Abstract
計算機科学研究での記録のとり方 を書いてから半年ほど過ぎて、さらに知見がたまったので書き直します。情報系研究者が、紙ベース以外で研究ノートを取る場合に何をすれば良いか とにかく効率よく研究するにはどうするか をいくつかまとめました。改善案があればコメント希望、自分も研究効率をあげたいので教えてほしいですね。半年ぐらい経ったらたぶんまた書き直すと思います。
Introduction
本記事は、締め切りの明確に定まっている文章(上位国際学会論文、国際学会論文のrebuttal(反論)データ、学位論文)のための実験を円滑柔軟に行う上での効果的なノウハウを提案する。この内容は、筆者のいる研究室でのゼミ内容を幾分反映してはいるが、それだけにはとどまらない。内容はいくつかの段階に分けられる。
- 実装段階での工夫
- 実験デザイン段階の工夫
- 実験実行段階での工夫
Preliminaries
- 研究Advisor(教授,上司)あるいは共同研究者との密な連絡は、研究の効率を上げるのにとても重要。なにか大きな進歩があり次第skypeなどでチャット・報告が望ましい。Advisorはそれまでの研究経験と知識の量において生徒を大幅に上回っている。
- 第三者の意見があること自体に意味がある。必要な仕事、つまり実験&実装&執筆を同時並行でしていると、そればかりに頭が行ってしまい、一人では大局的な判断をし辛くなる。それに、真面目に協力してくれる人間なんて共著者しか居ない。
- (追記) ターゲットとなる deadline に対して、最後の1ヶ月は論文執筆だけで良いようにする。なるべく実験はしなくていいように。逆算して、実装は一ヶ月前時点でほぼ完成・バグ取りが終了していないといけない。実験・実装は、個人の能力・時間的余裕によるが、多めに見積もって一ヶ月ずつぐらいかかるだろう。すると、アイディアは三ヶ月前に固めなくてはいけない。アイディアは上司の方が豊富なので、なければ相談する。
- (追記) 卒業駆動開発(例:修論ベース)をすると、始めの1年間は確実に仕事をしない(Ariely and Wertenbroch, 2002)。忘れがちだが20代は短い。もう半分過ぎちゃった。若いうちに実績を積まなくては死ぬ。ので、査読つき海外論文投稿を第一目的とする学会駆動開発にしよう。一年に何度もチャンスがあるから。修論は適当に日本語訳して出せばおk
実装段階での工夫
実装プログラムをバージョン管理できていることを前提とする。(以下「バージョン管理」を「git」と略記しますが許してね。) 実装のアイディア自体は既に十分吟味されているものとする。単体テストや統合テストを書くのも前提とする。その他ソフトウェア工学の知見はだいたい役に立つ。
プログラムはモジュラーに、より多彩なコンフィギュレーションを行えるように制作する。これは、論文を提出した後に求められる追加実験に対応するため。論文査読者は論文をきちんと読まないことも多い。腹はたつが、査読者は「お客様」投稿者は「店員」なので、理不尽な要求に多少耐えられる程度の柔軟性をプログラムに与えておく。
コマンドラインオプションは「機能をオンにする」 フラグを書き、「機能をオフにする」フラグは書かない。デフォルトで全てオンだと、実験の際に、どの機能が性能向上に寄与しているのか全くわからなくなる。論文のストーリー的にも、何か核心となる機能以外は全てオフの結果をまず出したほうが望ましい。学会論文では「性能がいい」だけでも通ることがある(自分の傾向..)が、論文誌では「なぜ性能がいいか」を見せなくてはいけない。
プログラムの途中経過はなるべく多く出力する。生成した中間構造の内容すべて。これも、rebuttalで実験せずとも提示できるデータを多くするため。通常、学会論文の反論期間は、査読文が読めるようになってから反論を返すまで3-4日の猶予しかない。この期間に行う実験の量はできるだけ少ないほうがよい。
クリーンな、読みやすい、正しい実装と、性能重視の黒魔術を使った実装を両方作る。早くても正しくないアルゴリズムは論文に使えない。まずクリーンな実装でバグをなくし、続いて性能を追求しよう。(cf. iterative development)
忘れがちだが、プログラムのバージョン・ビルド日時をログに出力する。入出力ファイル名もプリントする(間違えて別のファイルを入力しているというボンミスは多い)。あるいは、実験スクリプトでバイナリのmd5ハッシュを記録。
出力ファイル名に、実験設定をすべて記載しよう。なるべく、中を見ずとも概要が把握できるようにする。略称をある程度用いることは許容されるが、一貫していなくてはならない。
実験デザインでの工夫
自分の現在の分野・現在の実証内容に対して、一つの実験インスタンスのパラメータが何次元なのか考える。そしてこれを2+1次元まで落とす。
- 二次元以上は人間が視覚的に効率よく管理できない。
- どちらにせよ論文に載せられるのは二次元プロットまで。(やりようはあるが...)
- パラメータの例:コンフィグ1,コンフィグ2,データセット,メモリ制限,時間制限 ...
