Machine Learning Advent Calendar 2015 11日目の記事です。
本記事では、エージェントと強化学習の概念を説明し、簡単なマルチエージェントシステムのモデルを与え、実装例とシミュレーション実験の結果を示します。
概念の説明
エージェント
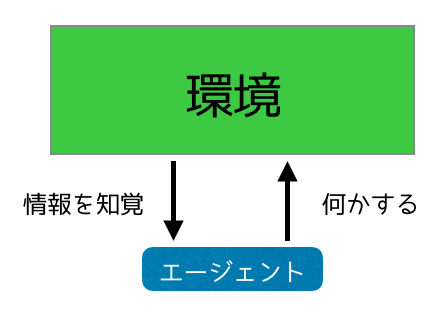
エージェントとは、概念の一つです。周囲から何かを知覚、その情報を元に周囲に対して働きかけるものを全てエージェントと呼びます。我々人間もある意味エージェントと考えることができます。目や耳から情報を受け取って、自身が置かれている環境に対して動作をすることができるからです。お前がエージェントになるんだよ!
マルチエージェントシステム
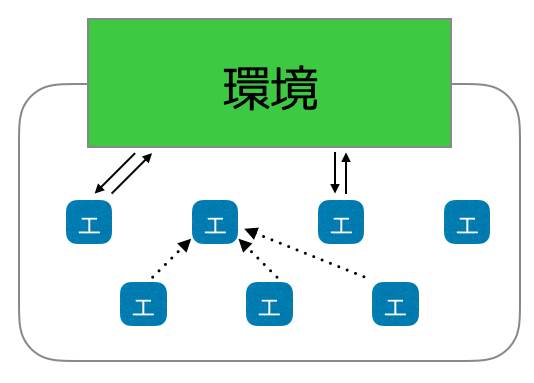
マルチエージェントシステムとは、その名の通り複数のエージェントから成るシステムです。マルチエージェントシステムでは、各エージェントは他のエージェントや環境と通信しながら動作を行います。エージェント同士が協調することで、単一のエージェントでは達成できない事柄をシステム全体として達成できます。このマルチエージェントシステムをコンピュータ上でシミュレーションするものをマルチエージェントシミュレーションと呼びます。
強化学習
強化学習とは、環境に置かれたエージェントが自律的に学習する仕組みです。
エージェントが何か行動を行うと、環境からその結果に対する報酬をもらうとします。この報酬の多寡によって、エージェントが取った行動が強化されます。大雑把にいえば、行動の結果がよければ環境からご褒美がもらえ、悪ければ罰を受けます。ご褒美がもらえた行動は以降行われやすくなり、罰を受けた行動は行われにくくなります。
強化学習におけるエージェントの目的は、環境から貰える報酬を最大化することです。逆に、システム設計者は「環境にとって望ましい結果となった行動」を取ったエージェントに報酬を払う仕組みにすることで、適切な行動を自律的に学習させることができます。
モデルと学習の進み方
今回は、例として 何かしらの存在がタスクを処理するシステム をマルチエージェントシステムでモデル化しました。
環境にはタスクキューが一つあり、そこにタスクが詰まっているとします。タスクの重さは様々で、重いほど処理に時間がかかります。この環境にエージェントを幾つか放ち、彼らにタスクを処理させましょう。個々のエージェントには処理能力が設定されおり、性能のよい物ほどタスクを素早く処理できます。さらに、複数のエージェントが結託するとタスクをより素早く処理できるとします。
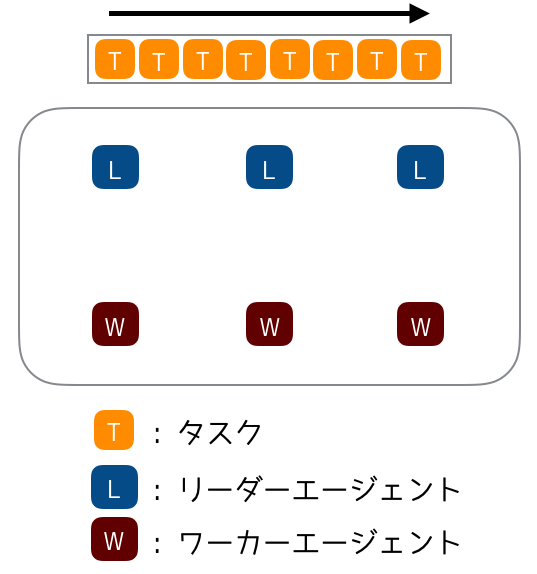
