はじめに
エムスリーAdvent Calendar 2016 最終日はデータ活用の王道、協調フィルタリングによるレコメンドをAmazon EMR上のSparkで実装します。
O'REILLYのSparkによる実践データ解析の第3章を元ネタに音楽の再生時間のデータを元にしたアーティストのレコメンドを実装してみます。
協調フィルタリングって何?という方は、ECサイトの「この商品を買った人はこんな商品も買っています」というのをイメージしてもらえれば分かりやすいと思います。
推薦システムの体系的な解説はこちらのスライドがおすすめです。
情報推薦のやり方には大きく分けて協調フィルタリングと内容ベース/知識ベースフィルタリングがあります。
- 内容ベースフィルタリング:ユーザが好むアイテムの内容に基いて推薦するアイテムを決める
- 知識ベースフィルタリング:ユーザが好むアイテムに関する知識に基いて推薦するアイテムを決める
- 協調フィルタリング: ユーザのアイテムに対する評価や行動履歴を大量に集めて推薦アイテムを決める
つまり、こういうことです。
- 内容ベースフィルタリング: この人味噌ラーメンが好きって言っているから、味噌ラーメンの美味しいお店を紹介しよう
- 知識ベースフィルタリング: この人が好きな味噌ラーメンのお店の店主が、別の場所で醤油ラーメンのお店をオープンさせたらしいので紹介しよう
- 協調フィルタリング: この人がよく行くお店の常連さん達はこのお店によく行ってるみたいだけど、この人はまだ行ったことなさそうだから紹介してみよう
Sparkって何?という方は、大規模なデータを処理するために沢山のコンピュータを集めてうまいこと計算させる仕組みだと思ってもらえればよいかと思います。少し前にMapReduce(Hadoop)という仕組みが出てきたのですが、その進化版として出てきたのがSparkです。詳しくはこちらの解説をご覧ください。
ざっくりとしたイメージをつかむには、選挙の開票なんかを連想してもらうとよいかと思います。
どんなに高速に紙を数えられる人がいたとしても1人ではなかなか終わらないと思います。じゃあ何人かで協力しようとなるのですが、その時闇雲に始めてしまうよりも、まず候補者毎の箱に分けていって、その後で箱毎に数えるとか、一定のルールがあった方がスムーズに作業が進みそうです。
コンピュータの並列分散処理の世界でそういう一定のやり方を提供してくれるのがSparkというわけです。
今回使うデータセットはインターネットストリーミングラジオで、どのユーザがどのアーティストの曲を何回再生したかを記録したもので、ユーザ数は約14万、アーティスト数は約160万、レコード数は約2400万となっています。
協調フィルタリングはユーザのアイテムに対する評価を予測して、予測値の高いものからアイテムを推薦する仕組みです。
Wikipediaで紹介されている以下の図を見ても分かるようにその計算過程では、ユーザ数×アイテム数の2次元の表のような形でデータを表現します。
つまり、今回のデータの場合、14万×160万 = 2千億通りの組み合わせが表現できなくてはなりません。
そこでSparkの出番となるわけです。
Wikipedia - Collaborative filtering

今回はAWS上でHadoop/Sparkクラスタを簡単に構築できるAmazon EMRを使います。
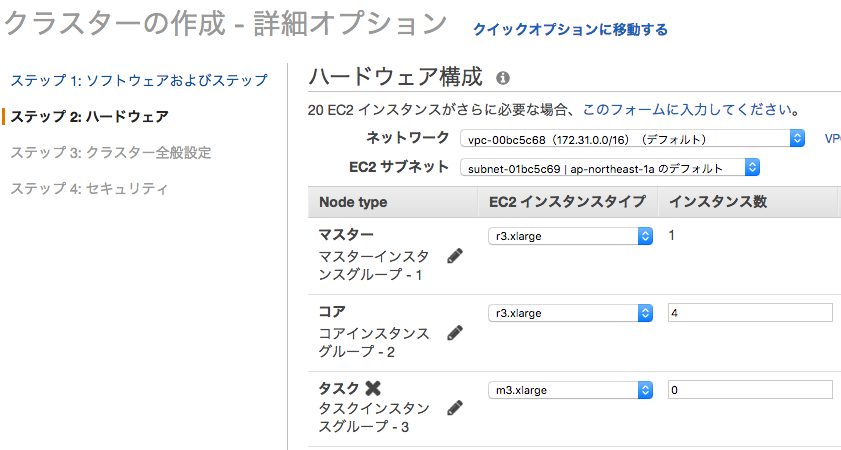
本当はデータ規模に応じてクラスタサイズを見積もるべきだと思いますが、ひとまずマスタ×1台、処理実行ノード×4台の5台からなるクラスタを使おうと思います。
S3に格納されたデータを読み込んで、5台のクラスタでデータの前処理とレコメンドの計算を行い、結果をまたS3に書き戻すという構成です。
実装
さて、前置きが長くなりましたが、ここから実装を進めていきます。
データの準備
今回使うデータはAudioscrobblerが公開しているデータセットでここからダウンロードできます。
データはtar.gzで圧縮されていて以下の3ファイルが入っています。
| ファイル名 | 説明 | サイズ(平文) | サイズ(gz) | 行数 | 項目 | デリミタ |
|---|---|---|---|---|---|---|
| user_artist_data.txt | ユーザのアーティスト毎の再生回数 | 407MB | 101MB | 24,296,858 | user_id(int), artist_id(int), play_count(int) | ' '(スペース) |
| artist_data.txt | アーティストの名前を確認するためのデータ | 53MB | 28MB | 1,848,579 | artist_id(int), artist_name(string) | '\t'(タブ) |
| artist_alias.txt | 同じアーティストに複数のIDが割り当てられてしまっているのを名寄せするためのデータ | 2.8MB | 1.0M | 193,027 | bad_artist_id(int), good_artist_id(int) | '\t'(タブ) |
これらのファイルをS3にそれぞれのディレクトリを作って格納します。
今回はこのような配置で格納しました。
- audioscrobbler
- input
- user_artist_data
- user_artist_data.txt.gz
- artist_data
- artist_data.txt.gz
- artist_alias
- artist_alias.txt.gz
- user_artist_data
- input
クラスタの起動
awsコマンドで起動できるのですが、今回はAWSコンソールからGUIで立ち上げました。
11月にリリースされたばかりのSpark2.0.2が使えるのがすごいですね。
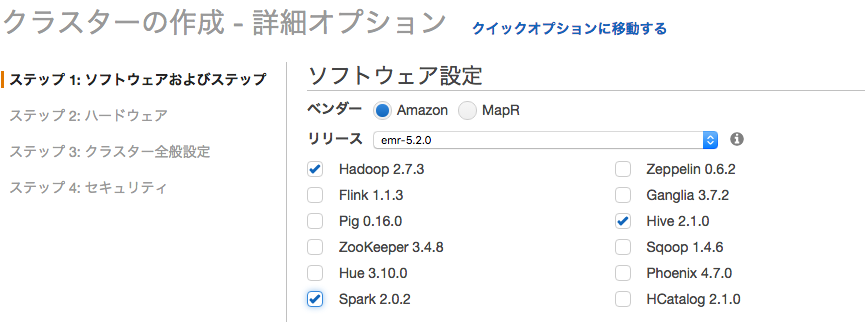
今回はメモリの大きいr3.xlargeを選択して5台構成のクラスタを作りました。
データの前処理
前処理はSQLの方が書きやすいのでHiveで実装します。
S3のファイルをHiveの外部表として読み込んで処理していきます。
-- S3
