https://cloud.google.com/bigquery/release-notes#08252015 の速報。
詳細は後日追記予定。
UDFs(user-defined functions) のサポート
多分、今回の目玉機能。JavaScript でユーザ定義関数(UDFs)が書けるようになりました。
これは機能がデカイので、別エントリーで。
https://cloud.google.com/bigquery/user-defined-functions
http://googledevelopers.blogspot.jp/2015/08/breaking-sql-barrier-google-bigquery.html
サンプルで雰囲気を感じ取ってください。
こんな感じで JavaScript で関数を定義、登録して、
// The UDF
function urlDecode(row, emit) {
emit({title: decodeHelper(row.title),
requests: row.num_requests});
}
// Helper function for error handling
function decodeHelper(s) {
try {
return decodeURI(s);
} catch (ex) {
return s;
}
}
// UDF registration
bigquery.defineFunction(
'urlDecode', // Name used to call the function from SQL
['title', 'num_requests'], // Input column names
// JSON representation of the output schema
[{name: 'title', type: 'string'},
{name: 'requests', type: 'integer'}],
urlDecode // The function reference
);
こういう感じで呼び出せます。
SELECT requests, title
FROM
urlDecode(
SELECT
title, sum(requests) AS num_requests
FROM
[fh-bigquery:wikipedia.pagecounts_201504]
WHERE language = 'fr'
GROUP EACH BY title
)
WHERE title LIKE '%ç%'
ORDER BY requests DESC
LIMIT 100
GCS上の JSON/CSV に対してクエリを発行できるようになった
federated data sources という機能で、GCS上の JSON/CSV に対して直接クエリを発行できるようになりました。素晴らしい!注意事項とかあるので、後で追記します。
Web UI からは Table type で External table を選択し、
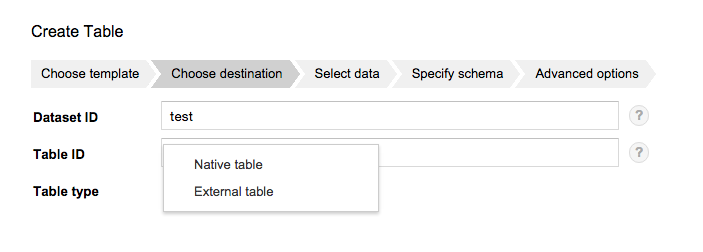
Load data from で Google Cloud Storage の path を指定すれば OK
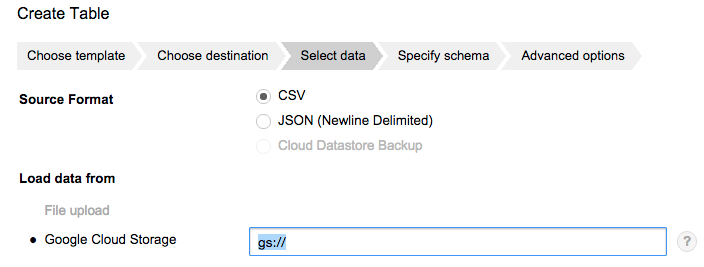
Load を待たずにそのままクエリが書けます。
※ 試してみたけど、圧縮した JSON はダメっぽい(サンプル数が少ないので要検証)
Job がキャンセルできるようになった
Job cancel API が追加されました。
でかいジョブを間違えて投入しても、安心ですね。
JOIN/GROUP BY 時に EACH が不要に
ついに JOIN の 8MB 制限がなくなり、独自の EACH キーワードを付けなくても、大きなテーブル同士の JOIN / GROUP_BY ができるようになりました。SQLとの互換性が上がりますね。EACH キーワードは deprecated になるようです。
(追記)まだ適用されていない環境もある模様です。もう少し待ちましょう。
価格体系の変更
BigQuery Slots
マルチテナントに特有の他の人が重いクエリを投げた時に影響をうけてスローダウンするのを少なくしてくれるオプション契約。内部的にサーバが分けられているのか、優先度制御なのかは不明。
詳細は営業に問い合わせてね、となっているので値段もよくわからないが、
日次バッチとかたまに突き抜けてツライ、とか言う方は検討してみても良いのでは?
Query pricing tiers (クエリ課金の体系の変更)
2016年1月1日からクエリ課金の体系が変わります。
具体的には今まで一律で $5/TB だったのが、利用する CPU リソースに応じて、$5/$10/$20 のいずれかの Tier に振り分けられます。
なので、クエリ料金の計算が以下のようになります。
$5 * (Tier1 のクエリスキャン量)
+ $10 * (High Compute Tier 2 のクエリスキャン量)
+ $20 * (High Compute Tier 3 のクエリスキャン量)
Tier の切り替えの基準が明確でないのはちょっとコスト計算で悩みどころ。基本的には値上げになると思うので、CPUぶん回してると思わしきクエリはチェックしておきましょう。
For example, queries that contain a very large number of JOIN or CROSS JOIN clauses, or complex user-defined functions (UDFs) with large processing requirements.
一応、Opt-out もできるようですが、High Compute Tier 2/3 になるクエリが実行できなくなるようなので、それはそれで困りそう。
You can opt out of the High Compute Tiers by contacting support or your local sales rep. After opting out, a resourcesExceeded error return when running an applicable query.
Quota 上限の緩和
- 並列クエリの実行可能数が 20 から 50クエリに緩和
- 1日に実行できるクエリ数の上限が 10万クエリに緩和(たしか、今までは1万だった)
Web UI の機能追加
- UDFs サポート
-
Format Queryボタンの追加(昔からあったような・・・) - DATE_RANGE_QUERY でサポートしてる suffix を持つテーブルが、まとめて表示されるように。
users_20150801,users_20150802, .... という感じのテーブル群が以下のようにまとまります。

Table ごとに Streaming Insert の統計情報が API 経由で確認できるようになった
"streamingBuffer": {
"estimatedRows": unsigned long,
"estimatedBytes": unsigned long,
"oldestEntryTime": unsigned long
}
それぞれ以下の意味です。(翻訳が怪しいので、原文と併記しておきます)
- estimatedBytes
- A lower-bound estimate of the number of bytes currently in the streaming buffer.
- streaming buffer に入っている推定バイト数
- estimatedRows
- A lower-bound estimate of the number of rows currently in the streaming buffer.
- streaming buffer に入っている推定行数
- oldestEntryTime
- Contains the timestamp of the oldest entry in the streaming buffer, in milliseconds since the epoch, if the streaming buffer is available.
- streaming buffer に入っている一番古い行のタイムスタンプ