4/16 に Google Cloud Platform Blog にて Cloud Dataflow の Public Beta の開始と共に、BigQuery の各種アップデートが発表されました。
リリースノートも久々に更新されています。
しかし、ここに書いてある事以外にも色々と変更点が発見されていますが、情報が散在しているため、変更点をまとめてみました。まだ、漏れがあるかもしれないので、ご指摘をお待ちしております。
(4/18追記)4/17 に公式 Blog でもまとめ記事が出ました。確認中です。
アップデート内容一覧
- Streaming Insert の制限の緩和
- Streaming Insert の値段の変更
- Batch Insert (Load) の制限の緩和
- Google Cloud Datastore データのロードに対応
- API リクエスト数制限の緩和
- クエリの追加(ドキュメント追加のみを含む)
- Table decorator による削除済みテーブルのデータの復元
- 行レベルのパーミッション
- EU リージョン提供開始
Streaming Insert の制限の緩和
「リクエストあたりの最大行数」だけが据え置きであとはほぼ10倍になってます。
申請なしに10万行/秒までデータが挿入できるのは嬉しいですね。
| 制限項目 | 旧 | 新 |
|---|---|---|
| 1行あたりのデータの最大サイズ | 20KB | 1MB |
| リクエストあたりの最大サイズ | 1MB | 10MB |
| リクエストあたりの最大行数 | 500行 | 500行 |
| 1秒あたりに挿入できる最大行数/テーブル | 1万行(申請により10万行) | 10万行 |
| 1秒あたりの最大データサイズ | 10MB | 100MB |
過去のデータはちょっと覚えていなかったので、以下のエントリから引用させてもらいました。
Streaming Insert の値段の変更
7/20から行数ベースの課金から、容量ベースの課金に変わります。
10万行で$0.01(約1.2円)だったのが、200MBで $0.01 になります。
1行あたりのデータ量が 2KB 以下の人は安くなる計算です。
Streaming Inserts $0.01 per 100,000 rows until July 20,
2015. After July 20, 2015, $0.01 per 200 MB.
Batch Insert (Load) の制限の緩和
圧縮時、非圧縮時ともにロード可能なデータ数が大幅に増えています。
大規模データ投入時にファイルを分割する手間を減らすことができるのではないでしょうか。
| ファイルタイプ | 旧 | 新 |
|---|---|---|
| CSV 圧縮あり | 1GB | 4GB |
| CSV 圧縮なし(データに改行含む) | 1GB | 4GB |
| CSV 圧縮なし | 1TB | 5TB |
| JSON 圧縮あり | 1GB | 4GB |
| JSON 圧縮なし | 1TB | 5TB |
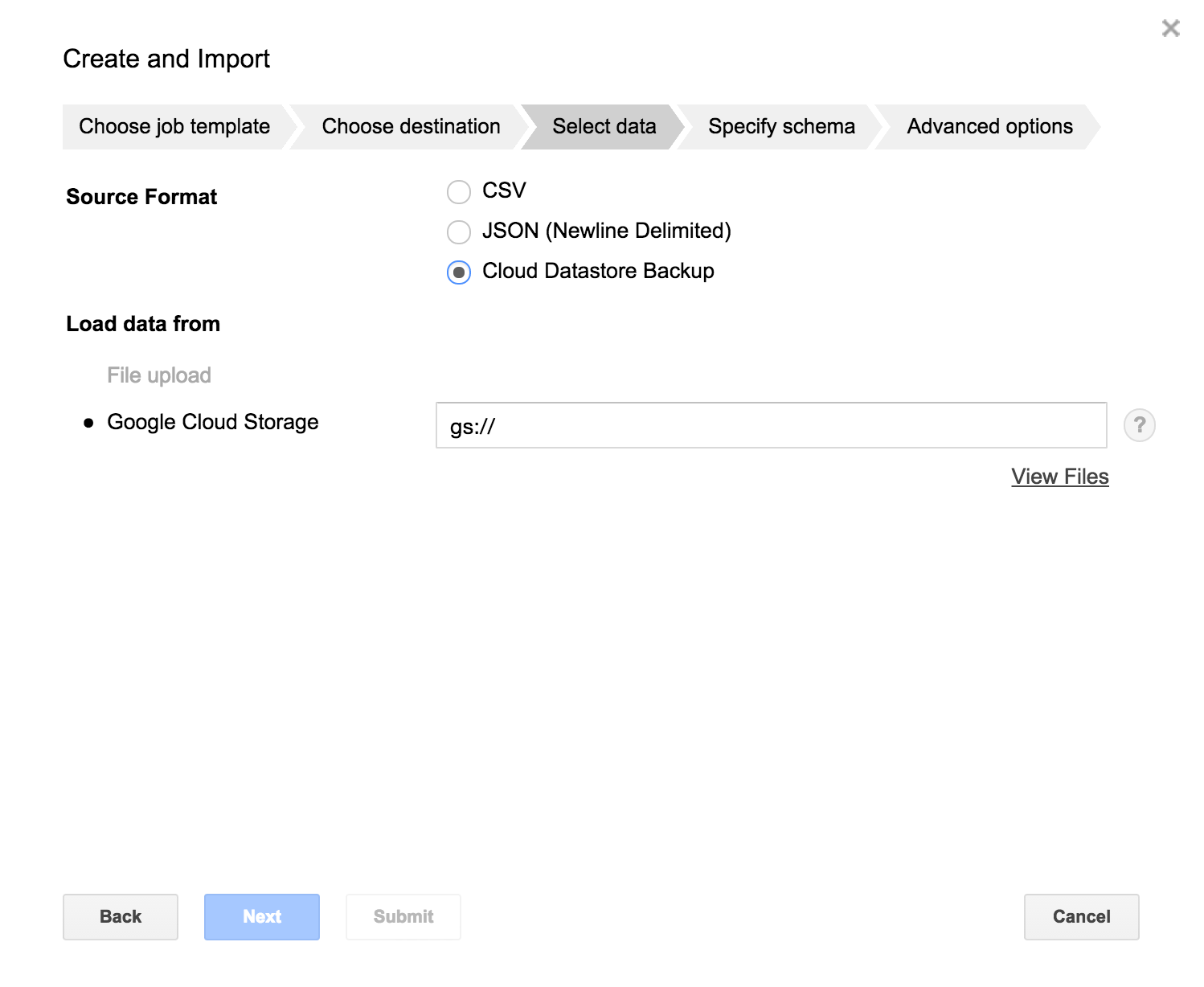
Google Cloud Datastore データのロードに対応
Datastore は使ってないので詳細はわからないのですが、
BigQuery supports loading data from Google Cloud Datastore backups