set fs.s3n.awsAccessKeyId=<access_key_id>;
set fs.s3n.awsSecretAccessKey=<secret_access_key>;
-- default database
create database if not exists audioscrobbler;
use audioscrobbler;
source ./config.sql;
drop table if exists user_artist_data_ext;
create external table user_artist_data_ext (
user_id int,
artist_id int,
play_count int
)
row format delimited
fields terminated by ' '
lines terminated by '\n'
location 's3n://<bucket_name>/audioscrobbler/input/user_artist_data'
;
drop table if exists artist_data_ext;
create external table artist_data_ext (
artist_id int,
artist_name string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
location 's3n://<bucket_name>/audioscrobbler/input/artist_data'
;
drop table if exists artist_alias_ext;
create external table artist_alias_ext (
bad_artist_id int,
good_artist_id int
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
location 's3n://<bucket_name>/audioscrobbler/input/artist_alias'
;
アーティストデータから不明なアーティストを除外した上で、アーティストIDを名寄せします。名寄せしたアーティストIDで集約して再生回数を集計し直します。
source ./config.sql;
drop table if exists artist_data;
create table artist_data
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select
t1.artist_id,
t1.artist_name,
nvl(t2.good_artist_id, t1.artist_id) as correct_artist_id
from
(
select
artist_id, artist_name
from
artist_data_ext
where
artist_id is not null
and artist_name is not null
and artist_name not like '%unknown%'
) t1
left outer join artist_alias_ext t2
on t1.artist_id = t2.bad_artist_id
;
drop table if exists user_artist_data;
create table user_artist_data
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select
t1.user_id,
t2.correct_artist_id as artist_id,
sum(t1.play_count) as play_count
from
user_artist_data_ext t1
inner join artist_data t2
on t1.artist_id = t2.artist_id
group by
t1.user_id, t2.correct_artist_id
;
ユーザ毎に再生回数の値は大きく異なっています。扱いやすくするために再生回数をユーザ毎にスケーリングします(0〜1の範囲の実数に丸めます)。
いったんここまでの前処理の結果を外部表としてS3にも書き戻しておきます。
source ./config.sql;
drop table if exists user_max_play_count;
create table user_max_play_count
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select
user_id,
max(play_count) as max_play_count
from
user_artist_data
group by
user_id
;
drop table if exists user_artist_ratings;
create table user_artist_ratings
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select
t1.user_id,
t1.artist_id,
cast(t1.play_count as double)
/ cast(t2.max_play_count as double) as rating
from
user_artist t1
inner join user_max_play_count t2
on t1.user_id = t2.user_id
;
drop table if exists user_artist_ratings_ext;
create external table user_artist_ratings_ext (
user_id int,
artist_id int,
rating double
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile
location 's3n://<bucket_name>/audioscrobbler/output/user_artist_ratings'