エージェントにはリーダータイプ、ワーカータイプが存在し、以降それぞれリーダーエージェント、ワーカーエージェントと呼びます。リーダーエージェントはワーカーエージェントに対してタスクの処理を呼びかけ、合意が取れたら一緒にタスクをこなします。反応がなかったら、仕方ないので自分でタスクをこなします。一方、ワーカーエージェントは普段は待ち状態ですが、リーダーエージェントからの呼びかけに応えたり応えなかったりします。
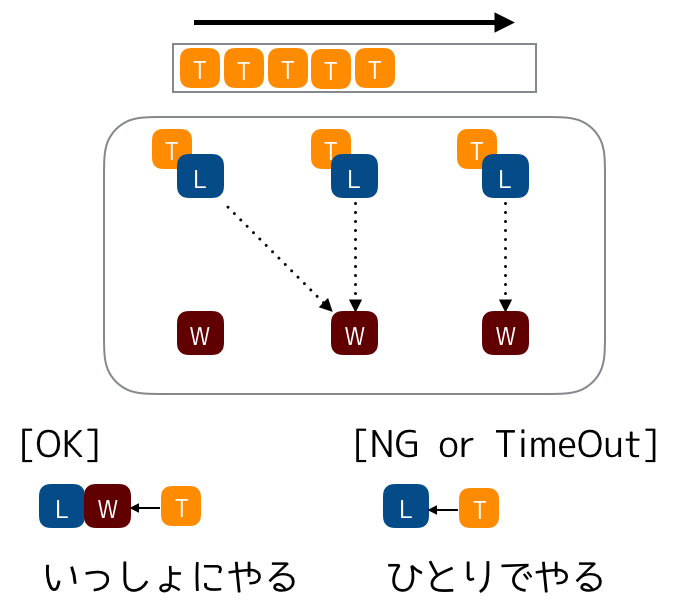
以上の制約で効率よくタスクを処理させてみましょう。なるだけたくさんのリーダーエージェント⇔ワーカーエージェント間でチームが組まれるのが理想です。
実装の詳細
実装の詳細について説明すると長くなってしまうので、本記事ではカットします。もし興味がある方は、github、および補足説明をご覧ください。
実験
仮想空間で実際にタスクとエージェントを生成し、シミュレーションを行いました。
評価値はエージェントがタスク処理に費やした時間の合計とします。
環境の設定は以下のとおりです。
| key | value |
|---|---|
| リーダーエージェント数 | 5 |
| ワーカーエージェント数 | 5 |
| 初期状態でキューに溜まっているタスクの数 | 1000 |
| エージェントの能力値 | リーダーエージェント:1〜5 ワーカーエージェント:1〜5 |
| タスクの難易度 | 1〜10の一様ランダム |
実験の結果、学習が進むとチームを組むリーダーエージェントとワーカーエージェントの組が自然に発生し(誰々とチームを組めとこちらは指定してないのに!)、学習をさせない状態よりも効率よくタスクを処理できました。
| 学習 | タスク処理に費やした時間(ms) |
|---|---|
| なし | 45634 |
| あり | 37077 |
まとめ
簡単なマルチエージェントシステムのモデルを考え、実装とシミュレーション実験を行いました。モデルは単純なものですが、叩き台としては調度良いのではないでしょうか。
発展形として、タスクに複数タイプの難易度があり、あるタイプが得意なエージェント/苦手なエージェントが存在する設定が考えられます。その場合はエージェントに与える報酬をどのように設定してやると上手くチームが組めるか考えてみましょう。面白そうですね!
余談ですが、なぜGoを使ったのか?それは、Goの並行処理の仕組みはマルチエージェントシステムのシミュレーションを実装するのにぴったりなのではないかと考えたためです(なお、思ったほど簡単にはならなかった模様)また、この記事が Go Advent Calendar との同時投稿を狙っていた名残でもあります。急遽用意したGo単独の記事は ここ から読めます。
12日目の Machine Learning Advent Calendar 2015 は、dr_paradi さんです。乞うご期待。