とのことで、GCSにエクスポートしたバックアップデータから。パーミッションの設定やデータ型の変換を指定してインポートできるようです。以下のスクリーンショットのように WebUI に項目が増えてました。
API リクエスト数制限の緩和
ここも10倍ですね。
| 制限項目 | 旧 | 新 |
|---|---|---|
| 1ユーザあたりのAPIコール数制限 | 10回/秒 | 100回/秒 |
クエリの追加(ドキュメント追加のみを含む)
- COALESCE 関数の追加
- GROUP_CONCAT_UNQUOTED 関数の追加
- RIGHT OUTER JOIN と FULL OUTER JOIN 構文の追加(現在ドキュメントなし)
- ROLLUP と GROUPING 修飾子の追加(現在ドキュメントなし)
追加された構文についてはドキュメントがないので、詳細はドキュメントが追加されるまで待ちましょう。JOIN は SQL と同じだと思いますが、ROLLUP, GROUPING は Oracle とかにある ROLLUP とか GROUPING と同じなんでしょうかね。
Table decorator による削除済みテーブルのデータの復元
Table decorator と copy コマンドを併用することで、2日以内なら消してしまったテーブルのデータを復元することができるようになりました。これでテーブルを間違って消してしまったという悲劇からもおさらばです。
こんな感じで、復元したいテーブルが存在していた時間の UnixTime を指定して、別名のテーブルにコピーすることで復元できます。
bq cp mydataset.mytable@1418864998000 mydataset.newtable
行レベルのパーミッション
これできると書いてあるのですが、ドキュメントをみつけることができませんでした。引き続き調査します。文面だけ見ると、
the introduction of row-level permissions makes data sharing even easier and more flexible
とあるので、行単位でデータの公開/非公開の権限を設定できるようです。インサート時に指定するのかな?
追記 (2015.4/28)
Jordan さんが Stackoverflow で解説していました。なかなか難しいですね。
Authorized View を作る。
http://stackoverflow.com/questions/29682618/how-do-i-use-row-level-permissions-in-bigquery
その際、ユーザを絞るための列を追加した、CURRENT_USER() とかパーミッションテーブルとかで絞る。
http://stackoverflow.com/questions/29683423/how-do-i-give-different-users-access-to-different-rows-without-creating-separate
EU リージョン提供開始
EUリージョンを提供しているようですが、
BigQuery now offers the option to store your data in Google Cloud Platform European zones. You can contact Google technical support today to use this option.
とあるので、申請すれば使えるようになるということのようです。日本や米国にサーバがある場合はあまり使うメリットはないですが、EUリージョンを使っている人は検討しても良いのではないでしょうか。