;
insert overwrite table user_artist_ratings_ext
select * from user_artist_ratings
;
レコメンドの計算
レコメンドの計算にはSparkの機械学習ライブラリであるMLlibを使います。
MLlibには協調フィルタリングでレコメンドを計算するためのクラスが実装されています。
ここで実装されているアルゴリズムは非負値行列因子分解と呼ばれるもので、ユーザのアイテムに対する評価値の表を、ユーザ数 × アイテム数の大きな評価値行列とみなし、それをユーザ数 × K と K × アイテム数の2つの小さな行列の積に近似するように分解します(イメージとしては、算数の因数分解のような感じです)。
こうすると何が嬉しいかというと、因子行列の積として表現される近似した評価値行列は、元々の評価値行列よりも密な行列(ゼロの要素が少ない)となることです。その結果、元々の行列ではユーザがまだ評価をつけてなかったアイテムについて、因子行列の積の値を評価値の近似値とみなして、アイテムを推薦することができるようになるのです。
行列因子分解を計算する方法はいくつかあるのですが、SparkのMLlibにはALS(Alternative Least Squares: 交互最小二乗法)というアルゴリズムが実装されています。
今回はこのALSを使ってレコメンドを計算しようと思います。
ALSについては以下のブログの解説が分かりやすいです。
カエルでもわかる!Spark / MLlib でやってみる協調フィルタリング(前編)
それでは実行していきます。
本来はSbtでビルドしてspark-submitで実行するのですが、今回はお手軽にspark-shellから対話的に実行します。基本的な流れは公式ドキュメントのチュートリアルほぼそのままです。
$ spark-shell --num-executors 4 --executor-memory 20G
シェルが起動したら↓の処理をコピペしていきます。
まずファイルのパスやモデルのハイパーパラメータの設定をします。(今回ハイパーパラメータは決め打ち)
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.mllib.recommendation.Rating
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val ratings_input_path = "/user/hive/warehouse/audioscrobbler.db/user_artist_ratings/*"
val model_output_path = "s3n://<bucket_name>/audioscrobbler/output/model/matrix_factorization_model"
val recommends_output_path = "s3n://<bucket_name>/audioscrobbler/output/data/recommendations"
val rank = 10
val iterations = 10
val lambda = 1.0
val alpha = 40.0
Hiveのテーブルを読み込み、ALSの入力形式であるRDD[Rating]の形式に変換します。
val ratings = sqlContext.read.format("orc").load(ratings_input_path).rdd.
map(x => Rating(
x(0).asInstanceOf[Int], x(1).asInstanceOf[Int], x(2).asInstanceOf[Double]
)).cache()
ALSのモデル学習(非負行列因子分解)をします。モデルは再利用できるのでS3に出力しておきます。
val model = ALS.trainImplicit(ratings, rank, iterations, lambda, alpha)
model.save(sc, model_output_path)
モデル評価をしてみます。元の評価値行列と、モデルから予測した行列積でMSE(平均二乗誤差)を計算して標準出力に表示します。
val usersProducts = ratings.map(x => (x.user, x.product))
val predictions = model.predict(usersProducts).
map(x => ((x.user, x.product), x.rating))
val ratesAndPreds = ratings.
map(x => ((x.user, x.product), x.rating)).
join(predictions)
val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("Mean Squared Error = " + MSE)
全ユーザについてのレコメンドを計算します。Spark1.4からこのメソッドが使えるようになっているので試してみます。
val recommendations = model.recommendProductsForUsers(10)
recommendations.map(x => {
val user = x._1
val rec = x._2.map(r => "%d:%.6f".format(r.product, r.rating)).mkString(",")
"%d\t%s".format(user, rec)
}).saveAsTextFile(recommends_output_path)
・・・が、今回は時間がかかりすぎたのでここまで。
EMRの料金も心配なのでクラスタを停止しました。
まとめ
今回はAmazon EMRを使ったレコメンド作成に取り組んでみました。
最終アウトプットを出力させるところまでできませんでしたが、基本的な流れは確認できました。
S3にデータを置いてEMRで必要な時に必要な分だけ計算リソースを確保すれば、リーズナブルにビッグデータ処理を実行できるので大変魅力的だと思います。