次元を落とすには、データベース設計の知識(正規化など)を応用すればいい。例:
- ある次元を別の実験セットとする。(例:一つのインスタンス内ではメモリ・時間は統一。実質的に3次元目)
- カテゴリ内を無視する。(例:一つのドメイン内の問題インスタンスらは、後に合計・平均をとるから無視)
- カテゴリ内を直積としてアンロールする。(例:100/200秒と1000/2000MBのメモリ設定の組み合わせを
<100,1000>,<200,1000>,<100,2000>,<200,2000>の4つにする)
実験~論文執筆での工夫
修羅場で命運を分けるノウハウ
進捗管理
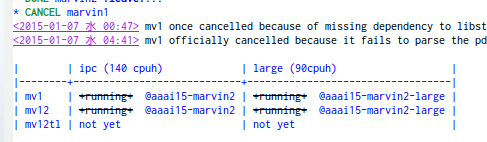
論文を書きながら裏で実験を走らせていると、書いているうちに何の実験をしていたか忘れてしまうので、進捗管理する。管理には excel を使ってもいいし、 Org-mode や markdown などに付いている表管理機能でも良い。Redmine自分で立ててる人はそれでもいいが、効果的なUIがあるか微妙。
実験セットx1次元目x2次元目 に落としたものを、表の形で管理。一つの表が実験セット、横が一時限目、縦が二次元目。
ひとつのセルには、どのフォルダで実験しているのか、想定される計算時間、実験の進行状況など、好きなことを書き入れる。いつ実験開始したのか、何時頃終わりそうかも書く。理由があって中断したら(torque qhold etc.)それも書いておく。
例: (org-mode)
git-auto-commit-mode
実験スクリプトや進捗管理表などは、セーブのたびに自動コミット+自動push。締め切り間近は、いちいち手で管理しているような時間がない。ついでに、同期のし忘れ問題も避けられる。それに、なるべく細かくログが残っていたほうが、実験ノートとして有効だと思う。
バグつぶし
フルの実験を行う前に、ファイル読み込み段階のバグなどを検知するため、5分の実験をまず行う。それがパスしたら10分,20分と2倍ごとに増やす。すると、最後の本番実験は実験全体の時間の半分以下になる。高負荷・大規模実験でしか出てこないバグもあるが、短い実験でそれより早期に発見できるバグもある。
サイズの小さな問題インスタンスに絞って実験を行う。テストはより広い問題ドメインに対して行い、時にRandom-pick testing を行う。
実験スクリプト
TODO qsubやその他のツールを用いて実験する場合、ジョブを投げる実験スクリプトに、実験開始時刻と予想終了時刻を自動記録する機能をつける。自分でメモする習慣を付けても良い。(しかし、こういうのは人間の仕事ではない)
TODO 実験スクリプトを書く上で、ジョブを投げるときに自動でエディタが開かれて入力できるようにしよう。git commit で -m を忘れると怒られることに対応。
DONE 実験結果をワンコマンドで圧縮+共有フォルダへ転送するスクリプトを作る。アーカイブ名には実験設定が明記されるようにする。このアーカイブはむやみに削除しない。バグ/incompatble changesがあっても論文に使える結果もある。論文締め切り間近など、実験の時間が制限されている時には大変重要。例:
- postprocessingのみにバグがある場合。preprocessingの時間計測は正確だから使えるはず。
- バージョン違いでログ形式だけ異なるが、出力データの中身自体は正しい場合。
転送・圧縮・データ集計スクリプトにはファイル名でフィルタを簡単にかけられるようにしておく。一部のデータを更新したいだけなのにデータ全体で実行し直すのは筋が悪い。
Makefileは使いこなす。いろんな結果が最新版であることを担保したい
実験スクリプトと問題データセットは別のリポジトリで管理しよう。本来別のものであるから。例えば、git submodule で 問題データセットリポジトリがスクリプトリポジトリに依存しているようなデザインは良くない。というかgit submoduleは使うな。
沢山書いた実験関連スクリプトを$PATHに追加するようなスクリプトを書いておく。(world.shと名づけている) タイプ数が減る
データの同期
自宅と実験サーバーなどを、DropboxやNFSなど なるべく最小限のアクションで同期出来るようにしよう。徹夜で溶けた脳でも、コマンド一つで同期されるようにしておけば大丈夫。同期先はなるべく多く。これはHDDが死んだ場合のバックアップ。ただし、Dropboxは一箇所で削除されると全ての場所で削除されるので注意。
Bittorrent sync も一つの手段であるかもしれない。巨大なデータに対してはDropboxは有効ではない。Bittorrent sync はサーバーを使用しないP2Pベース、かつネットワーク大域を有効に使うので、期待できる。rsyncとcronでうんにゃらするのは時間ラグがあるので嬉しくない。大学内ネットワークではbtsyncは使えない(特に東工大)。
その他
- エラーがあったら単体テストをメインのプログラムに追加することを忘れない。
- 全実験結果に対して、結果の正しさの検証ができるスクリプトを用意しておく。
- 実験結果が巨大な場合でも、Git Large File Storage があれば気にせずコミットできるらしい。
終わりに
自分の Advisor の Ph.D Advisorの言:
"Your computer should always be running experiments, since there's no reason that you should be working harder than your computer... On the other hand, just because your computer is running, it doesn't mean that actual progress is being made on the research, if your code/scripts have bugs!"