3行でまとめ
- 1つの列に JSON 文字列を突っ込む
- JSON functions を使って、必要な値を取り出す
- 要するに RDB の JSON 型みたいな感じで運用しようということ。
どういう時に使うの?
「1時間後からログ分析するから」とぶっこまれた時。当然、スキーマは決まっていない。あとは、使い捨てのアドホックな分析とか簡易ETLツールとして使うと便利だと思う。
なお、この方法はコストもかかるし、速くもない、実際は BigQuery なので速いけど、相対的には速くないので、甘えずにスキーマはちゃんと決めるようにしよう。
手順
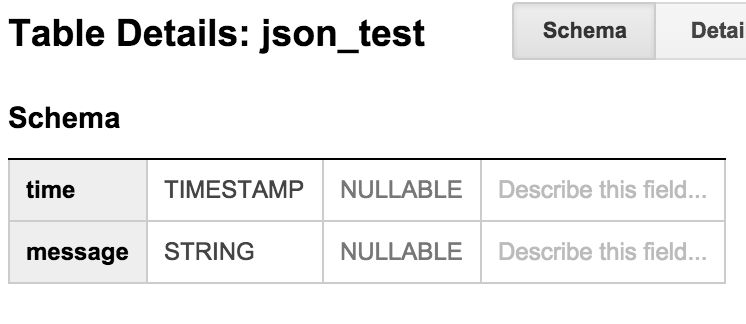
スキーマを準備
$ bq mk test.json_test time:timestamp.message:string
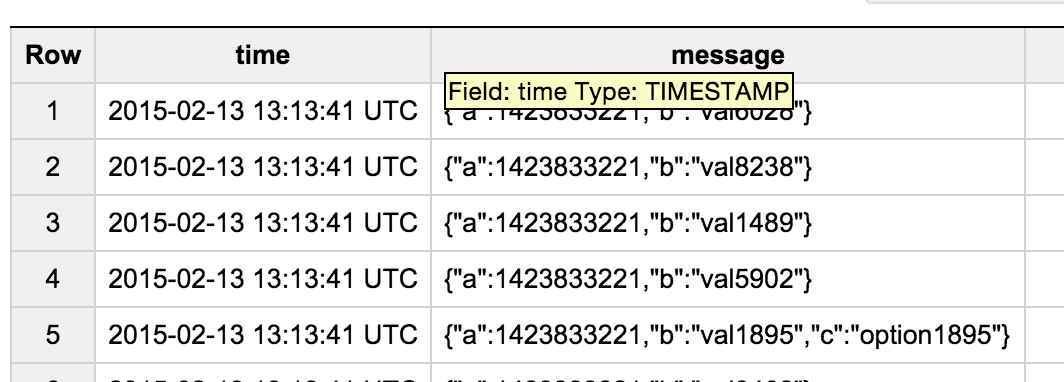
データを投入
こんな感じで、message 列に JSON を投入。データ投入スクリプトは記事の最後を参照。
JSON functions を使って JSON を展開する
JSON functions は JSON path が使えるので、柔軟に展開できる。
書式は JSON_EXTRACT_SCALAR(json, json_path)
SELECT
time,
message,
JSON_EXTRACT_SCALAR(message, "$.a") AS a,
JSON_EXTRACT_SCALAR(message, "$.b") AS b,
JSON_EXTRACT_SCALAR(message, "$.c") AS c
FROM
[test.json_test]
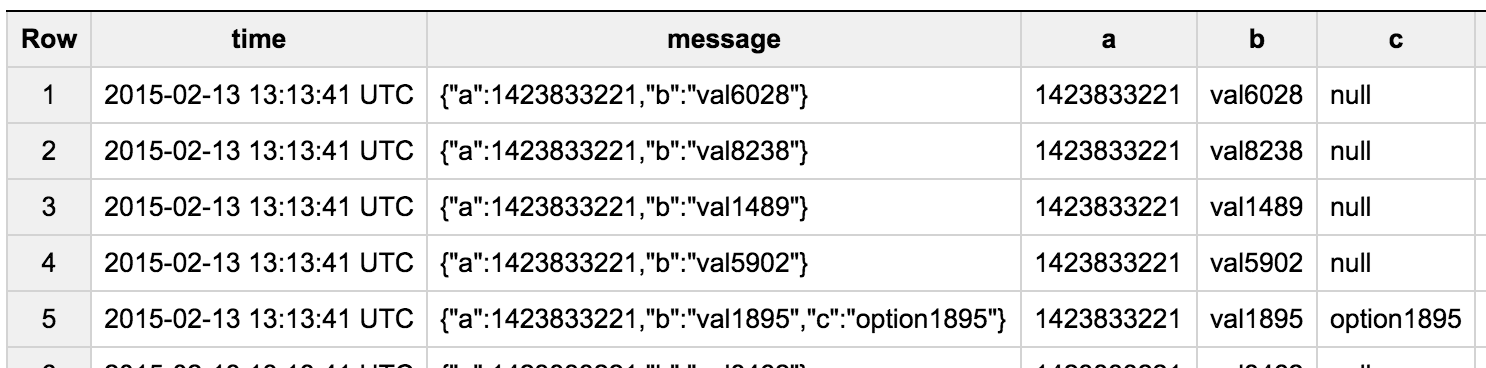
無事に展開できてますね。本格的に分析したくなってきたら、スキーマを決めて、それに合わせて展開したクエリ結果をテーブルに保存するだけでOK。簡易ETLツールとしても使えますね。
実験に使ったソース
ダミーデータ生成
generate.js
for (var i = 0; i < 10000; ++i) {
var t = Math.ceil(Date.now() / 1000);
var obj = {
a: t,
b: "val" + i
}
if (i % 5 == 0) {
obj.c = "option" + i
}
var log = { time: t, message: JSON.stringify(obj) };
console.log(JSON.stringify(log));
}
ロード用スクリプト
load.sh
# !/bin/bash -e
TABLE=test.json_test
INPUT_FILE=input.json
node generate.js > $INPUT_FILE
bq rm $TABLE
sleep 5s
bq mk $TABLE time:timestamp,message:string
bq insert $TABLE $INPUT_FILE