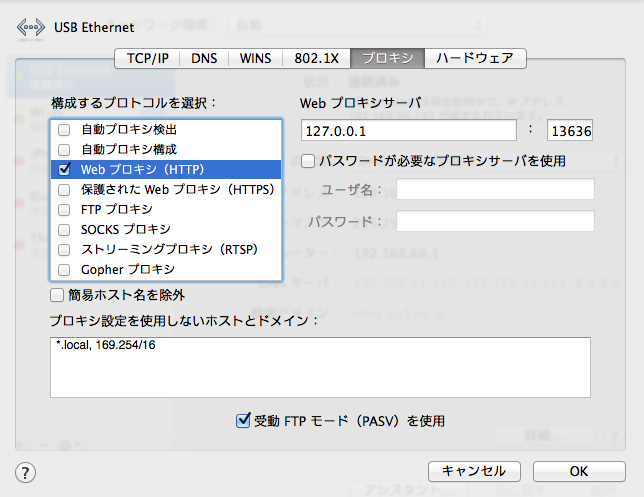
proxyをブラウザに設定
文字コード問題に引っ掛かり、まったくフィルターできない問題
proxyにfilter追加していざ正規表現で書き換えようとしたら、まったく書き換えられませんでした。HTML BODYをみるとこんな文字列が...このあと2時間くらいこの文字列と格闘することに
>p body
\xC4\x85\xC0\xB0\xB0Q\x83\x7Fs\x97=\x98d\x8F_H\x86\x85U\xC9\xF3hH\x1FW,\xA5\x9D\xCAP\xBC*\xD6N\x82$R\xD2N\n\xB9\xCE\x8B\xD7T\xAE\x06\x8B\x89v!\xA8L\x81\x1C\x8D\xA5reY5\x97V\t54\x98\xCA\xEDEj2Y[\xCC\xE6d\x94X\xE72\x9Cs\xC3\xC4!\x19M\x06\xBB2\\\x81\x80\xA7#C|u\xF8~\xF4u\x04n\xDD)\x97\xCA\x92#\x96W^e\xA9\xD6\xBCZu\x93zw\xAA)!\"\xB5\xC0\xA1\x7F\b\x9C\x97\xF0.\xF4\x1C\x91\xFB\xC1\x10\xBF\n6P2t\x9F\x1D\x9D!v\a\x91\xE0\xC9\xF5>vh\x8C\xDF\xD9a\xE7\xE7!\x83Ld\e\x02l\xF4\xCE\v18\xB8\x951n\xE3\xD8\x18
>p body.encode
<Encoding:ASCII-8BIT>
文字コードが問題ではなくgzipだった
結果謎の文字列はHTTP通信がgzip圧縮されたために発生したみたいです。なのでコンテンツの書き換え処理を次の通り変更しました
- HTMLのcontent-encodingにgzipが入っているかチェック
- gzip解凍
- コンテンツの書き換え
- gzip再圧縮(この処理を行わないとブラウザで表示エラー出た)
完成版
hatena_ad_block_proxy.rb
# !/usr/bin/env ruby
IP = '0.0.0.0'
PORT = '13636'
DOC = './'
require 'webrick'
require 'webrick/httpproxy'
handler = Proc.new() {|req,res|
if res['content-type'] != nil and res['content-type'].include?("text/html;")
# gzipなら解凍
if res.header["content-encoding"] == "gzip"
Zlib::GzipReader.wrap( StringIO.new(res.body)) do |gz|
res.body=gz.read
end
end
# filter
res.body.gsub!("ad-banner", "")
res.body.gsub!("ad-head-text", "")
res.body.gsub!("ad-rectangle", "")
res.body.gsub!("toppage-rectangle-top-right", "")
res.body.gsub!("toppage-banner-middle", "")
# gzipに再圧縮
if res.header["content-encoding"] == "gzip"
Zlib::GzipWriter.wrap(io=StringIO.new) do |gz|
gz.write res.body
res.body = io.string
end
end
end
}
opts = {
:BindAddress => IP,
:Port => PORT,
:DocumentRoot => DOC,
:ProxyContentHandler => handler
}
server = WEBrick::HTTPProxyServer.new(opts)
# コマンドラインでCtrl+Cした場合止めるイベントハンドラ
Signal.trap(:INT){ server.shutdown}
# サーバースタート
server.start
広告消えた
開発を振り返って
Webのコンテンツってこんなに簡単に書き換えられるんですねー。ソース読んだら判る通りフィルターが甘々で設定煮詰まっていません。運営は簡単に対策が出来そうです。たぶん有名なWeb広告業者のAD用jsをターゲットに対策していくと良いフィルターが書けるかもしれませんが、私の知識不足で断念。
またメモリにHTML Bodyを全部コピーしてゴリゴリ文字列操作しているのでとっても遅いです。Zero-Copyなストリーミングにすると、速度が大幅に改善できると思います。ストリーミング処理ってこんなところでも使えるんですね。
→wikipedia:Zero-copy
→rubyのC拡張でzero copyなStringを取り回すのは難しい
たぶんこういうところに使えそう
WebAPI通信にproxyを掛けて書き換えるとHPとか攻撃力を書き換え放題です。開発時のデバッグに使えそうですね。ただしサーバ証明書をなんとかしないとHTTPSだと改ざん検知で引っ掛かってしまいます。HTTPにしか使えないと思います。そう考えるとHTTPSって大事ですね。